
技术内幕 | StarRocks Pipeline 执行框架(上)
本文发表于: &{ new Date(1665590400000).toLocaleDateString() }
导读:欢迎来到 StarRocks 技术内幕系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你从 0 开始快速上手这款明星开源数据库产品。本期 StarRocks 技术内幕将主要介绍 StarRocks Pipeline 执行框架的基本概念、原理及代码逻辑。
#01 背景介绍
Pipeline 调度与 MPP 调度之间存在着明显的差异,前者是单机多核调度,后者是分布式集群的多机调度。总结下来,Pipeline 调度的目的包括三点:
1. 降低计算节点的任务调度代价;
2. 提升 CPU 利用率;
3. 充分利用多核计算能力,提升查询性能、自动设置并行度、消除人为设置并行度的不准确性。
本文将主要介绍 Pipeline 执行框架的基本概念、原理以及代码逻辑,帮助读者快速入门 StarRocks 的 Pipeline 执行框架,通过阅读本文,你将掌握:
1. 如何在 Pipeline 执行框架中添加算子;
2. Source 算子和 Sink 算子如何异步化;
3. 怎么将单机执行计划拆分成 Pipeline;
4. 添加新的表达式或者函数需要主要的方面。
#02 基本概念
在深入 Pipeline 执行框架的细节之前,我们先来了解一下整体所需的基本概念。这些基本概念,共同构成了 Pipeline 执行框架的底层,建议大家掌握清楚。
1.MPP 调度基本概念
物理执行计划(ExecPlan)
物理执行计划是 FE 生成的,由物理算子构成的执行树;SQL 经过 parse、anlyze、rewrite、optimize 等阶段处理,最终生成物理执行计划。
计划碎片(PlanFragment)
PlanFragment 是物理执行计划的部分。只有当执行计划被 FE 拆分成若干个 PlanFragment 后,才能多机并行执行。PlanFragment 同样由物理算子构成,另外还包含 DataSink,上游的 PlanFragment 通过 DataSink 向下游 PlanFragment的 Exchange 算子发送数据。
碎片实例(Fragment Instance)
Fragment Instance 是 PlanFragment 的一个执行实例,StarRocks 的 table 经过分区分桶被拆分成若干 tablet,每个 tablet 以多副本的形式存储在计算节点上,可以将 PlanFragment 的实例化成多个 Fragment Instance 处理分布在不同机器上的 tablet,从而实现数据并行计算。FE 确定 Fragment Instance 的数量和执行 Fragment Instance 的目标 BE,然后 FE 向 BE投递 Fragment Instance。在 Pipeline 执行引擎中,BE 上的 PipelineBuilder 会把 PlanFragment 进一步拆分成若干 Pipeline,每个 Pipeline 会根据 Pipeline 并行度参数而被实例化成一组 PipelineDriver, PipelineDriver 是 Pipeline 实例,也是 Pipeline 执行引擎所能调度的基本任务。
物理算子(ExecNode)
物理算子是构成物理执行计划 PlanFragment 的基本元素,例如 OlapScanNode,HashJoinNode 等等。
2.FE 负责 MPP 调度
我们以下面的简单 SQL 为例,进一步说明上述概念:
select A.c0, B.c1 from A, B where A.c0 = B.c0第一步:
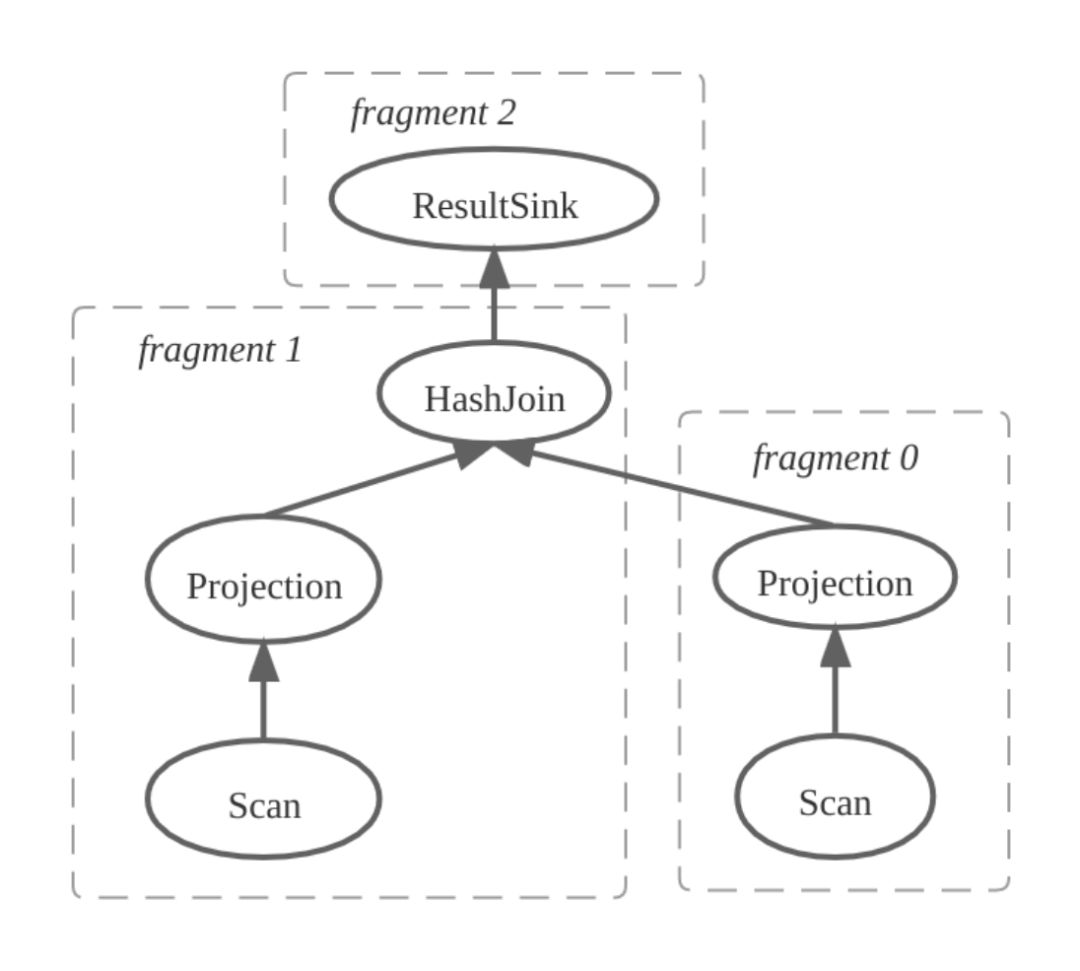
FE 产生物理计划并且拆分 PlanFragment,如下图所示,物理计划被拆分成三个 PlanFragment,其中 Fragment 1 包含 HashJoinNode,Fragment 0 为 HashJoinNode 的右孩子。
第二步:FE 确定 PlanFragment 的实例数量,创建 Fragment Instance。如果一个 Fragment Instance 把另外一个 Fragment Instance 的输出结果作为输入, 则产生数据的一方为上游, 输入数据的一方为下游,上游插入 DataStreamSink 用来发送数据,下游插入 ExchangeNode 算子用来接收数据。如下图所示,其中 PlanFragment 1 有 3 个 Fragment Instance。
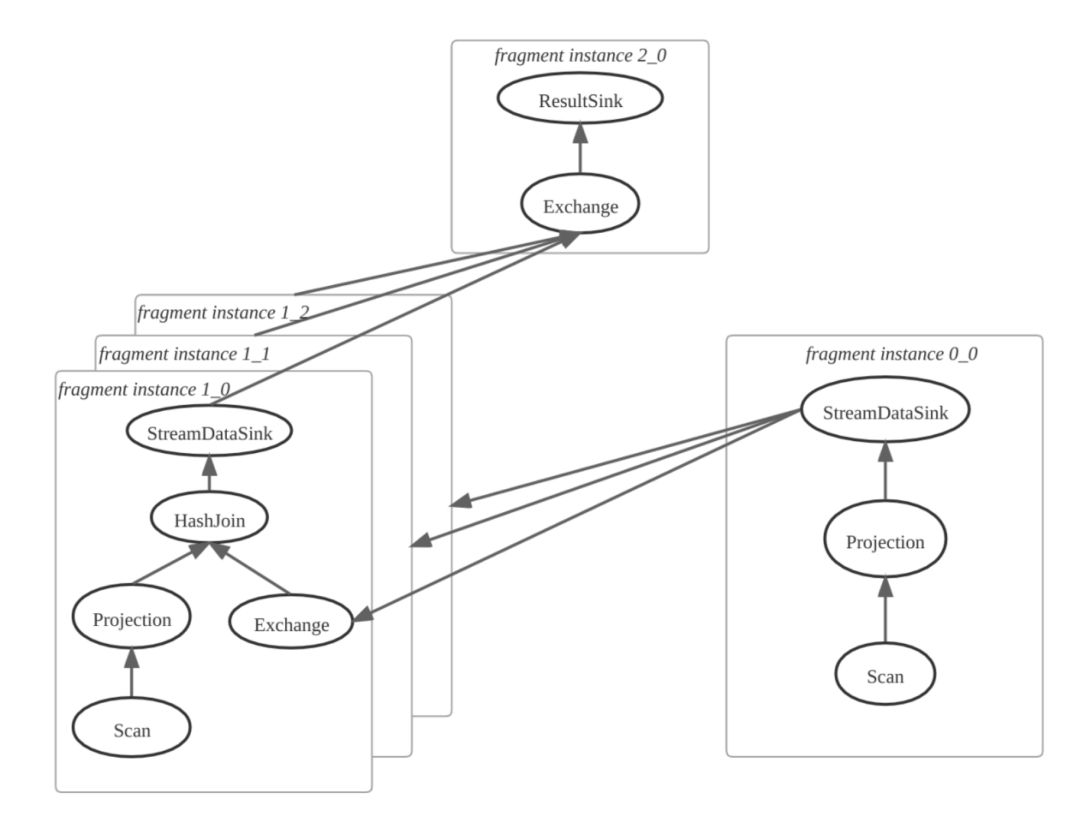
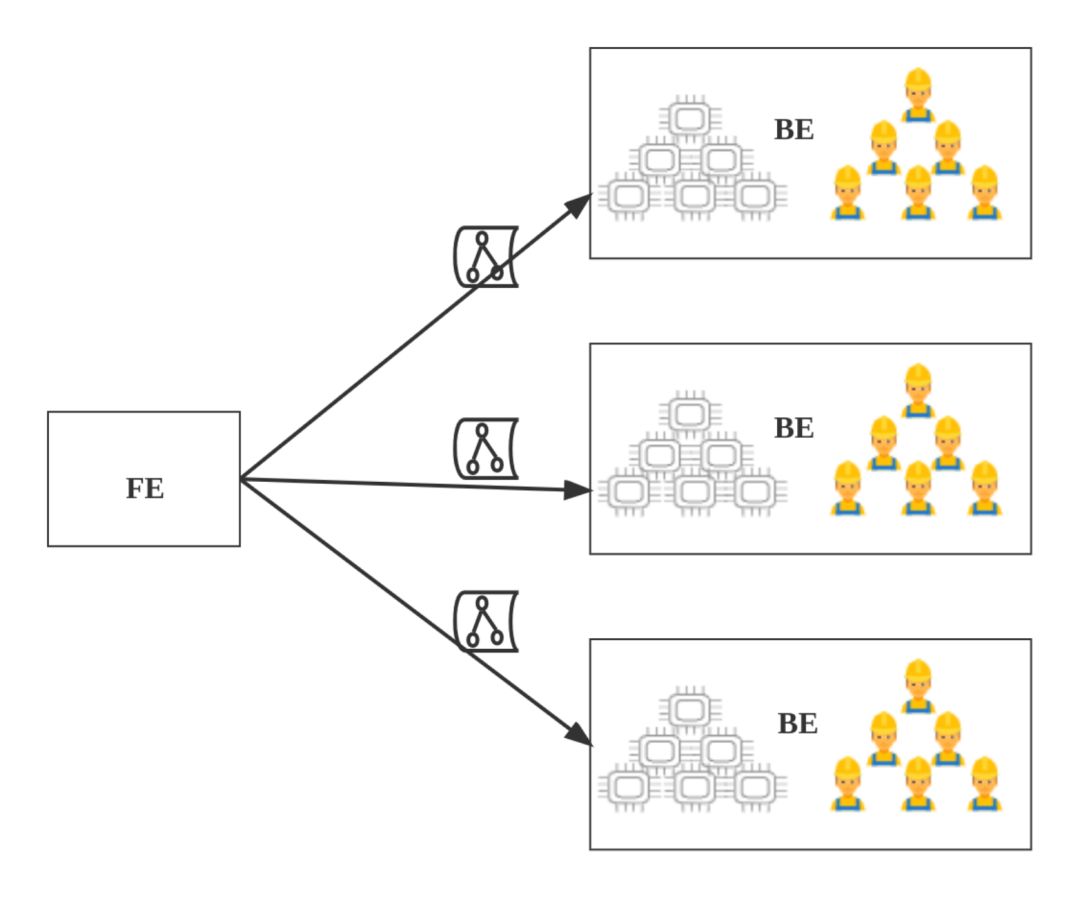
第三步:FE 将所有 Fragment Instance,一次性(all-at-once)投递给 BE,BE 执行 Fragment Instance。
3.Pipeline 调度基本概念
Pipeline
Pipeline 是一组算子构成的链,开始算子为 SourceOperator,末尾算子为 SinkOperator。Pipeline 中间的算子只有一个输入端和输出端。
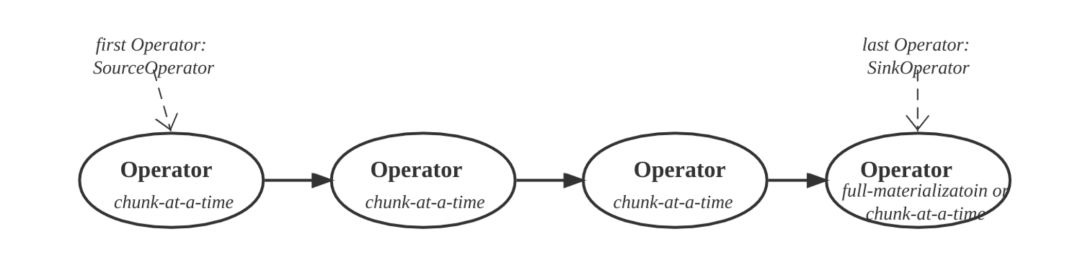
SourceOperator 作为 Pipeline 的起始算子,为 Pipeline 后续算子产生数据,SourceOperator 获取数据的途经有:
1. 读本地文件或者外部数据源,比如 ScanOperator;
2. 获得上游 Fragment Instance 的输出数据,比如 ExchangeSourceOperator;
3. 获得上游 Pipeline 的 SinkOperator 的计算结果,比如 LocalExchangeSourceOperator。
SinkOperator 作为 Pipeline 的末尾算子,吸收 Pipeline 的计算结果, 并输出数据,输出途经有:
1. 把计算结果输出到磁盘或者外部数据源,"比如OlapTableSinkOperator, ResultSinkOperator";
2. 把结果发给下游 Fragment Instance,比如 ExchangeSinkOperator;
3. 把结果发给下游 Pipeline 的 SourceOperator,比如 LocalExchangeSinkOperator;
Pipeline 的中间算子,既可获得前驱算子的输入,又可以输出数据给后继算子。
Pipeline 计算时,从前向后,先从 SourceOperator 获得 chunk, 输出给下一个算子,该算子处理 chunk,产生输出 chunk,然后输出给再下一个算子,这样不断地向前处理,最终结果会输出到 SinkOperator。对于每对相邻的算子, Pipeline 执行线程调用前一个算子 pull_chunk 函数获得 chunk,调用后一个算子的 push_chunk 函数将 chunk 推给它。Pipeline 的 SinkOperator 可能需要全量物化,而其他算子,则采用 chunk-at-a-time 的方式工作。
以 TPCH-Q5 为例,执行计划,可以划分成若干条 Pipeline,Pipeline 之间也存在上下游数据依赖。如下图所示:
- P2 依赖 P1
- P3 依赖 P2
- P6 依赖 P3,P4,P5
- P7 依赖 P6
- P8 依赖 P7
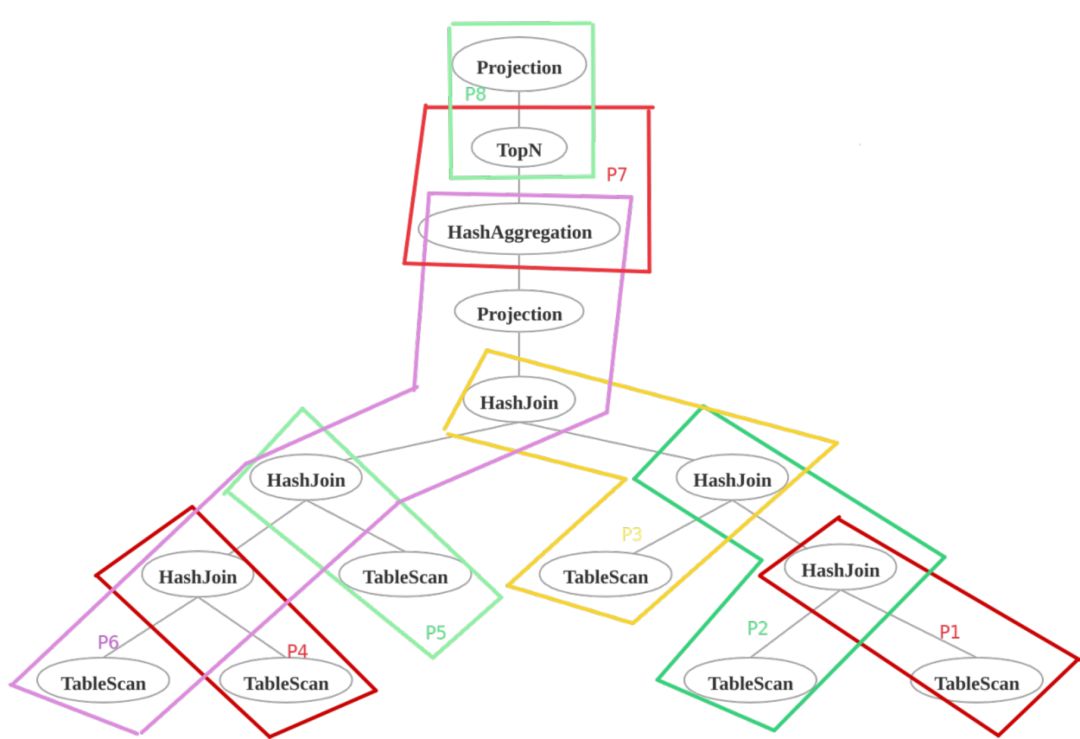
PlanFragment 为树状结构,需要进一步转换为 Pipeline。转换工作由 BE 上的 PipelineBuilder 完成,FE 本身对 Pipeline 无感知。一个 PlanFragment 可以拆分成若干条 Pipeline,相应地,PlanFragment 中的物理算子也需要转换为 Pipeline 算子,比如物理算子 HashJoinNode 需要转换为 HashJoinBuildOperator 和 HashJoinProbeOperator。
Pipeline 算子
Pipeline 算子是组成 Pipeline 的元素,BE 的 PipelineBuilder 拆分 PlanFragment 为 Pipeline 时,物理算子需要转换为成 Pipeline 算子。
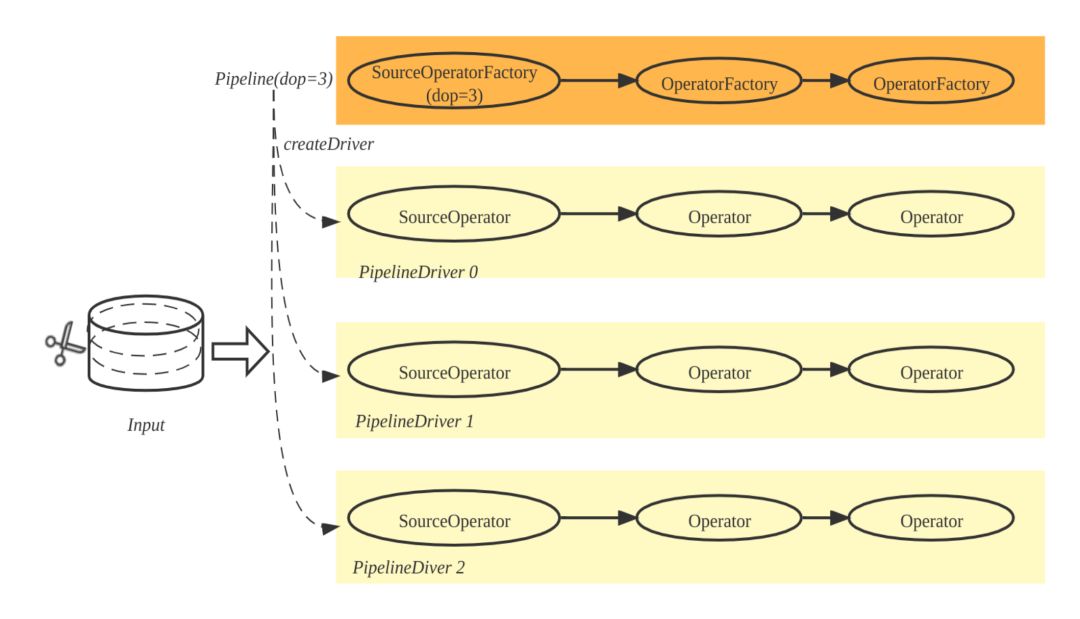
Pipeline 实例 (PipelineDriver)
PipelineDriver 是 Pipeline 实例,一条 Pipeline 可以产生多个 PipelineDriver。在代码实现中,Pipeline 由一组 OperatorFactory 构成, Pipeline 可以调用 OperatorFactory 的 create 方法,生成一组 Operator,这组 Operator 即构成 PipelineDriver。如下图所示,根据 dop=3(degree-of-parallelism),Pipeline 实例化 3 条 PipelineDriver,输入数据也被拆分成三部分,每个 PipelineDriver 各自处理一部分。
PipelineDriver 也是 Pipeline 执行引擎的基本调度单位,其本质上是一个协程,具有三种状态:Ready、Running 和 Blocked。
1. Pipeline 执行线程从就绪队列获得处于 Ready 状态的 PipelineDriver,设置状态为 Running,并执行;
2. PipelineDriver 自身不会阻塞并挂起执行线程,因为它的阻塞操作(比如网络收发,获取 Tablet 数据,读外表由其他的线程异步化处理。PipelineDriver 发起阻塞操作后,状态会被执行线程标记为 Blocked,并且主动让出 (yield)CPU,放回阻塞队列,执行线程从就绪队列选择其他的 PipelineDriver 执行。
3. 当 PipelineDriver 执行时间超过规定的时间片(如20ms), 则 PipelineDriver 也会 yield,此时 PipelineDriver 会被标记为 Ready 状态访问就绪队列,切换其他 Ready 状态的 PipelineDriver 执行。如下图所示:
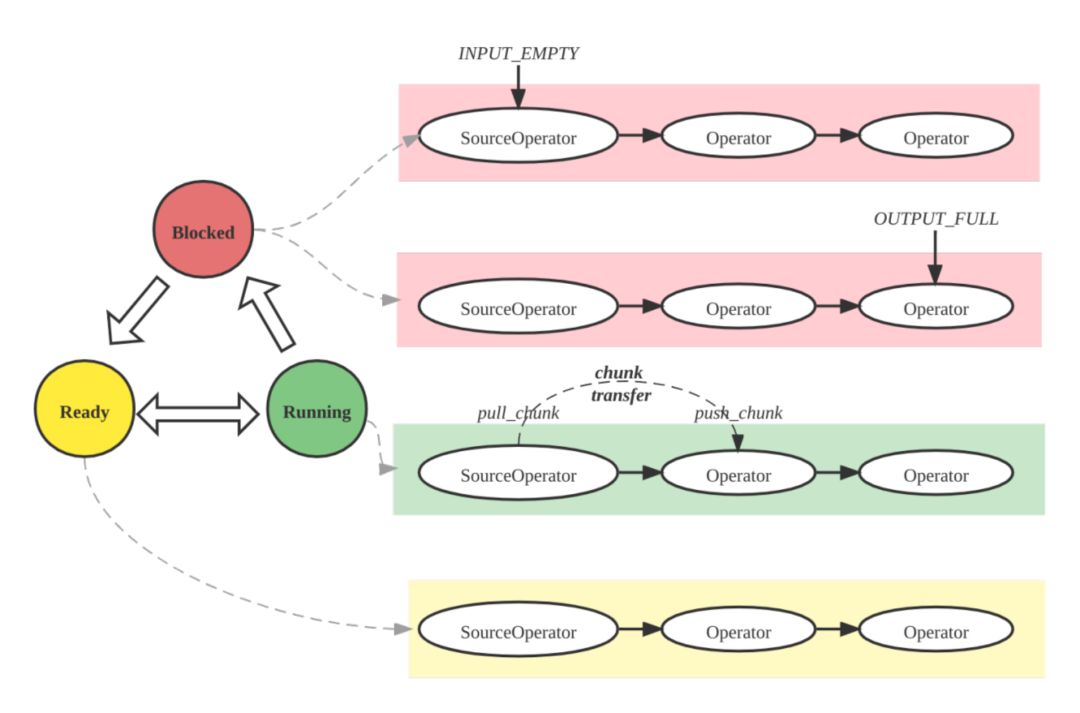
- Running:PipelineDriver 在当前执行线程中执行,执行线程反复调用相邻算子的 pull_chunk/push_chunk 函数移动 chunk。
- Blocked:PipelineDriver 处于阻塞状态,等待就绪事件,此时 PipelineDriver 不占用执行线程,被放置在阻塞队列中,由专门的 Poller 线程持续检查 PipelineDriver 的状态,当 PipelineDriver 等待的事件就绪后,状态设置为 Ready,放回就绪队列。
- Ready:PipelineDriver 执行时间超过时间片,会被放回就绪队列;阻塞解除的 PipelineDriver 也会放回就绪队列。执行线程从就绪队列中获得 PipelineDriver 并执行。执行线程的数量为计算节点 BE 的物理核数,而同时 BE 需要调度的 PipelineDriver 可能成千上万,因此执行线程是全局资源,跨所有查询,被所有的 PipelineDriver 所复用(multiplexing)。
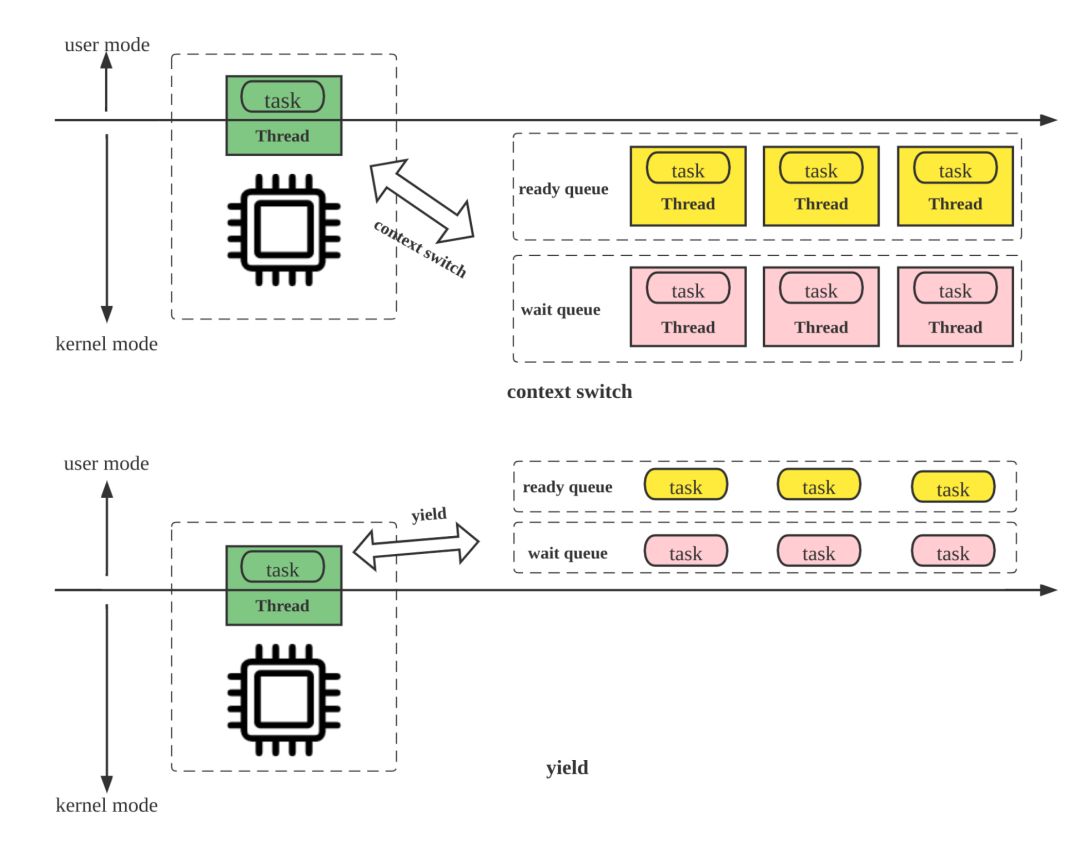
Pipeline 引擎中协程调度模型和传统的线程调度模型的主要区别是,前者实现了用户态的 yield 语义,而后者依赖 OS 的线程调度,在高并发场景下的频繁的上下文切换增加了调度成本,降低了 CPU 的有效利用率。如下图所示:
阻塞操作异步化
实现 Pipeline 执行引擎的协程调度,最为关键处理是阻塞操作异步化,如果没有实现异步化,PipelineDriver 的阻塞操作会导致执行线程陷入内核挂起,退化为 OS 线程调度。为了避免执行线程的上下文切换,需要控制执行线程的数量不超过物理核数,并且执行线程为跨查询的全局资源,这种阻塞挂起会显著影响 CPU 利用率和其他 PipelineDriver 的调度。 因此,涉及阻塞的操作,需要异步化处理,例如:
1. ScanOperator 读 Tablet 数据,访问磁盘。
2. ExchangeSinkOperator 发送数据,ExchangeSourceOperator 接收数据。
3. HashJoinProbeOperator 所在 PipelineDriver 等待 HashJoinBuildOperator 完成 HashTable 的构建和 RuntimeFilter 的生成。
4. 需要全量物化的物理算子拆分成一对 SinkOperator 和 SourceOperator,其中 SinkOperator 位于上游的 Pipeline,而 SourceOperator 位于下游的 Pipeline,SourceOperator 需要等待 SinkOperator 算子完成。比如物理算子 AggregateBlockingNode 转换为 Pipeline 引擎的 AggregateBlockingSinkOperator 和 AggregateBlockingSourceOperator,后者需要等待前者完成。
4.BE 负责 Pipeline 调度
BE 执行 PipelineDriver 使用两种类型的线程和两种队列,分别为 Pipeline 执行引擎的工作线程 PipelineDriverExecutor、阻塞态 PipelineDriver 的轮询线程 PipelineDriverPoller。队列分别为就绪 Driver 队列(Ready Driver queue)和阻塞 Driver 队列(Blocked Driver queue),如下图所示:
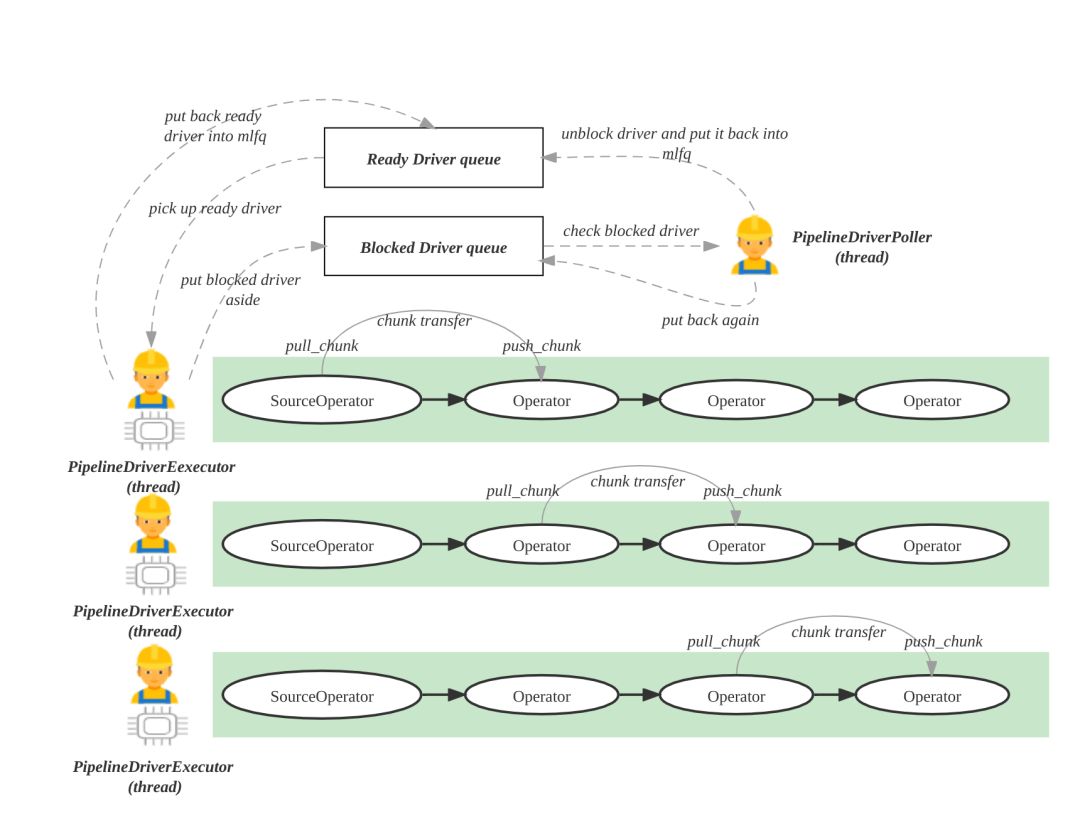
- 执行线程 PipelineDriverExecutor:不断地从就绪 Driver 队列中获得就绪态的 PipelineDriver 并执行,把主动让出 CPU 的PipelineDriver 再次放回就绪 Driver 队列,把处于阻塞态 PipelineDriver 放入阻塞 Driver 队列。
- 轮询线程 PipelineDriverPoller:不断地遍历阻塞 Driver 队列,跳过仍然处于阻塞态的 PipelineDriver,将解除阻塞态的 PipelineDriver,设置为 Ready 状态,放回就绪 Driver 队列。
本文主要讲解了 Pipeline 执行引擎想解决的问题及一般性原理。
关于 Pipeline 执行引擎的实现, BE 端拆分 Pipeline 的逻辑,以及 Pipeline 实例 PipelineDriver 的调度执行逻辑, StarRocks Pipeline 执行框架(下)见!


