
CloudCanal 落地 StarRocks 数据迁移同步的实践与思考
本文发表于: &{ new Date(1679241600000).toLocaleDateString() }
一、CloudCanal 是什么
三年前,我和我的伙伴们意识到中国的数据库行业的巨大发展潜力,我们一直认为,国内的数据库生态将迎来蓬勃的发展,将这些数据库生态打通是非常有意义的。于是我们一起创建了数据迁移同步工具 CloudCanal 。
在过去半年多的时间里,ClouGence 和 StarRocks 团队一起合作,围绕 StarRocks 构建数据生态。在这个过程中,落地了很多用户场景,并且获得了相关的实践经验以及思考。
1.CloudCanal 核心能力
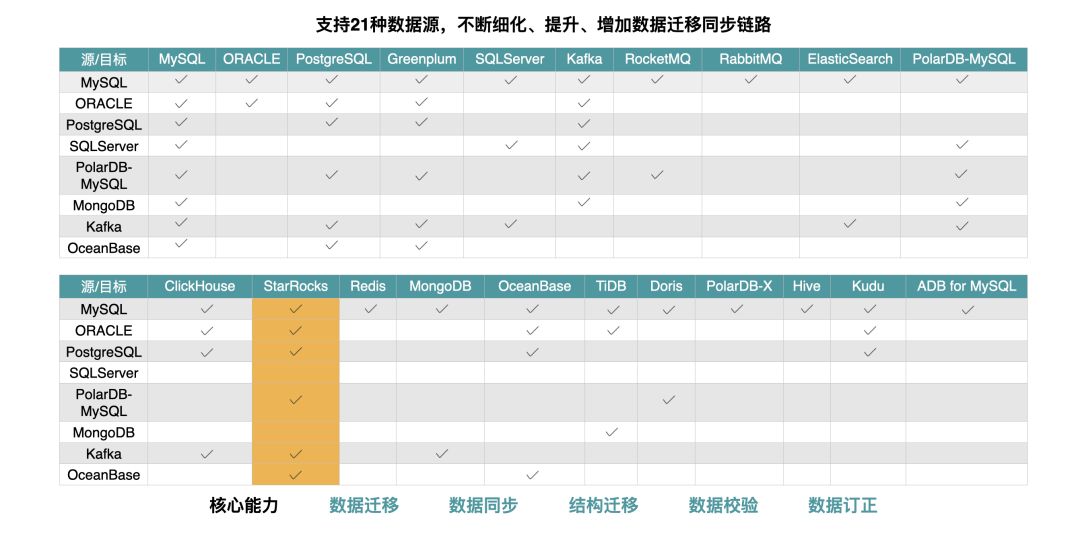
CloudCanal 的核心功能包括数据迁移和数据同步,并且具备结构迁移、数据校验、数据订正的能力。目前支持21种主流数据源,并且在不断细化、提升、增加数据迁移同步链路。
基于以上能力,CloudCanal 在相对较短的时间之内,将源端的 MySQL、Oracle、PostgreSQL、PolarDB-MySQL、Kafka、OceanBase 等数据,顺畅、稳定地迁移同步到 StarRocks 中,给 StarRocks 的数据生态带来了非常大的变化。
2.CloudCanal 应用场景
场景一:IOT领域
场景特点:
- 采集标准
- 低成本存储
- 轻量级传输
- 非结构化数据
CloudCanal 的应用:
在 IOT 领域,CloudCanal 主要帮助业务从消息中间件中,将数据同步到时空时序数据库、大数据、数据湖等数据库中。

CloudCanal 在 IOT 领域的应用
场景二:数据智能领域
场景特点:
- 大数据
- 批量/流式
- 任务调度
- 元数据治理
CloudCanal 的应用:

CloudCanal 在数据智能领域的应用在数据智能领域,CloudCanal 可帮助用户从消息系统及主数据库系统中,实时或 T+1 将数据迁移到数据仓库、大数据、数据湖等数据库中, 以供业务进行交互式分析、BI 等动作。
场景三:业务运营
场景特点:
- 数据实时性要求高
- 数据准确性要求高
- 高并发
- 高稳定性
CloudCanal 在该方向投入了非常多的精力去保障这些场景特点,包括从主数据库中迁移同步数据到缓存、消息中间件以及实时数仓,满足业务对数据的要求。

CloudCanal 在业务运营中的应用
场景四:业务改造/容灾
场景特点:
- 异构
- 异地
- 数据转换处理

CloudCanal 在业务改造及容灾中的应用
在业务改造及容灾方向上,有很多典型的场景,如业务架构升级、换数据库、做异构的数据转换、灾备/多活数据库等。CloudCanal 在这些场景中,不仅可以帮用户做基础数据迁移、同步的工作,也会帮用户做数据过滤、转换、生成、防循环等工作。
CloudCanal 跟 StarRocks 的合作主要是在数据智能、业务运营方向;在交互式分析、BI 以及实时/离线报表领域应用较多。
3.CloudCanal 产品特点
- 可视化 零代码 全自动
数据迁移同步是一件非常复杂的事情,如果我们用开源工具或脚本或自己去开发,对业务人员和开发人员都很棘手。而使用 CloudCanal ,通过页面上的点击即可达成目标,实现开发、DBA、业务人员都能用。
- 可观测
因为我们的产品涉及到数据同步和业务稳定性,所以系统的可观测是极其重要的。可观测性可以通过三个维度来解读。
- 告警可靠:当出现问题的时候,我们的告警是可靠且及时的;
- 调优有据:可以通过监控指标去做调优;
- 风险可控 :让 DBA、开发运维同学能够对数据迁移同步工具有信心。
- 云原生
CloudCanal 对云原生的理解其实是对业务的未来形态的理解,我们认为业务必定会有一部分在云上,而且要做云上云下以及混合云的一些场景,对于云资源的整合和使用应该是平滑的。我们希望用 API 级别的集成,达到如同云厂商方的产品的流畅度,甚至更优。
4.CloudCanal 用户群体
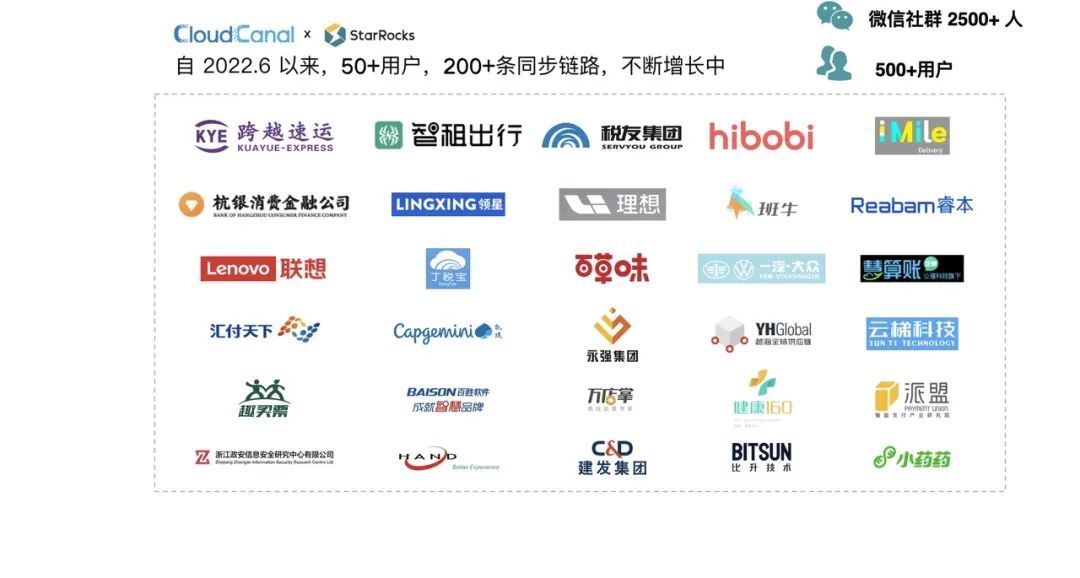
在两年多的时间里,CloudCanal 积累了500多家用户,包括理想汽车、百草味等。同时,我们构建了数千人的专属社群,且在不断壮大之中。
在和 StarRocks 合作的近半年中,我们积累了50+ 用户,200条同步链路,且仍在不停增长。CloudCanal 跟 StarRocks 一起给用户带来的价值也在不断增加。
二、CloudCanal 落地 StarRocks 数据迁移同步
1.StarRocks 对端使用过程
StarRocks 对端的使用过程相当流畅,所有的链路 — 包括 MySQL 到 StarRocks,Oracle 到 StarRocks,PostgreSQL 到 StarRocks,均是如下步骤。
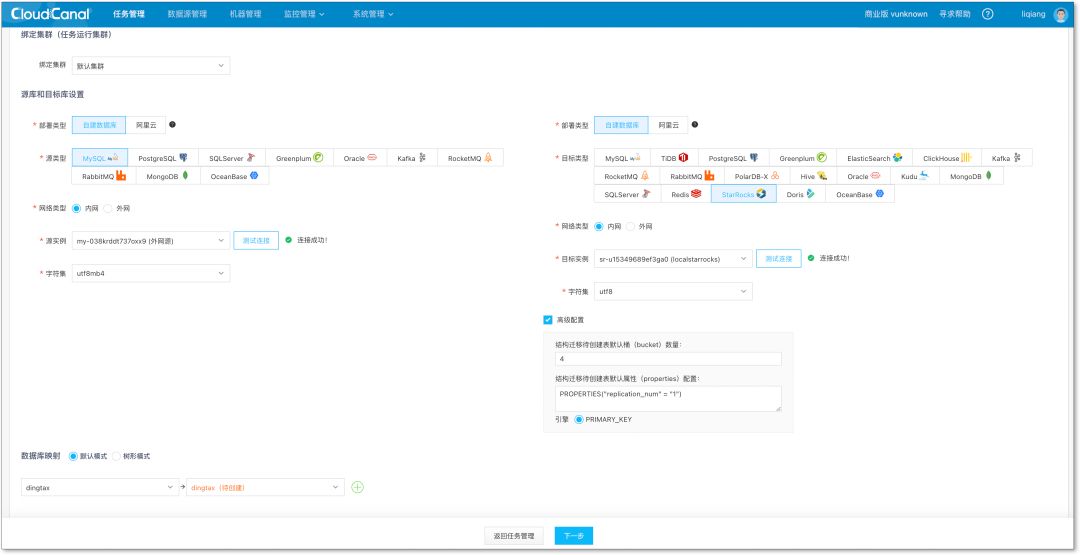
1.选择数据库
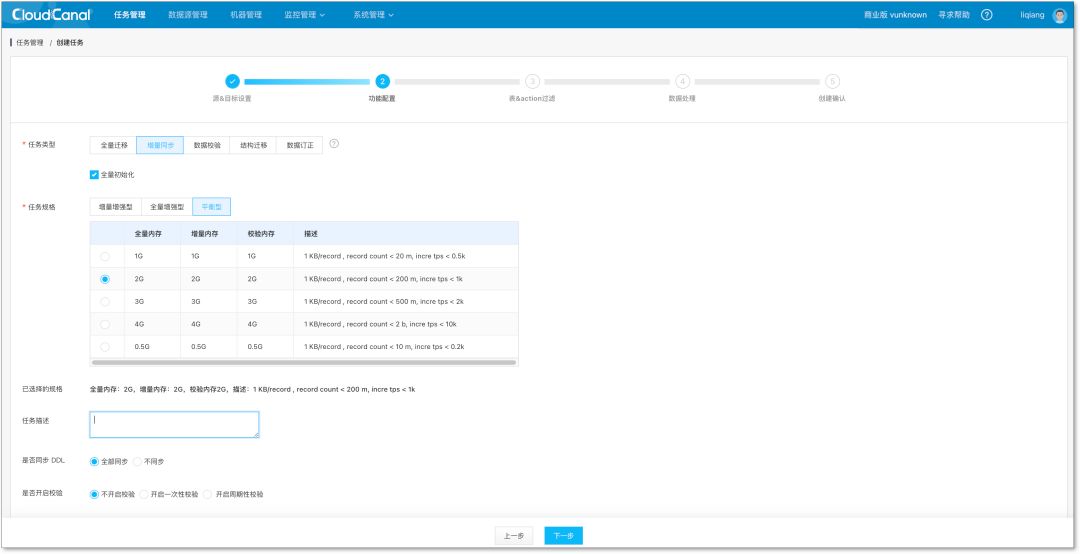
2.选择任务属性: 比如,是做迁移还是同步,还是做解构的一些准备。还要确定同步任务的规格以及描述等信息。
3.选择表/ topic / collection:选择迁移的对象,选择对迁移对象动作的订阅。
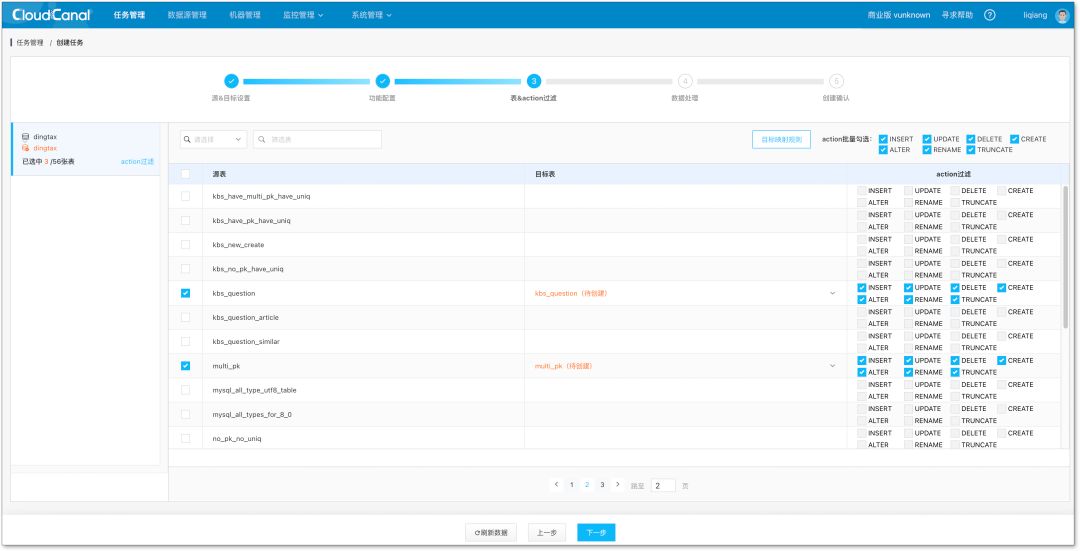
4.选择列/ Field:选择列以及做一些数据处理,这个步骤可以上传自己代码,对数据做更加复杂的变换、过滤等动作。
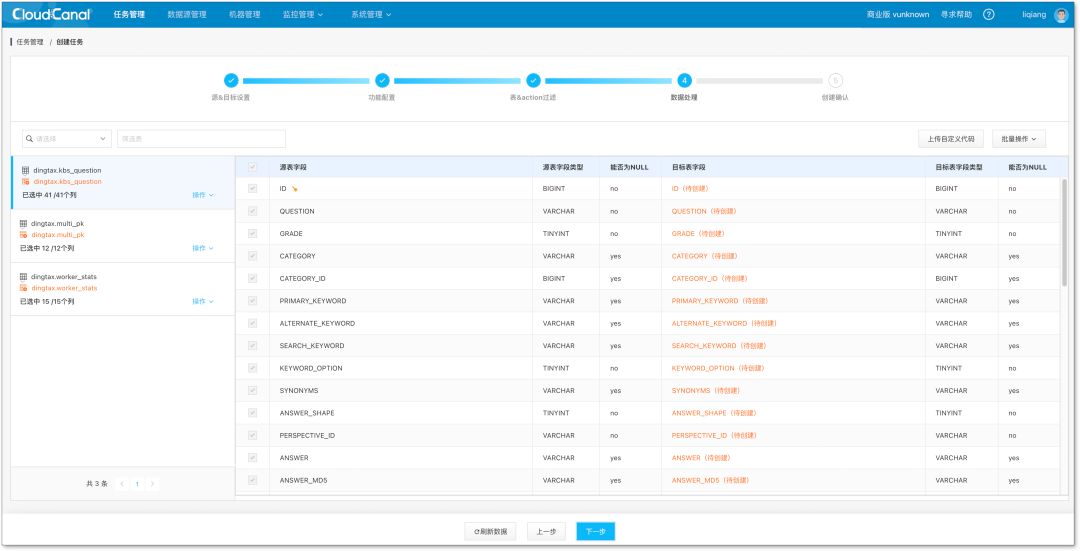
5.创建任务:做完以上这五步,对数据迁移同步的配置即将结束。
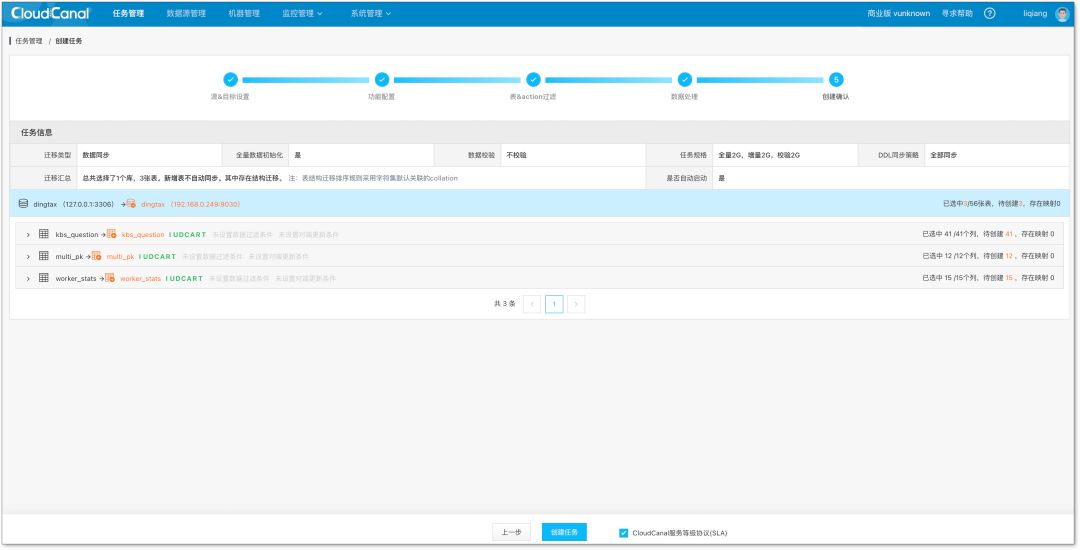
6.结构迁移、全量迁移、增量同步:这是一个全自动化的过程,该过程中可能包含以下几种情形。
- 如果对端建一些表,包括同构或者异构,CloudCanal 将会启动一个任务,去做结构迁移的准备;
- 如果需要在任务中做数据的初始化,CloudCanal 将启动一个迁移进程,将数据准备好;
- 最后当迁移完后,CloudCanal 会启动增量任务,去追赶已经落后的增量数据,直至达到一个稳态的程度。

2.StarRocks 对端的基础能力
现用户对于数仓有以下需求:
- 用户可以放弃部分的事务性,但是对数据写入即可查相当在意。
- 数仓需要实时,且强一致。
- 解决现在多数数仓的痛点:在做增量写入之后,会多出来数据,需要等待系统合并或手动合并。
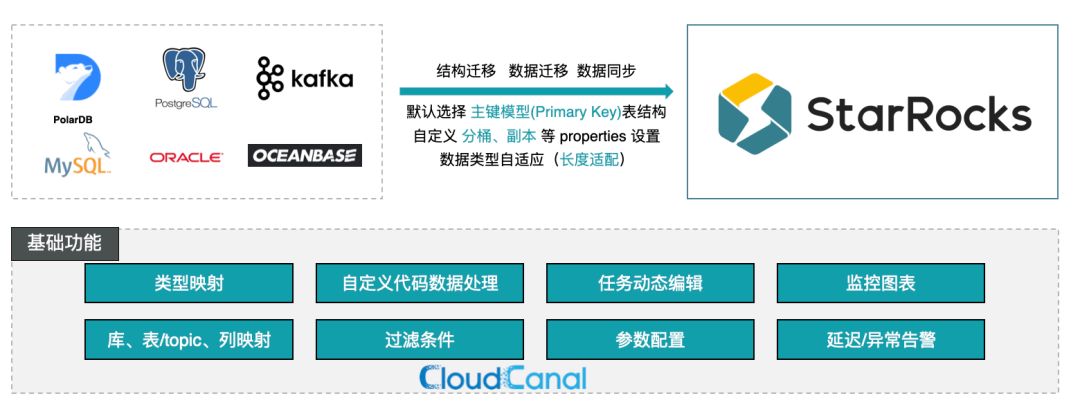
StarRocks解决方案 — 写入即合并:
这个能力是通过主键模型的表结构实现的:CloudCanal 在接入 StarRocks 的时候,直接选择了这个主键模型,再辅以自定义分桶、副本等 properties 设置,以及数据类型自适应(长度适配),让 StarRocks 的核心功能更加丰满,再搭配 CloudCanal 的基础功能,包括:类型映射、自定义代码数据处理、任务动态编辑、监控图表等等,让整条链路丰满起来,也让 StarRocks 能够非常顺滑地接入 CloudCanal 数据实时互通体系中。
3.StarRocks 对端写入优化
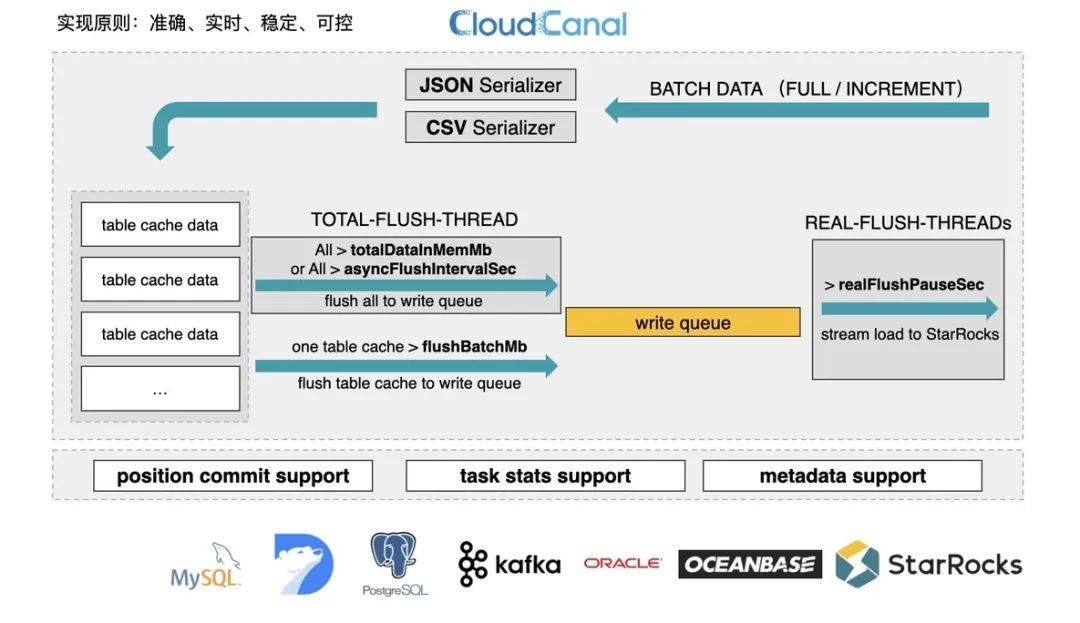
无论是全量的数据,还是通过各种日志解析、增量日志的查询,这些数据其实都会通过我们的序列化器,放到分层的 cache 系统中。对 StarRocks 而言,如何尊重其最佳写入方式,是所有数据迁移同步工具必须要做到的事情。
在实现对端的写入优化上,CloudCanal 以准确、实时、稳定、可控四个目标去落地。为了实现这四个目标,在用户的数据场景各异,每条数据长度不同,每个数据库来源的 IPS 或者流量也不同的情况下,我们通过4个参数使其可配置可优化。
- totalDataInMemMb:这是我们描述整个内存中数据容量的一个参数。当整个数据容量大于该值的时候,将刷出数据到 StarRocks 中。
- asyncFlushIntervalSec:当满足这个参数的时候,也就是发出间隔时间的时候,我们也会发出到StarRocks中。
- flushBatchMb:有时,某些表是热点表,数据增长非常快。这个时候,我们还会有另外一个参数去单独控制表的阈值 — 即 flushBatchMb。当满足该值的时候,我们将会把这张表的缓存数据刷出到 StarRocks 中。
- realFlushPauseSec:在真正刷出的时候,由于 StarRocks 本身对于数据写入频次的一些要求,我们又设置了另外一个参数去防止写入过快的发生 — realFlushPauseSec,可以设成0秒钟,即不停顿,也可以设置一秒两秒等等。
通过一整套体系的构建,我们的用户对于稳定性相当满意。对于出现问题的链路,我们也可以通过调整这些参数以及调整配套的体系去达到稳定的目的。
4.CloudCanal x StarRocks 客户成功案例
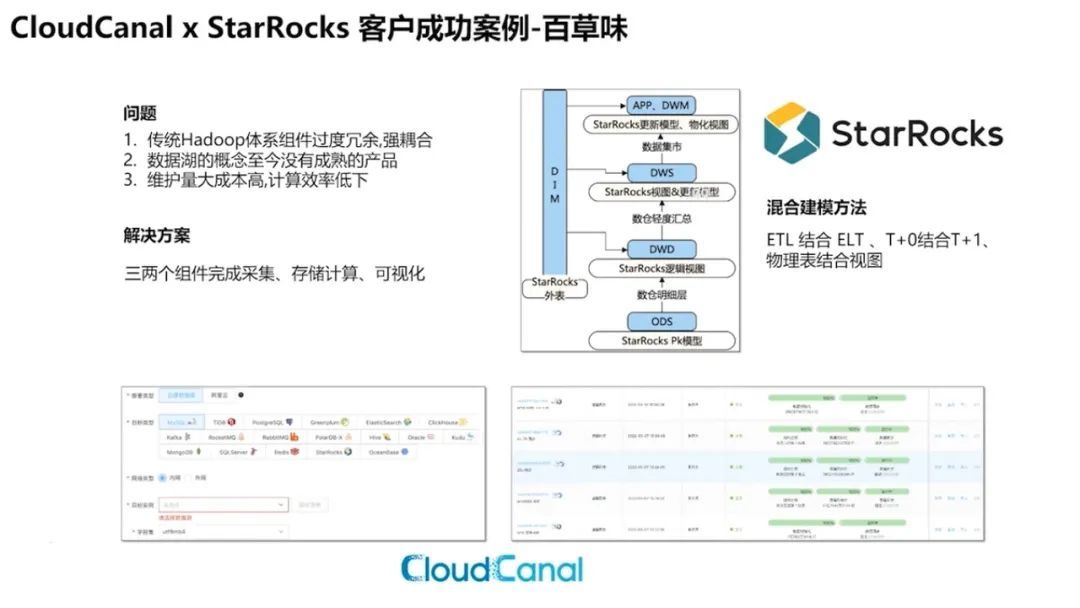
StarRocks 和 CloudCanal 一起去构建的数据体系是如何应用于用户层面的呢?在这里举一个百草味的例子。
用户痛点:
- 传统 Hadoop 体系组件过度冗余,强耦合。
- 数据湖的概念至今没有成熟的产品。
- 维护量大成本,计算效率低下。
解决方案:
我们通过 CloudCanal 实时以及定时的方式,将数据同步迁移到 StarRocks 中,以 StarRocks PK 模型为 ODS 层的主数据模型,往上辅以逻辑视图以及各种更新模型等表结构,达到DWD 及 DWS 层的构建目的。最后通过数据及时开放给 APP 使用。
我们大量的数据其实并没有达到需要用特别复杂的架构去支撑的地步,但是今天我们却可以通过 StarRocks 加 CloudCanal 去实现一套非常具备业务可能性的数据架构。
这套方案既有实施的可能性,对于百亿以下的数据也起到了非常好的示范作用。
三、未来展望
在过去一年中,CloudCanal 跟 StarRocks 有了很多实践,达成了很多合作,给用户也带来了诸多益处。我相信像 StarRocks 这样优秀的产品未来会给用户带来更大的好处。我们也希望 CloudCanal 能和 StarRocks 一起合作,一起去打造一个新的数据生态。
关于 StarRocks
StarRocks 是数据分析新范式的开创者、新标准的领导者。面世三年来,StarRocks 一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业构建极速统一的湖仓分析新范式,是实现数字化转型和降本增效的关键基础设施。
StarRocks 持续突破既有框架,以技术创新全面驱动用户业务发展。当前全球超过 200 家市值 70 亿元以上的头部企业都在基于 StarRocks 构建新一代数据分析能力,包括腾讯、携程、平安银行、中原银行、中信建投、招商证券、众安保险、大润发、百草味、顺丰、京东物流、TCL、OPPO 等,并与全球云计算领导者亚马逊云、阿里云、腾讯云等达成战略合作伙伴。
拥抱开源,StarRocks 全球开源社区飞速成长。截至 2022 年底,已有超过 200 位贡献者,社群用户近万人,吸引几十家国内外行业头部企业参与共建。项目在 GitHub 星数已超 4100 个,成为年度开源热力值增速第一的项目,市场渗透率跻身中国前十名。


