
StarRocks 技术内幕 | 基于全局字典的极速字符串查询
本文发表于: &{ new Date(1659715200000).toLocaleDateString() }
在数据库和存储系统中,String 类型数据广泛存在。为了提升 String 的处理效率和节省存储资源,出现了很多针对 String 类型进行优化的技术手段,例如提升处理效率的各类字典应用,提升存储效率的字典编码压缩技术。
本文主要针对 StarRocks 基于全局字典做的低基数 String 查询优化,揭秘其技术内幕。
#01 为什么要引入低基数字典优化
我们先看下两个 SQL 的对比,表 Lineorder 是 SSB100G 数据集,lo_shippriority 为低基数 int 列,l_shipmode 为低基数 String 列
mysql> select count(cnt) from ( select count(*) cnt from lineorder group by lo_shippriority) tb;
+------------+
| count(cnt) |
+------------+
| 1 |
+------------+
1 row in set (3.51 sec)
mysql> select count(cnt) from ( select count(*) cnt from lineorder group by lo_shipmode) tb;
+------------+
| count(cnt) |
+------------+
| 7 |
+------------+
1 row in set (9.33 sec)可以看到,处理相同数据量的情况下,String 类型的处理时间差不多是 int 类型的 3 倍。
如果能使用整数类型来替代 String 类型进行数据处理,能够显著提升系统的性能!
对于利用整型替代字符串进行处理,通常是使用字典编码进行优化。一个 SQL 从输入到输出结果,往往会经过这几个步骤,几乎每一个阶段都可以使用字典优化:Scan,Filter,Agg,Join,Shuffle,Sort。
以 Filter 和 Agg 为例:
- Filter (过滤操作)
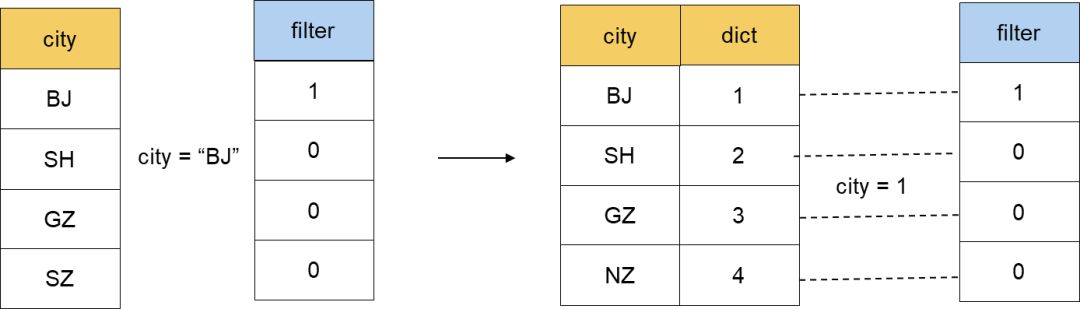
对于 Filter 阶段来说,如果某一个列是用字典编码的,我们就可以直接使用编码之后的整数进行比较,而不是直接用 String 进行比较操作。大多数情况下,整数之间的 Compare 性能会高于字符串之间的性能。
- Agg (聚合操作)
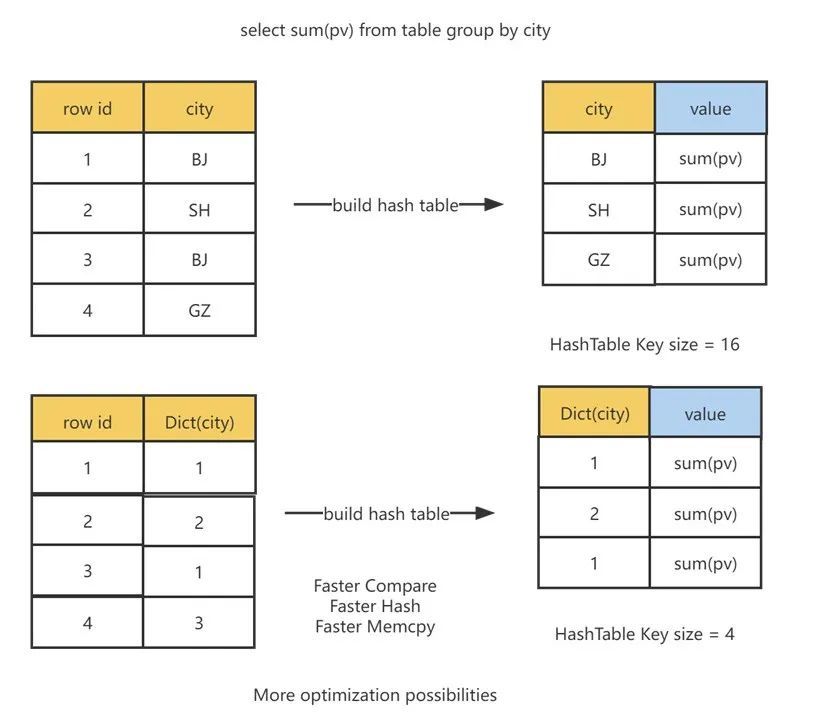
对于 Agg 操作,如果使用了字典编码,我们在聚合中可以使用编码之后的值作为聚合的 Key。如此一来,在聚合操作的 Hash 表构建和查找过程中,可以减少 Hash 表中 Key 的比较代价,同时也能够加快 Hash 值计算,节省内存空间,可以提升聚合操作的速度。
因此如果我们使用字典的编码方式把字符串转变成整型,在 SQL 执行的很多阶段,都可以起到正向加速的效果。
使用整型来替代 String 类型进行加速计算,业界通常使用的手段是使用字典优化。但是对于一个复杂系统来说,想要充分利用字典优化,并不是一件容易的事情。
#02 为什么需要全局字典
在一个分布式执行引擎中,一个 SQL 的执行过程是复杂的。一个查询会存在多个执行阶段,可能会涉及到多个机器多个任务之间的数据交换。如果想充分利用字典优化,那么需要考虑很多的情况:
- 在执行过程中,字典要保证全局性。也就是说在不同的节点之间同样需要维护一个字典。字典数据始终贯穿 SQL 执行的整个生命周期,如果不是全局字典,那么加速只能在局部进行。例如如果两个执行节点的字典编码不一致,那么在网络传输过程中需要同时把字典传给对端机器,或者是需要提前把字典码转为字符串再通过网络发送。如果能保证一个字典的全局性,在网络传输中就可以直接使用字典码而不再需要传输字典。
- 查询规划器规划出使用全局字典最高效的方式,如果一个 SQL 在执行过程中没有网络 Shuffle,也不存在潜在应用字典优化的操作,那么不再采用字典优化。例如`insert into t1 select * from t2;` 这样的 SQL,中间既不存在数据网络 Shuffle,也不存在可能会应用到低基数优化的算子。那么这样的 SQL 就不适合使用低基数优化。
对于一个复杂的、支持实时数据更新的分布式数据库,做到以上两点,并不容易。所以很多的分布式系统,只是用了字典来做局部加速,并没有做全局加速。
#03 如何高效构建全局字典
为了充分利用字典加速,首先需要解决的问题就是全局字典构建和维护问题。
1.通常的分布式字典构建方式
对于很多系统来说,通常构建全局字典的方式有两种:
1. 用户指定 Schema,用户在建表的时候,指定对应的列为低基数列
因为用户指定了低基数,那么可以在数据导入的时候,构建全局字典,因为知道了基数范围,全局字典很好维护,按着特定的规则去生成就好了,存储的代价也不高。
但是这么做,主要存在的问题在于:
- 对用户不友好,需要用户指定 Schema,当基数存在变化,比如基数变高后,不方便维护
- 无法提升已经运行的系统的性能,必须得重建表并且重新导入数据后才能使用。
2. 导入时候构建全局字典
导入数据时,通过中心节点维护全局字典。每次遇到新的的字符都要通过中心节点创建一个新的字典码。但是这么做的主要问题是中心节点很容易会成为瓶颈。另外中心节点因为需要同时处理维护并发控制。
因为维护和构建字典对于很多系统来说都是一个比较困难的事情,因此很多系统,只是在局部使用了局部字典来进行加速,并不支持字典的全局加速。
2.StarRocks 全局字典的构建
对于 StarRocks 的全局字典的构建,主要有以下考虑:
- 自适应,不需要用户通过 Schema 指定特定低基数列,而是根据数据特性,自动选择优化策略。
- 尽可能避免单点问题,比如数据导入的时候遇到新的字符串,先通过中心节点更新全局字典。
数据存储上的字典优化
首先先来看下 StarRocks 的数据存储的结构。
StarRocks 的基本存储单元为 Segment,每个 Segment 的存储结构如下图所示:
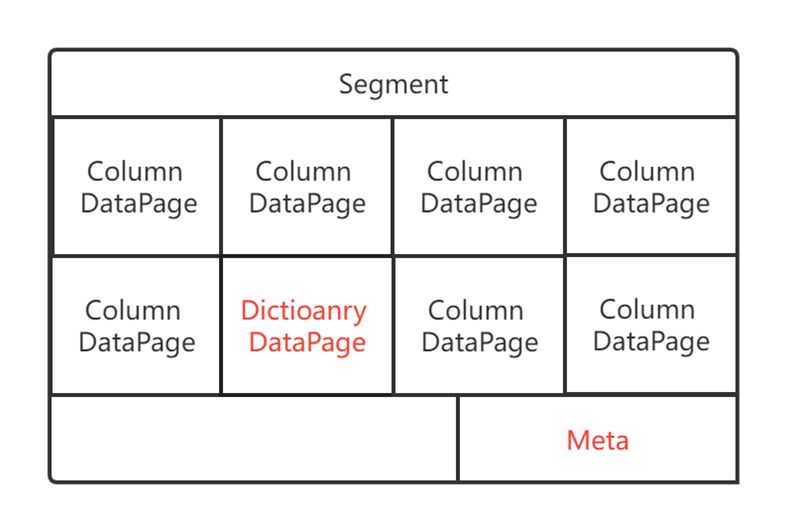
StarRocks 的存储结构天然为低基数字符串做了字典编码。对于 Segment 上的低基数字符串列会有以下特点:
- Footer 上会存储有这个 Column 特有的字典信息,包括字典码跟原始字符串之间的映射关系;
- Data page 上存储的不是原始字符串,而是整数类型的字典码(整型)。
简单的示意图如下:
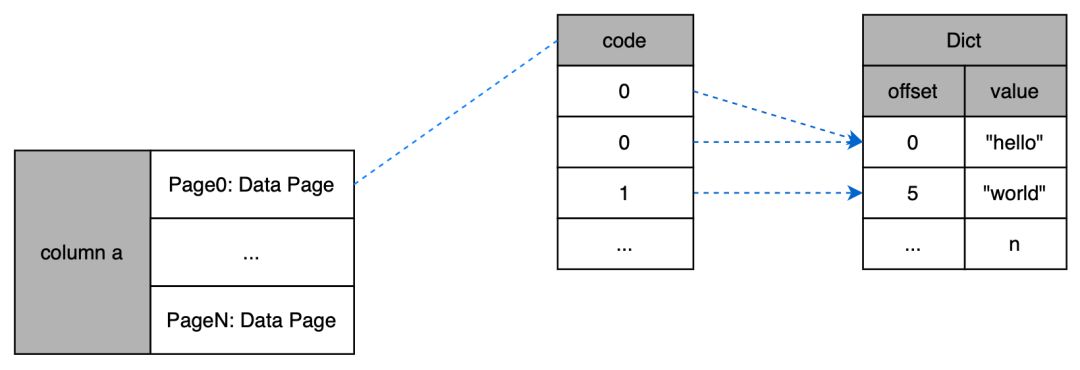
当处理低基数 String column 的时候,直接使用编码后的字典码,而不是直接处理原始的 String 值。当需要原始的 String 值时,使用字典码就可以很方便地在这个列的字典信息里面拿到原始 String 值。这么做带来的明显好处是:
- 减少了磁盘IO。
- 可以提前做一些过滤操作,提升处理速度。
全局字典的构建
StarRocks 支持 CBO 优化器,并且存在一套统计信息机制,那么就可以通过统计信息来收集全局字典。我们通过统计信息,筛选出潜在的低基数列,再从潜在的低基数列的元数据中读取字典信息,然后做去重/编码操作,就可以收集到全量的字典了。
全局字典的正确性保证
对于低基数列来说,那么肯定会出现一种情况,在某次导入中导入了新的 String (这个 String 不在全局字典的集合内),那么这个时候,原先已经构建的全局字典就没有办法包含所有的字符串的值。因此 StarRocks 需要维护全局字典的有效性。
全局字典可能失效只会出现在导入, StarRocks 支持了很多类型的数据导入方式,而所有的导入都有两个共同点
- 导入产生新的 Segment。
- 通过 Master FE 提交事务。
对于低基数列,所有 Segment 中都必定存在局部字典信息,那么对于一个新的导入,在产生新的 Segment 时,会有几种情况。
- 如果新生成的 Segment 没有了局部字典,那么说明这个列很可能是一个高基数列,此时不再适合全局字典优化;
- 新生成的 Segment 有局部字典,而且局部字典中的所有 String 是全局字典的子集,这种情况下可以直接使用旧的字典;
- 新生成的 Segment 有局部字典,而且局部字典所有的 String 值,部分不在全局字典里,此时全局字典失效已经生效,需要重新生成全局字典。
无论出现了上面的哪种情况,在向 FE 中心节点提交的时候,带上这个对应的信息,我们就都能保证全局字典的正确性。
因为每次导入都是产生新的版本,而查询是支持 MVCC 的,每次查询都会带有一个固定的查询版本号。在某一时刻中,如果出现一个新的版本数据,那么对这个版本出现之前的所有查询都是不可见的。因此我们查询中如果有新的导入,那么已发起的查询也是不受影响的。
#04 如何高效使用全局字典
1.CBO 优化器的紧密配合
对于一个简单的聚合 SQL 来说,其执行过程如下:
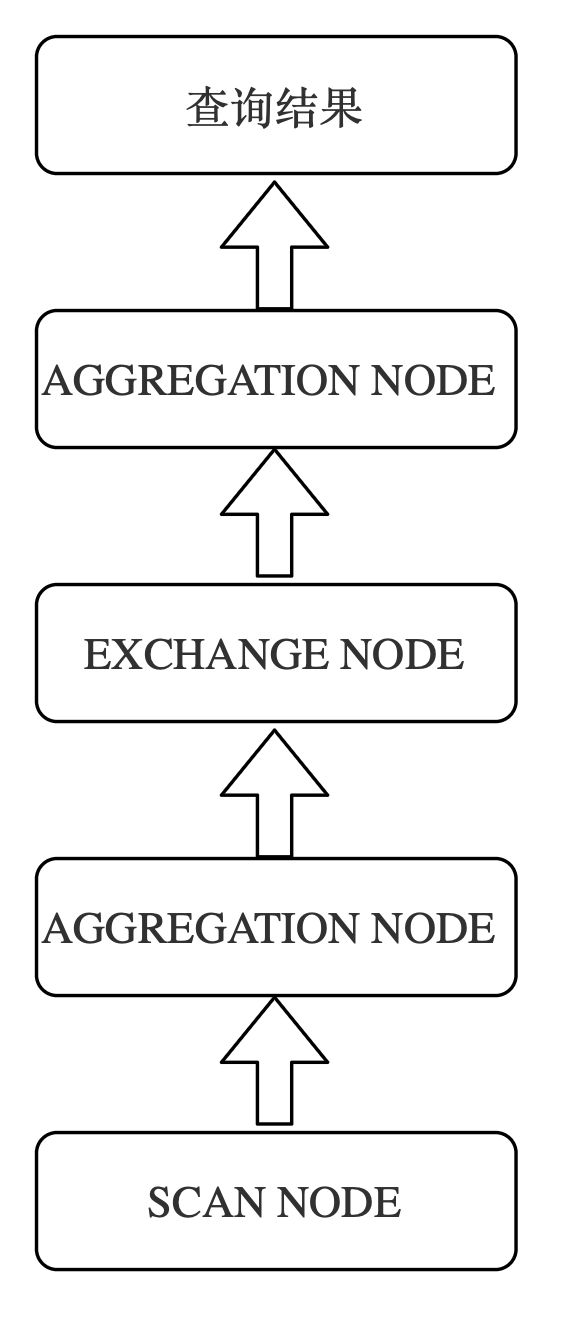
因为 StarRocks 是个分布式系统,其数据分散在多个后端 BE 实例上,且存在多个副本。Segment 内的字典是一个局部的字典,不能作为全局字典码使用。
对于一个没有使用全局字典优化的 SQL,在 SCAN NODE 扫描 Segment 数据的过程中就需要将对应把局部的字典码(int)解码成原始的 String 返回给上层节点。
如果使用了全局字典优化,我们就不需要 SCAN NODE 节点就进行 Decoded,而是可以将原先的局部字典码(int),直接映射到全局字典中的字典码(int),并在之后的计算处理过程中,均使用全局字典码进行处理。当遇到某些特殊的算子,或者是需要具体的依赖字符串内部信息的时候,再按着全局字典的信息,Decoded 出原始的 String 值,这样可以充分利用到全局字典的加速。
下图展示了 SCAN NODE 使用全局字典后,向上传递的数据使用了 int 编码:
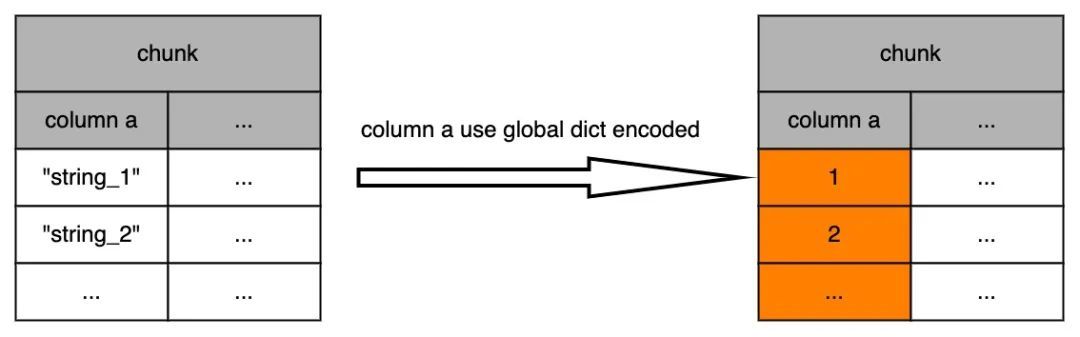
既然我们已经有了全局字典,那么接下来的问题就是更高效地使用好全局字典。
当存在全局字典的时候,所需要做的比较关键的就是:
- 将对 String 的操作转化为对 int 的操作时 ,从而提升处理的速度,节省对应的资源。
- 当遇到无法使用 int 替代 String 的操作时,需要提前将字典码 Decoded 成 String。
举个例子:
lineitem 表中的 l_shipmode 是低基数 String 列
select count(*) from lineitem group by l_shipmode;对于这个 SQL 来说,我们需要的只是聚合之后的行数,因此在整个 SQL 的执行过程中,都可以使用 int 来替代 String 进行处理,并不需要进行 Decoded。
select count(*), l_shipmode from lineitem group by l_shipmode;而对于这个 SQL,需要的不仅仅是聚合后的结果数,还有对应的字符串值。在这里我们需要在结果输出之前,进行 Decoded,将 int 值翻译成 String。
对于第二条 SQL 来说,其执行过程如下所示:
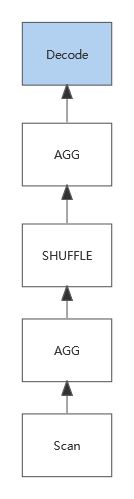
可以看到第二条 SQL 多了个 Decode 节点。
对于低基数 String 列来说,聚合后的行数并不多,这个 Decode 的成本基本可以忽略不计,反而在之前的处理,使用 int 替代 String 所带来的提升是巨大的。
那么,对于查询规划器来说,要做的就是选择最合适的 Decode 时期,最大限度地提升性能。
select * from lineitem;对于上面的 SQL 来说,使用全局字典,反而会带来额外的解码的开销。对于这样的 SQL,我们的 CBO 优化器需要正确规划,并且不会使用字典。
2.全局字典的字符串函数优化
上面的 SQL 都是简单的例子。如果稍微对 SQL 进行一些改动,比如:
select count(*), l_shipmode from lineitem group by substr(l_shipmode, 1, 3);在这个 SQL 中,需要对 String 列进行 substr 运算,并且按着运算后的值进行聚合,这么一看,那肯定是需要在聚合前,插入一个 Decode 节点来把字典码转为具体的字符串值了,甚至在扫描数据的时候,就需要原始的 String 列了。
对于这条 SQL 来说,使用 int 值替代 String 来进行聚合,所带来的提升是巨大的,我们应该发挥全局字典的最大价值。
对于大多数的字符串函数来说,他们的计算往往有下面的一些特点:
- 对于固定的输入,输出也是固定,最简单的比如 substring 函数, substring("abc", 1, 2) 的结果一定是 "AB";
- 大部分 String 操作,都符合上面的定义。
既然对于单个 String 的运算,输出是固定的,那么对于固定集合的 String 的运算,其结果集合也一定是固定的,比如对 {"s1", "s2", "s11" } 进行 substring(str, 1, 2) 运算,其结果也一定是 {"s1", "s2", "s11" }。
很明显,当有了低基数全局字典,全局字典里面的 String 取值,就是固定的集合。因此,我们将对单个 String 的操作,转化为对 String 集合的操作,而这个操作,在 SQL 执行的过程中,只需要执行一次。
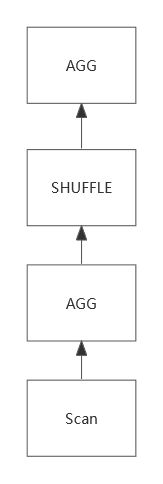
以上面的 substr SQL 为例子,当低基数列 l_shipmode 存在全局字典时,我们运用 substr 对全局字典进行计算,计算的示意图如下:
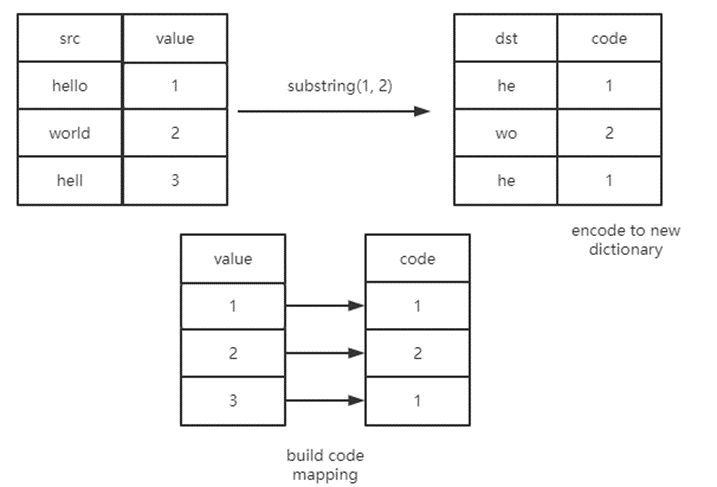
对于上图所示的全局字典来说,substring("hello", 1, 2) 和 substring("world", 1, 3)产生的结果集是 {"he", "wo"}。我们会把所有的输出都加入到一个新的字典中,与此同时,我们还得到了两个字典之间的转换关系。
例如字典码1的输入在经过这个函数之后会变成新字典的字典码1。
有了这个映射关系,对输入的数据,进行 substring 操作,那就很简单了,因为我们输入的数据是全局字典码,并不是原始的 String,我们只需要按着 substring 中两个字典之间的转换关系,将对应的字典码通过映射输出成对应的新字典码,就完成了相关函数的计算。
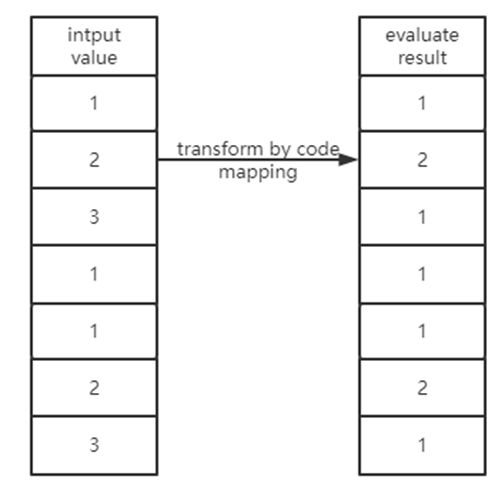
对于这类的字符串函数,并不需要进行 Decode 获取原始 String 来调用函数处理,而且这种映射的方法,对于直接使用字符串进行计算也有一定的性能提升,尤其是对复杂的表达式。
#05 优化效果
我们选取了几组典型的 SQL,对比了开启低基数下的性能。
StarRocks 2.0+后的版本默认会开启低基数字典优化:
set cbo_enable_low_cardinality_optimize = true;对比 SQL:
select count(*),lo_shipmode from lineorder group by lo_shipmode;
select count(distinct lo_shipmode) from lineorder;
select count(*),lo_shipmode,lo_orderpriority from lineorder group by lo_shipmode,lo_orderpriority;
select count(*),lo_shipmode,lo_orderpriority from lineorder group by lo_shipmode,lo_orderpriority,lo_shippriority;
select count(*) from (select count(*) from lineorder_flat group by lo_shipmode,lo_orderpriority,p_category,s_nation,c_nation) t;
select count(*) from (select count(*) from lineorder_flat group by lo_shipmode,lo_orderpriority,p_category,s_nation,c_nation,p_mfgr) t;
select count(*) from (select count(*) from lineorder_flat group by substr(lo_shipmode,2),lower(lo_orderpriority),p_category,s_nation,c_nation,s_region,p_mfgr) t;
select count(*),lo_shipmode,s_city from lineorder_flat group by lo_shipmode,s_city;
select count(*) from lineorder_flat group by c_city,s_city;
select count(*) from lineorder_flat group by c_city,s_city,c_nation,s_nation;
select count(*) from lineorder_flat group by lo_shipmode,lo_orderdate;
select count(*) from lineorder_flat group by lo_orderdate,s_nation,s_region;对比结果:
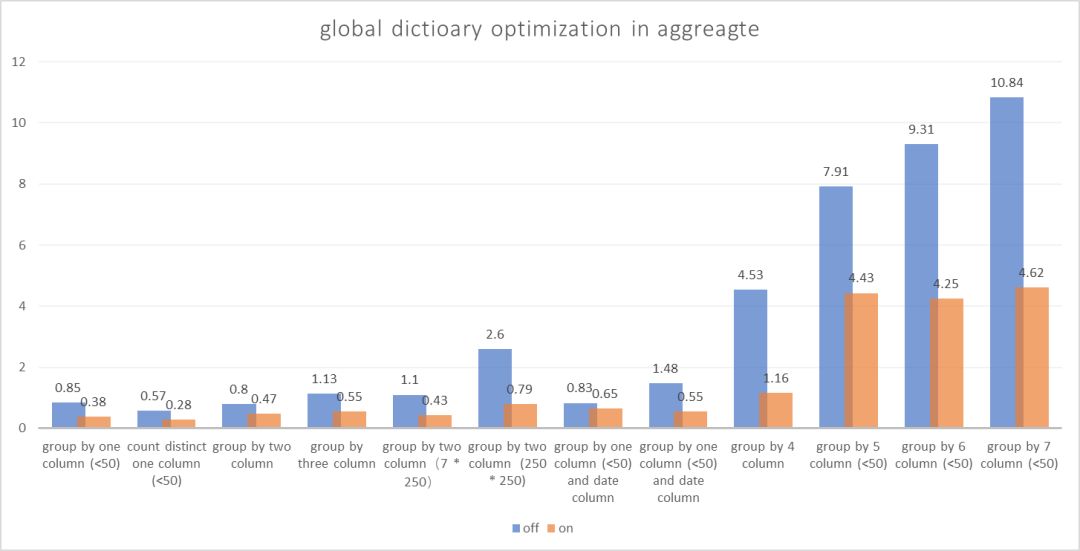
从效果上来看,开启低基数优化的 SQL 比没开启低基数优化的 SQL 平均快了 3 倍。
#06 总结
StarRocks 的低基数 String 优化,主要的特点有:
- 全局的字典加速,作用于 SQL 执行的各个阶段。
- 基于 CBO 优化器的,自适应选择全局字典的加速策略。
- 无 Schema,自适应,用户不需要指定特定的低基数列。
- 对用户透明,不需要重新导数据。
- 高性能,业界领先水平。
- 支持场景丰富,兼容大部分 String 处理逻辑。


