
StarRocks技术内幕 | 资源隔离原理解析
本文发表于: &{ new Date(1675958400000).toLocaleDateString() }
资源隔离一直是 StarRocks 用户讨论较多的话题,对于资源隔离的诉求,主要集中在四点:
1. 很多用户关注资源的隔离性,期望当有核心业务的查询运行时,可以限制其他类型任务的使用资源,进而保障核心业务的响应时间。
2. 及时熔断大查询,避免其浪费很多资源后才失败。
3. 限制各个租户之间以及一个租户内各种类型任务的 CPU / IO /内存等资源,将这些类型任务的资源隔离开。
4. 很多用户也关注资源的利用率,期望当有多种类型的工作负载在同一个集群运行时可以具有一定的隔离性。并且当某些资源组空闲时,其他正在运行的资源组可以弹性地使用这部分资源。
总的来说,用户期望我们能够提供资源隔离的功能来合理地控制 CPU / IO / 内存等资源,既要能够实现多租户的资源隔离,也要能够充分利用资源,让不同的负载工作在同一个集群上,来降低集群的管理成本。
除此以外,资源隔离功能也可以为未来的 Serverless 化提供支持。因为相比于增加节点数目的 SQL out 模式,提高单个节点资源的 SQL up 模式可以做到更加快速的秒级以内的弹性。但是 SQL up 模式会导致多个租户共享同一个集群,所以资源隔离是其中关键的技术。
如何在保证资源隔离的前提下提高资源的利用率,是资源隔离的关键点和挑战:如果没有资源隔离,那么集群会具有良好的资源利用率,但是会完全没有隔离性;而如果完全进行物理隔离,会具有良好的隔离性,但是弹性会明显不足。
所以我们选择在用户态来实现调度策略,进行逻辑上的隔离。
#01 资源隔离的现有能力
目前我们提供了两个方面的资源隔离能力:一方面是资源的隔离,另外一方面是资源的限制。
对于资源的隔离,我们提供了内存资源的硬隔离、CPU 资源和 IO 资源的软隔离以及短查询资源组对于 CPU 和 IO 资源的硬隔离。
对于资源的限制,我们提供了并发资源的限制以及大查询的熔断控制。
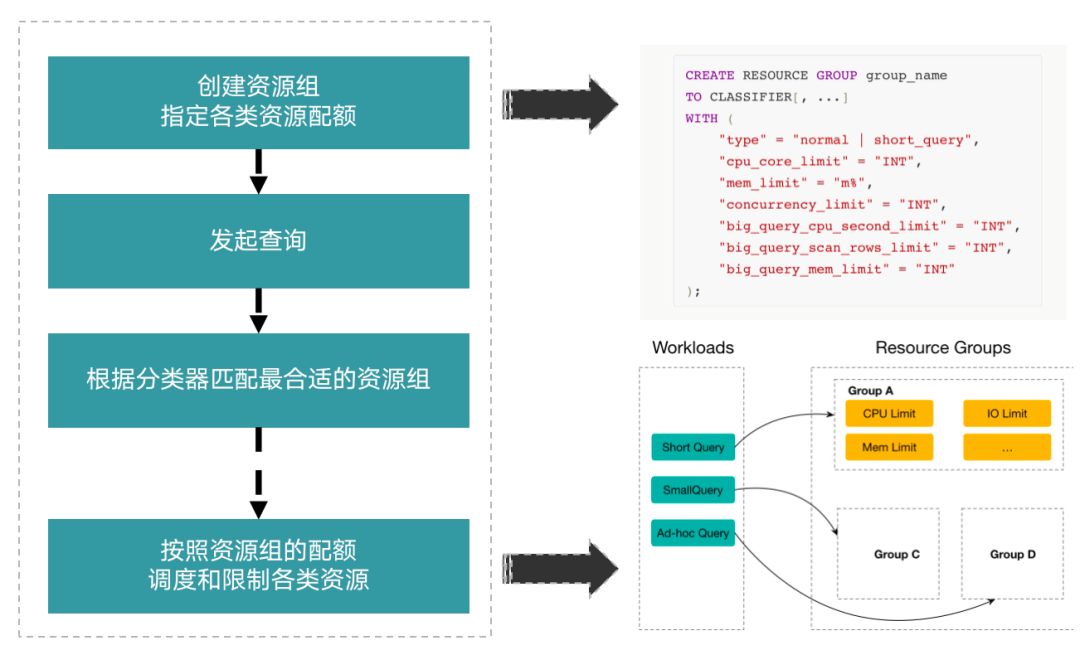
1.定义资源组
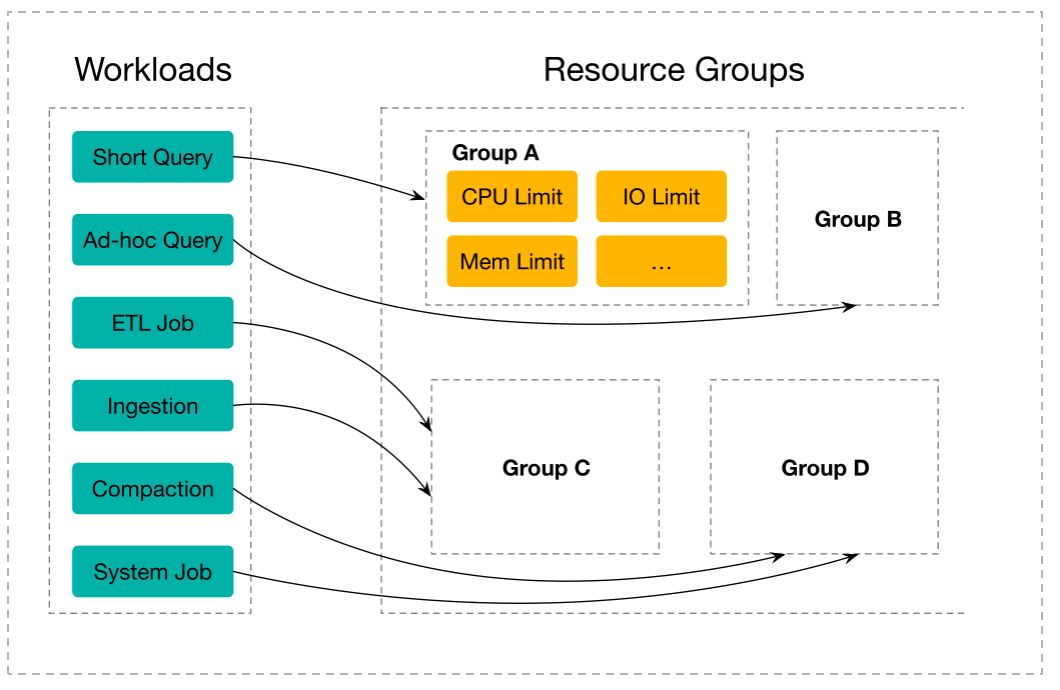
在实施各类资源隔离的功能之前,需要先明确如何去定义不同租户之间以及一个租户内不同类型的工作负载的资源隔离。在这里我们抽象出了资源组的概念,下图是一个资源组,可以定义各类资源的配额,并且绑定多个分类器。使用分类器就可以将不同租户以及一个租户内不同的工作负载匹配到不同的资源组。

2.查询分类
查询分类是基于用户、角色、IP 等特点进行的,具体来说,一个分类器可以提供如下五个条件中的任意一个,包括用户、用户所属角色、SQL 类型、发起查询的 IP 以及查询访问的数据库。其中 SQL 类型目前只支持 select 语句,即查询,对于导入等任务类型的支持也正在逐步开发中。当发起一个查询后,可能会有多个资源组的分类器满足条件,这个时候就需要从多个满足条件的分类器中选择最合适的一个。这里主要分为三步:
首先,优先选择有 DB 条件的分类器,如果有n个或者0个有 DB 条件的分类器,则会优先选择条件数量最多的分类器。如果有多个条件数量相等的分类器,则会选择条件最精确的分类器。

以上图为例,分类器A到D的优先级会逐渐升高,其中它们是否有 DB 条件、条件的数量、条件的精确程度都有所不同。
在定义了资源组和分类器以后,就可以实施各项资源隔离的功能了。
3.内存资源的硬隔离
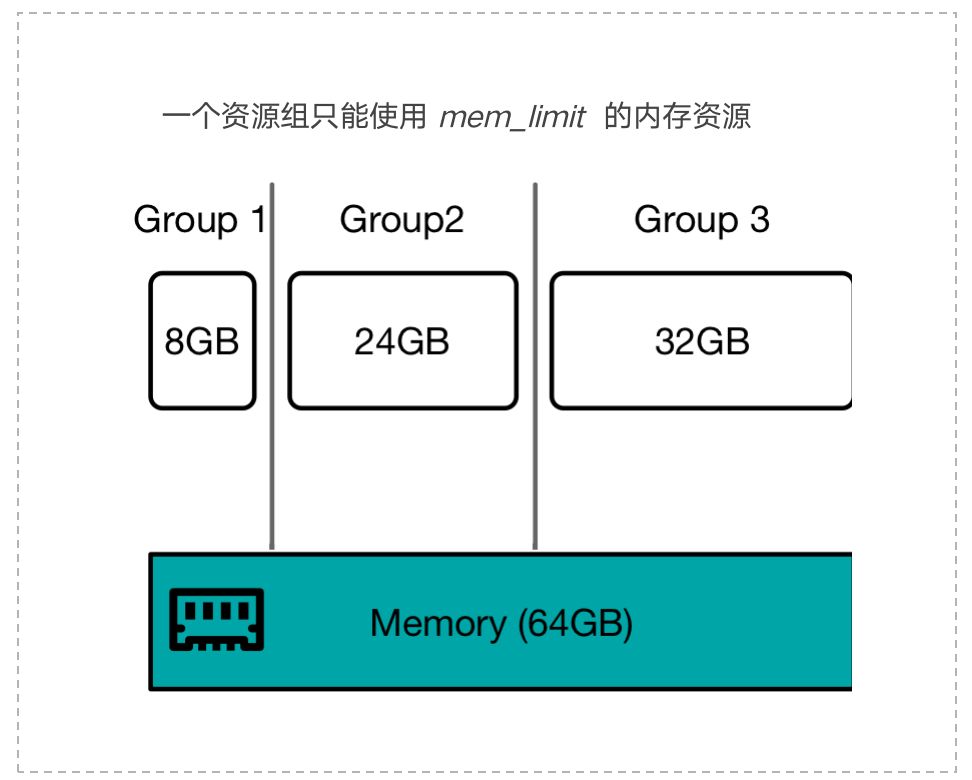
内存资源的硬隔离,即一个资源组只能使用 memory limit 的内存资源。当该资源组使用的内存资源超限以后,那么该资源组内的查询会返回失败的状态。
4.CPU 资源的软隔离
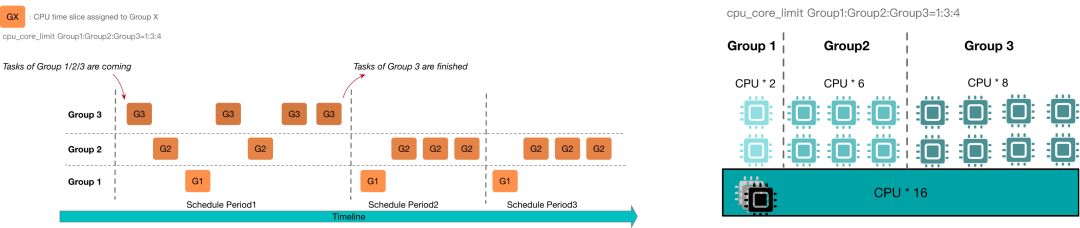
CPU 资源的软隔离会将所有正在运行的资源组按照 cpu_core_limit 的比例来分配 CPU 时间片。
以下图为例,三个资源组会按照1:3:4的比例来使用所有16核的 CPU 资源,即从逻辑上会分别分配到2核、6核和8核的 CPU ,并且当资源空闲时,正在运行的资源组可以弹性使用更多的资源。当第一个调度周期结束以后,第三个资源组的所有任务都已经完成了,所以在接下来的调度周期2和3中,其他的资源组1和2就可以使用全部的 CPU 资源了,也就是每个周期可以分配到更多的时间片。
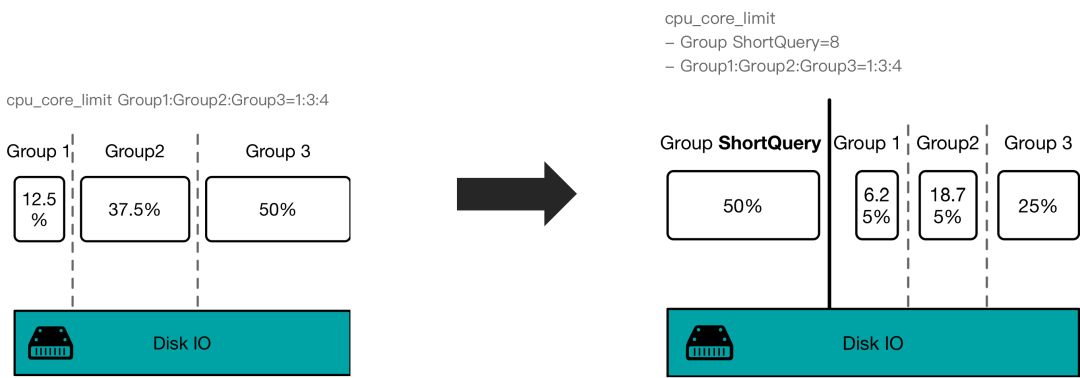
5.短查询资源组与 CPU 资源的硬隔离
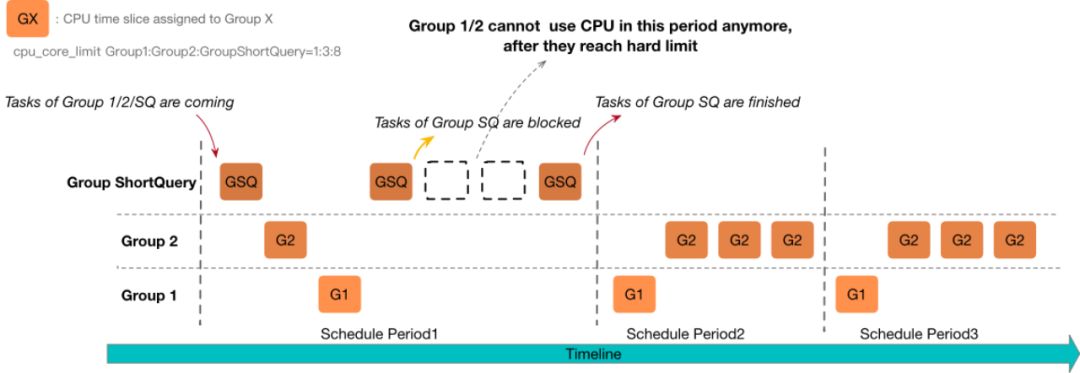
CPU 资源的软隔离的方式会存在少量的调度延时,所以对于高优先级的点查这一类对调度延迟很敏感的极端的场景,我们提供了短查询资源组的功能。当有短查询资源组的查询时,会为其保留 cpu_core_limit 的 CPU 资源,其他资源组只能使用剩余的 CPU 资源。
以下图为例:在第一个调度周期中,资源组1和2的 CPU 资源已经达到使用上限,所以即使短查询资源组的所有任务都处于阻塞状态,没有可以运行的任务,也不能去调度资源组 1 和 2 的任务去执行。而当第一个调度周期结束以后,短查询资源组的所有任务都完成了,所以在接下来的调度周期 2 和 3 中,其他的资源组 1 和 2 不再有对于 CPU 资源的硬限制,也就是可以使用全部的 CPU 资源了。
6.IO 资源的软隔离与短查询资源组的硬隔离
对于 IO 资源的隔离策略也分为两个方面:
一方面,每个资源组会按照 cpu_core_limit 的比例来分配 IO 时间片。
另一方面,当有短查询资源组的查询时,也会为其预留cpu_core_limit 的 IO 资源。
从这两方面,我们提供了对于 CPU 资源和 IO 资源的隔离。但是如果在同一时刻涌入了过多的查询,也会导致集群的资源过载。因此,我们也提供了并发资源的硬限制功能。
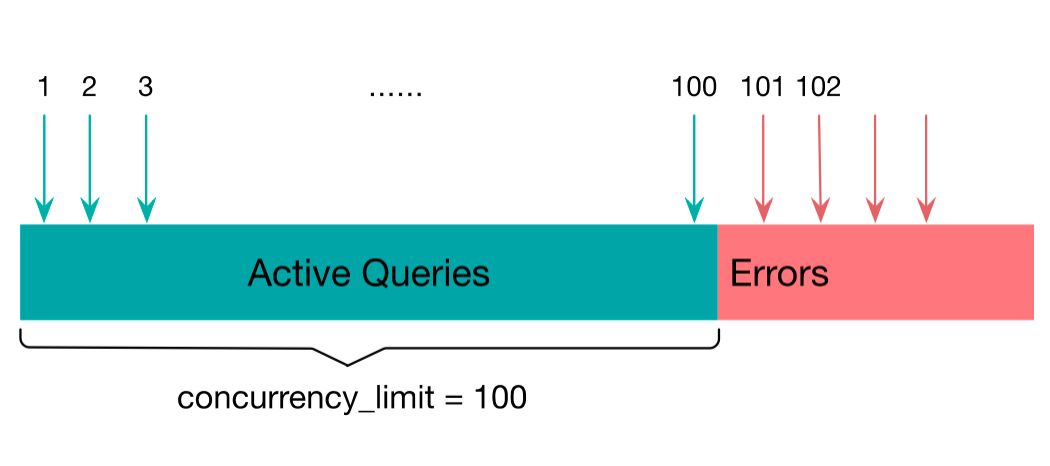
7.并发资源的硬限制
并发资源的硬限制,即一个查询只能同时处理 concurrency_limit 的并发请求,如果发起的请求数目超过了该阈值,会直接返回失败的状态。在后续版本中,会支持实时查询任务排队的功能,来避免直接返回失败的状态。
8.大查询的熔断控制
当一个查询使用的 CPU 时间、IO 扫描的行数以及内存资源超过阈值时,大查询会直接被熔断,返回失败的状态。

以上就是对于资源组合分类器的定义以及各类资源隔离的功能。总的来说,对于使用资源隔离,首先要创建资源组和分类器,来指定各类的资源配额,并且指定匹配的租户以及工作负载类型。当发起一个查询后,会根据分类器来匹配到最合适的资源组,每个节点会按照资源组的资源配额来调度 CPU 和 IO 资源,并且限制内存和并发资源,同时检查是否需要熔断。
#02 资源隔离的实际效果
对于资源隔离的实际效果,我们主要进行了三个方面的测试,分别是不同资源组运行相同负载的测试、大小查询的测试、短查询资源组的测试。
1.不同资源组运行相同负载的测试
我们使用了两个资源组,其 cpu_core_limit 之比为 2:1,每个资源组各自4并发运行相同的查询。我们期望两个资源组的 QPS 之比为2:1,来说明它们按照比例使用了资源。
下面图中是 SSB 100GB 的测试结果,可以看到每一个查询的 QPS 都符合了2:1的比例。
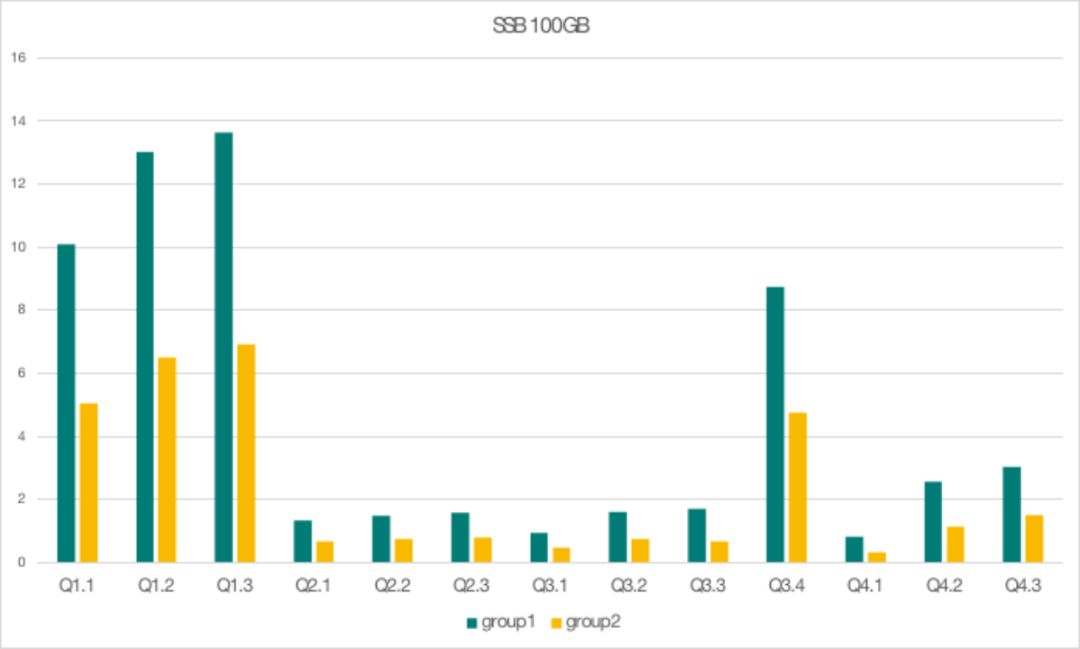
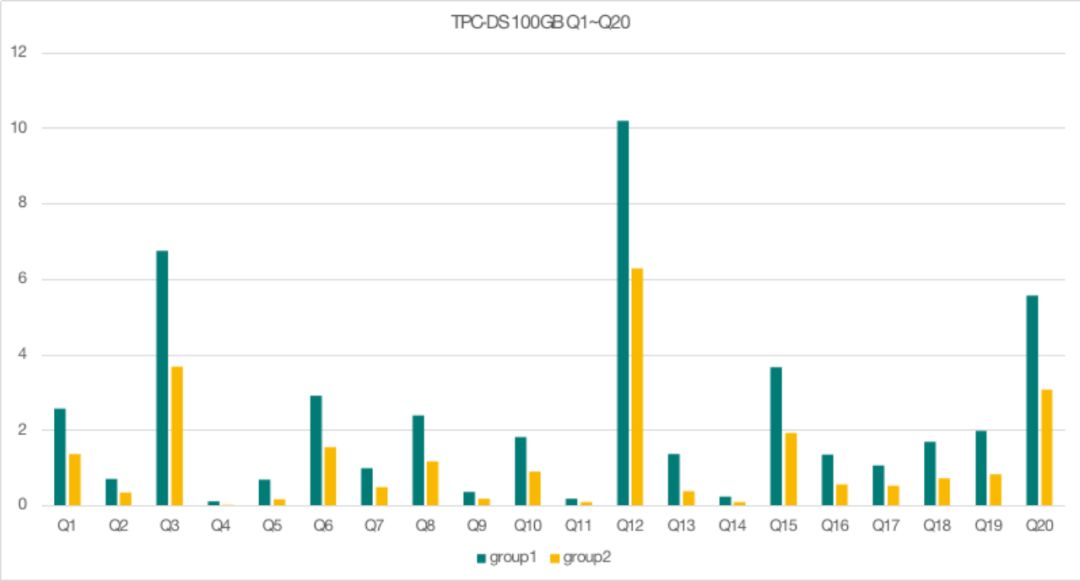
接下来是TBC-DS 100GB 前20个 query 的测试结果,每一个查询也基本符合了2:1的 QPS 比例,这说明对于不同资源组运行相同负载的测试,两个资源组可以按照比例使用资源将资源隔离开。
2.大小查询的测试
在实际使用中,大小查询混合的工作负载模式会更加常见。所以我们也进行了这一类的测试。
本次依旧使用两个资源组,其 cpu_core_limit 之比为 2:1,第一个资源组运行8并发的小查询,第二个资源组运行4并发的大查询。我们期望与大查询混跑的小查询的 QPS 与单独跑的 QPS 之比为2:3,来说明该资源组使用了2/3的资源,没有受到另外一个资源组的大查询的影响。其中对于小查询和大查询,我们都提供了各种类型的查询进行测试。
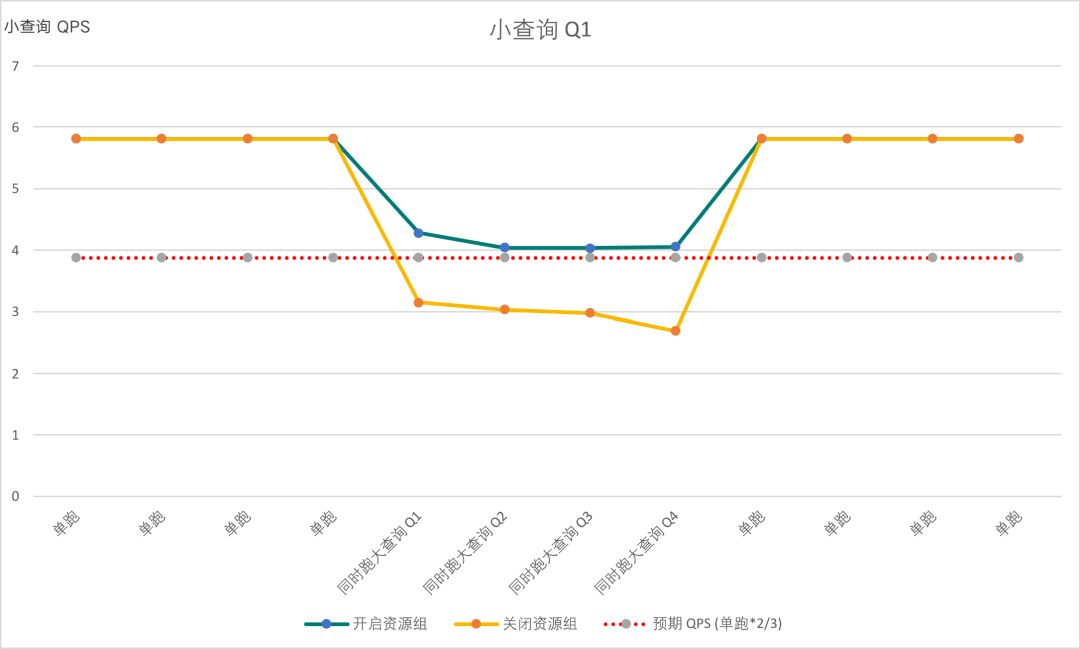
下图是第一个小查询的测试结果,其中黄色的折线是关闭资源组的测试结果,蓝色的折线是打开资源组的测试结果。而在两条虚线中间的部分是与大查询混跑的小查询的 QPS ,可以看到混跑的小查询的 QPS 与单跑的小查询的 QPS 之比符合2:3的比例。
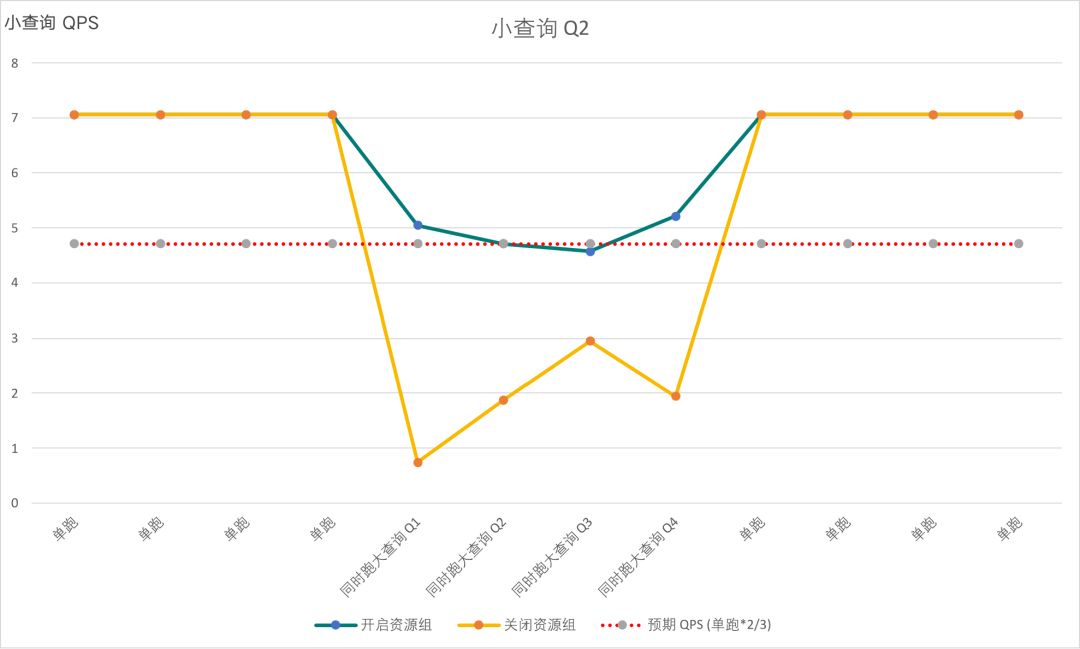
接下来是第二个小查询的测试结果,可以看到也基本符合2:3的比例。这说明对于大小查询的测试,运行小查询的资源组没有受到另外一个运行大查询资源组的影响,可以将资源隔离开。
3.短查询资源组的测试
对于高优先级的很短的点查询,我们提供了短查询资源组的功能,并且进行了相应的测试。
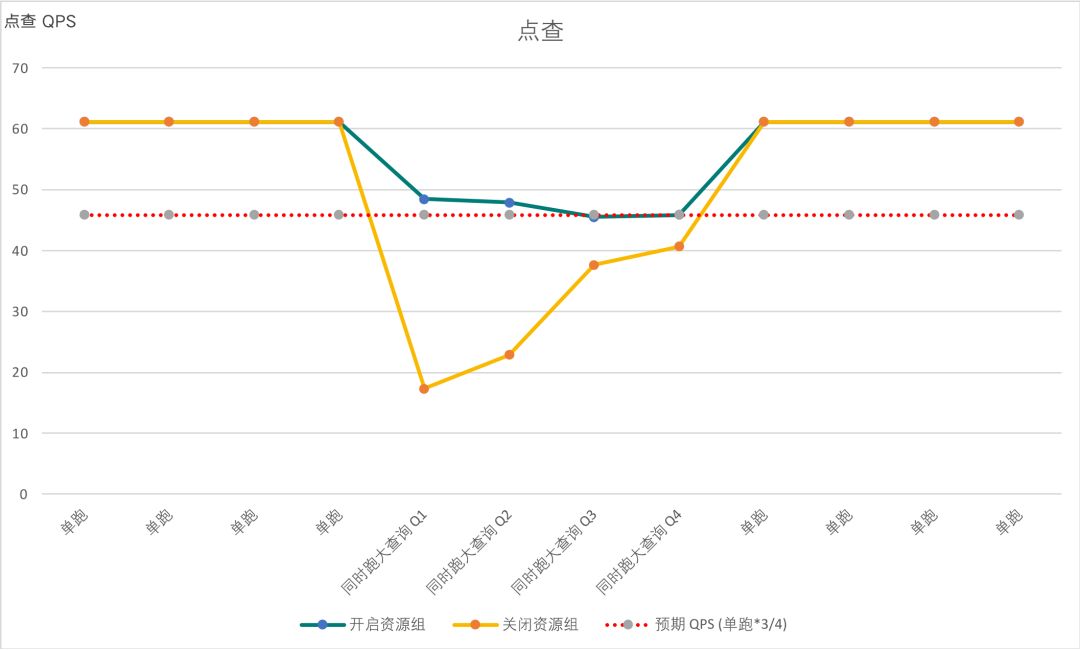
短查询资源组与另外一个资源组的 cpu_core_limit 之比为 3:1,短查询资源组运行8并发的点查询,另外一个资源组运行4并发的大查询。我们期望与大查询混跑的点查的 QPS 与单独跑的 QPS 之比为3:4,来说明短查询资源组使用了3/4的资源。
下图是具体的测试结果:与大查询混跑的点查的 QPS 与单独跑的 QPS 之比基本符合3:4的比例,这说明可以为短查询资源组预留3/4的资源。
#03 资源隔离的工作原理
下图是资源隔离的整体架构,当发起一个查询用后,会根据分类器绑定合适的资源组,然后将查询拆分为多个执行单元的任务,分发给各个 BE 节点。每一个 BE 节点会根据对应资源组的资源配额来调度 CPU 和 IO 任务,并且限制内存和并发资源,同时检查是否需要熔断、大查询。

1.内存资源的硬限制
对于内存资源的硬限制,复用了 StarRocks 已经提供的对于内存资源统计和检查的功能,使用 TCmalloc 的 Hook 在申请和释放内存时对内存进行统计和检查,在每一个线程运行时会绑定一个 Memory Tracker 到一个 Thread Local 变量。这个 Memory Tracker 就是用来记录和检查内存的,它是一个多级的树结构。其中对于资源隔离来说,会添加每一个资源组的 Memory Track 到树形结构中。
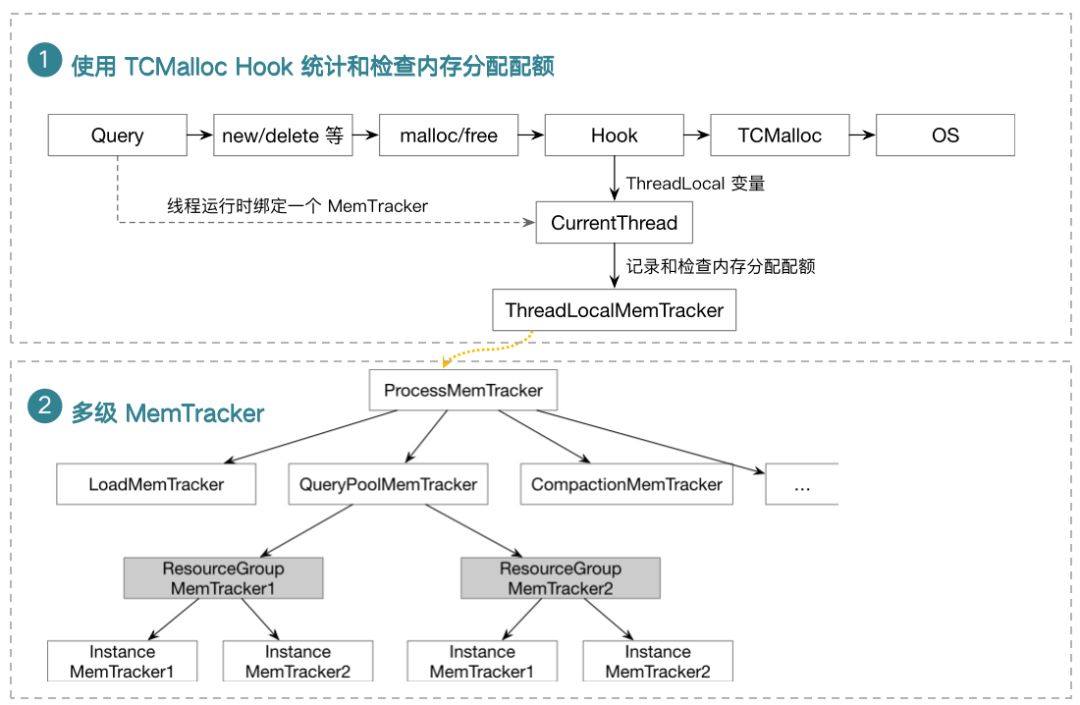
2.CPU 和 IO 资源的软隔离
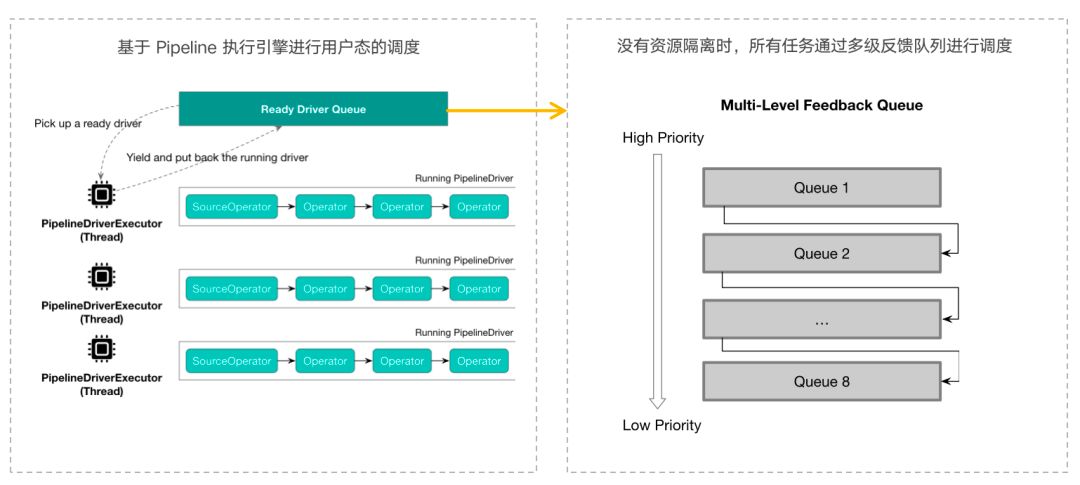
对于 CPU 和 IO 资源的软隔离是基于 StarRocks 的 pipeline 执行引擎实现的:pipeline 执行引擎会将所有查询的执行单元的任务在用户态进行调度。
具体来说会有核数个执行线程以及一个查询单元任务的就绪队列。每一个执行线程会从就绪队列中取出合适的任务来执行,并且正在执行的任务会因为时间耗尽或者其他调度因素的影响,及时的让出执行线程并且放回就绪队列,执行校验程再从就绪队列中取出下一个合适的任务来执行。
pipeline 执行引擎会将所有查询的执行单元任务在用户态进行调度,因此可以很方便地实行各种不同的调度策略。而当没有资源隔离时,所有任务是通过多级反馈队列进行调度的。
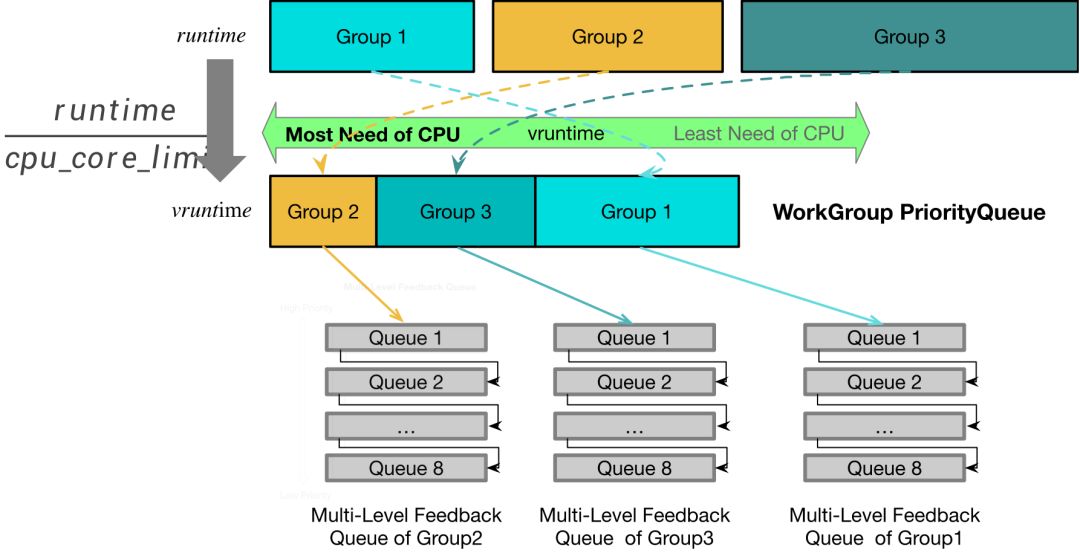
当有资源隔离以后,会使用一个两级的队列进行调度,这里与 Linux 进程的完全公平调度算法类似:第一级是资源组的优先级队列,第二级是每个资源组内部的多级反馈队列。每次执行线程在选择合适的任务执行时,会选择当前 Vruntime 最小的资源组的任务来执行,Vruntime 就是将 CPU 执行时间或者 IO 执行时间除以 cpu_core_limit 得到的。
通过这种方式可以保证所有资源组按照 cpu_core_limit 的比例来使用 CPU 和 IO 资源。同时为了尽量减小调度延迟,我们会不断地检查当前正在执行任务的 Vruntime 是否还是最小的,如果它不再是最小的,会及时让出 CPU 或者 IO 资源。为了避免频繁地更换任务,会保证一个任务至少执行 5 毫秒之后才让出。
此外,如果一个很久没有任务的资源组再次有任务到来时,因为其他的资源组一直在运行,它们的 Vruntime 在持续增加,所以这个资源组的 Vruntime 会相对小很多。为了避免一直调度它的任务去执行,导致其他资源组饥饿,所以会调整它的 Vruntime 为当前最小的资源组的 Vruntime ,并且减去一个常量作为它的奖励。
3.短查询资源组与 CPU 和 IO 资源的硬隔离
同样,针对高优先级的很短的点查询,我们提供了短查询资源组的功能。
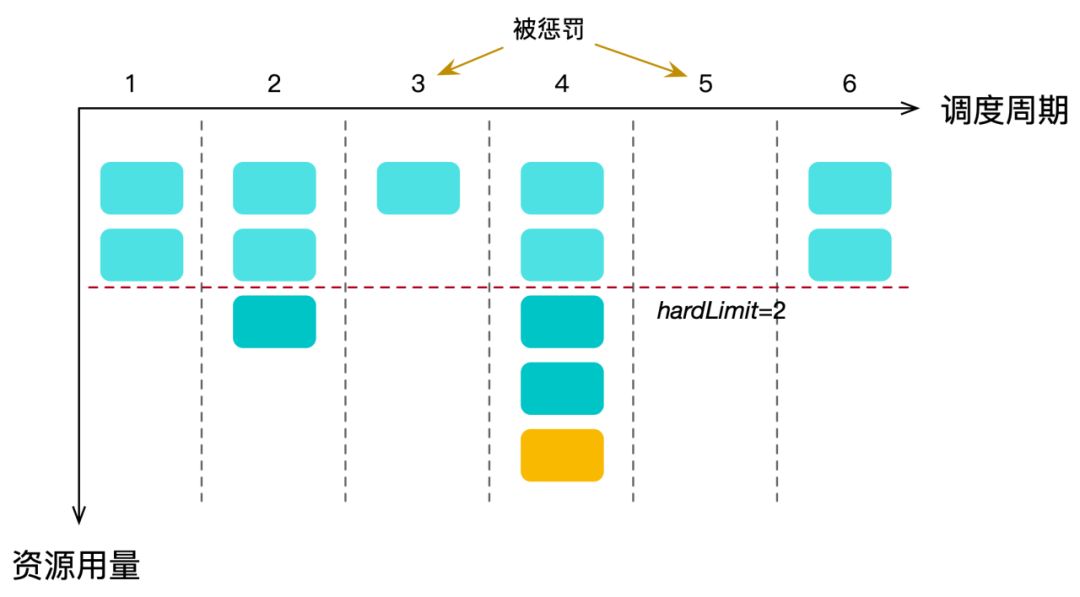
当有短查询资源组的任务时,其余的资源组在每个周期只能使用 hard limit 的资源。如果在一个周期内它们使用的资源超过了该阈值上限,则本周期不会再调度它们的任务去执行。
但是在同一时刻可能会有多个这些资源组的任务在执行,所以当发现资源超限时,它们的资源用量可能已经超过很多了。因此,我们添加了惩罚策略来保证在总体上,对于这些资源组的硬隔离:如果在本周期,它们的资源用量在一倍 hard limit 到两倍 hard limit 之间,那么会将它的下一个周期的资源用量初始值赋值为当前用量减去 hard limit ,也就是在下个周期可以使用少量的资源。而如果当前用量在两倍 hard limit 以上,那么会将它下个周期的资源用量初始值赋值为 hard limit ,即下个周期无法调度它们的任务去执行。
#04 未来规划
总的来说,使用资源隔离,我们首先要定义资源组和分类器来指定各类资源的配额,并且指定匹配的租户以及工作负载类型。当发起一个查询后,会根据分类器匹配合适的资源组,根据对应资源组的配额对 CPU 资源和 IO 资源进行软隔离,并且当有短查询资源组的任务存在时,会对 CPU 和 IO 资源进行硬隔离,同时会限制内存和并发资源,并且检查是否需要熔断大查询。
当前,我们正在开发任务排队机制以及 Spill 机制,来避免在并发资源或者内存资源超限时导致查询失败;同时也计划支持更多的负载类型,逐步支持数据库分析导入和 Compaction ,并且也计划增加多个短查询资源组,来满足更多的用户场景。


