
技术内幕 | StarRocks Pipeline 执行框架(下)
本文发表于: &{ new Date(1666195200000).toLocaleDateString() }
导读:欢迎来到 StarRocks 技术内幕系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你快速上手这款明星开源数据库产品。本期 StarRocks 技术内幕将主要介绍 StarRocks Pipeline 执行框架的基本概念、原理及代码逻辑。
StarRocks Pipeline 执行框架(上)篇中,主要为大家讲解了 Pipeline 执行引擎想解决的问题及一般性原理。关于 Pipeline 执行引擎的实现, BE 端拆分 Pipeline 的逻辑,以及 Pipeline 实例 PipelineDriver 的调度执行逻辑,将在本篇中继续与大家分享。
#01 背景介绍
详见 StarRocks Pipeline 执行框架(上)篇
#02 基本概念
详见 StarRocks Pipeline 执行框架(上)篇
#03 源码解析
章节二的基本概念输入完以后,我们开始从以下几个方面解析 StarRocks 的源码:
1. BE 初始化 Pipeline 执行引擎:主要介绍 BE 启动后,如何初始化 Pipeline 执行引擎的全局资源。
2. BE 端 Query 生命周期管理:主要介绍在 BE 上,如何用 QueryContext 管理所属的全体 Fragment Instance,以及 Fragment Instance 的准备、执行和销毁逻辑。
3. 物理算子拆分 Pipeline 算子:算子拆分逻辑在 Pipeline 执行引擎中占比很重,涉及到每个算子的重构,后续添加新算子,需要遵从一定的原则拆分算子,为 Pipeline 算子的接口定义正确的语义。
4. PipelineDriver 的调度逻辑:主要涉及到 PipelineDriver 的 Ready、Blocked 和 Running 三种状态的转换。
1.BE 初始化 Pipeline 执行引擎
- BE 初始化全局对象的方法主要有两种:
将全局对象定义在 ExecEnv 对象中,参考 be/src/runtime/exec_env.h,be/src/runtime/exec_env.cpp文件。 - 定义全局性的单例(Singleton)对象,例如 be/src/exec/pipeline/query_context.cpp,如果对象本身可以独立完成初始化、不依赖参数设置、不依赖于其他对象的初始化顺序,则可以定义为单例。
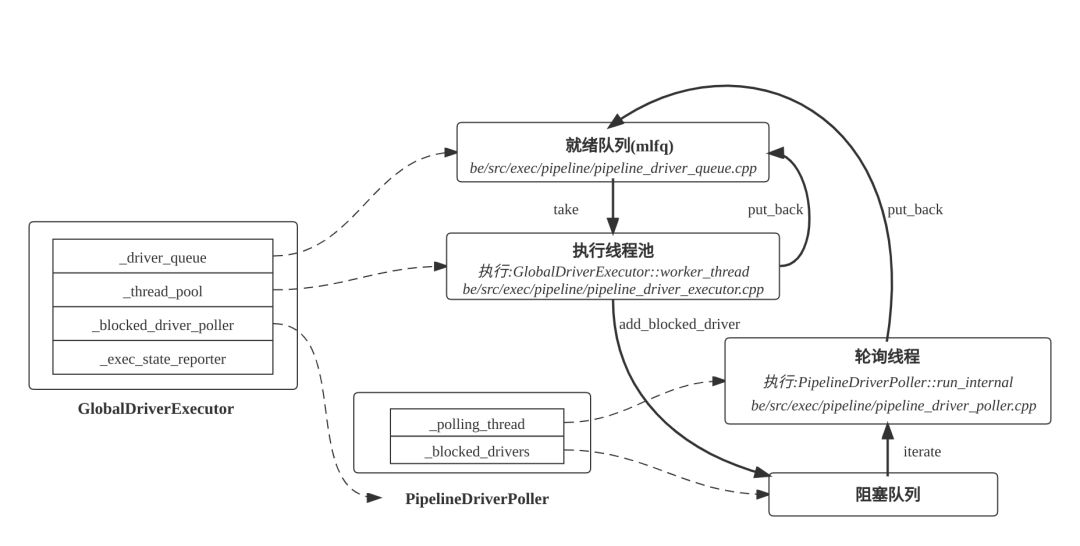
Pipeline 执行引擎的全局性对象
PipelineDriver 执行器
定义为 ExecEnv::_driver_executor,类型为 pipeline::GlobalDriverExecutor,主要由执行线程池和轮询线程构成。其中执行线程的数量默认为机器的硬件核数,轮询线程数量为 1。
// 源码文件: be/src/runtime/exec_env.cpp
// 函数: Status ExecEnv::_init(const std::vector<StorePath>& store_paths)
std::unique_ptr<ThreadPool> driver_executor_thread_pool;
auto max_thread_num = std::thread::hardware_concurrency();
if (config::pipeline_exec_thread_pool_thread_num > 0) {
max_thread_num = config::pipeline_exec_thread_pool_thread_num;
}
LOG(INFO) << strings::Substitute("[PIPELINE] Exec thread pool: thread_num=$0", max_thread_num);
RETURN_IF_ERROR(ThreadPoolBuilder("pip_executor") // pipeline executor
.set_min_threads(0)
.set_max_threads(max_thread_num)
.set_max_queue_size(1000)
.set_idle_timeout(MonoDelta::FromMilliseconds(2000))
.build(&driver_executor_thread_pool));
_driver_executor = new pipeline::GlobalDriverExecutor(std::move(driver_executor_thread_pool), false);
_driver_executor->initialize(max_thread_num)pipeline::GlobalDriverExecutor 的结构如下:
Pipeline IO 线程池
ExecEnv._pipeline_scan_io_thread_pool,主要用于执行 ScanOperator 读数据操作的异步化 IO 任务。IO 线程池队列大小和线程数目,取决于参数:
- config::pipeline_scan_thread_pool_queue_size
- config::pipeline_scan_thread_pool_thread_num
// 源码文件: be/src/runtime/exec_env.cpp
// 函数: Status ExecEnv::_init(const std::vector<StorePath>& store_paths)
int num_io_threads = config::pipeline_scan_thread_pool_thread_num <= 0
? std::thread::hardware_concurrency()
: config::pipeline_scan_thread_pool_thread_num;
_pipeline_scan_io_thread_pool =
new PriorityThreadPool("pip_scan_io", // pipeline scan io
num_io_threads, config::pipeline_scan_thread_pool_queue_size);WorkGroup(即资源组 ResourceGroup)执行器
定义为 ExecEnv._wg_driver_executor,WorkGroup 用于 Pipeline 执行引擎的资源隔离,主要的设计动机是为了把不同业务场景的 Workload 划分到相应的 WorkGroup中,每个 WorkGroup 有自己的 CPU、Memory 和并行数量资源 Quota。 每个 WorkGroup 按照资源 Quota 的限制复用计算资源,从而实现隔离性。(WorkGroup 的详细源码分析请参考专门解析文档,此处提及,是为了保证本文的完整性。) WorkGroup 执行器和 PipelineDriver 执行器功能类似,实现了基于 WorkGroup 的调度逻辑。
WorkGroup Scan 执行器
定义为ExecEnv._scan_executor,也用于 WorkGroup 功能,类似 Pipeline IO 线程池,该执行器可以根据 WorkGroup 的资源 Quota 限制,执行 ScanOperator 提交的异步化 IO 任务。
QueryContextManager
QueryContext 管理一个查询在某台执行节点上的全体 Fragment Instance,QueryContextManager 顾名思义就是对 QueryContext 进行操作,主要用于其生命周期的管理。参考源码文件:be/src/exec/pipeline/query_context.cpp。
WorkGroupManager
WorkGroupManager 用于管理 WorkGroup,详见 WorkGroup 相关文档。
2.BE 端 Query 生命周期管理
QueryContext 和 FragmentContext
计算节点 BE 为查询维护下列对象:
- QueryContext:在 QueryContextManager 中注册,拥有 FragmentContextManager 对象管理 Fragment Instance。
- FragmentContext:在QueryContext.fragment_mgr 中注册,每个 Fragment Instance 对应一个 FragmentContext。
- Pipelines:FragmentContext 包含一组 Pipeline,来源于 Fragment Instance 的执行子树的拆解。
- Drivers:FragmentContext 包含一组 PipelineDriver,PipelineDriver 通过 Pipeline 创建,来自同一个 Pipeline 的 PipelineDriver 的数量,取决于 Pipeline 并行度。
- MorselQueues:ScanOperator 和 MorselQueue 的映射表,MorselQueue 包含一组 Morsel,Morsel 是 ScanOperator 读取数据的分片。
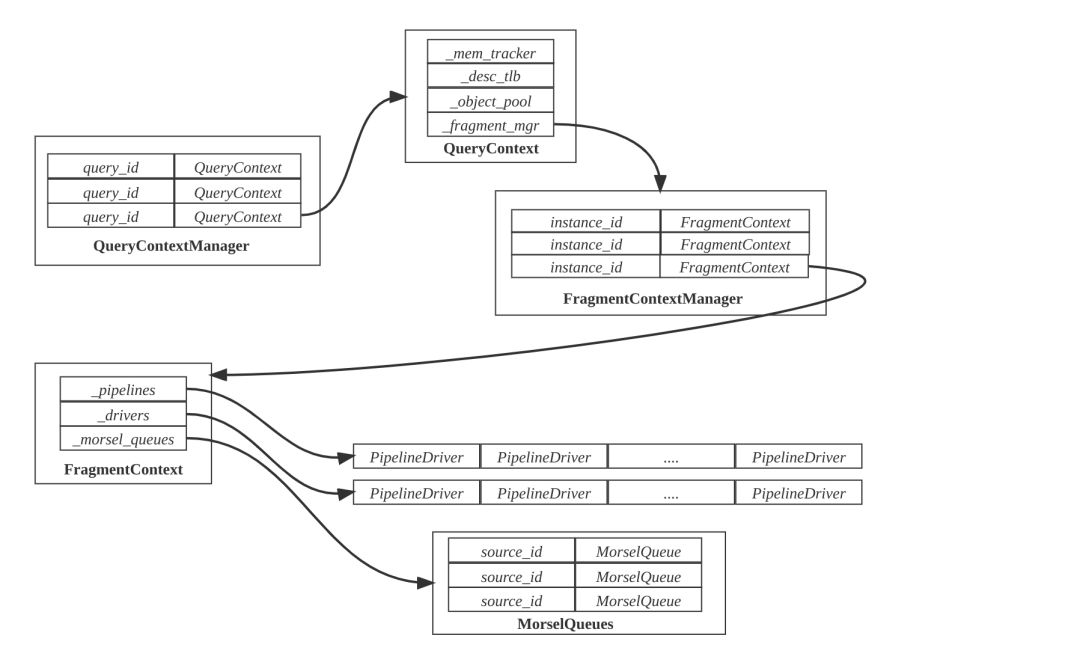
QueryContext 的生命周期比 FragmentContext 生命周期久,跨所有 Fragment Instance,属于 Query 层面的对象,可以由 QueryContext 管理。比如控制 Query 内存使用 MemTracker,所有 Fragment Instance 共享的 DescriptorTable。FragmentContext 只管理 Fragment Instance 范围的资源,主要包括 Pipelines、PipelineDrivers 和 MorselQueues。
只有当 FragmentContext 中的所有 PipelineDriver 都完成计算,FragmentContext 的生命周期才结束;只有当所有 FragmentContext 的生命周期结束,QueryContext 的生命周期才结束。QueryContext 生命周期结束后,就可以析构并且释放 QueryContext 占用的资源。
Fragment Instance 执行逻辑的入口
BE 收到来自 FE 的 exec_plan_fragment 后,创建 FragmentExecutor 执行该 Fragment Instance,代码如下:
// 文件:/home/grakra/workspace/sr/be/src/service/internal_service.cpp
template <typename T>
void PInternalServiceImpl<T>::exec_plan_fragment(google::protobuf::RpcController* cntl_base,
const PExecPlanFragmentRequest* request,
PExecPlanFragmentResult* response, google::protobuf::Closure* done) {
ClosureGuard closure_guard(done);
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
auto st = _exec_plan_fragment(cntl);
if (!st.ok()) {
LOG(WARNING) << "exec plan fragment failed, errmsg=" << st.get_error_msg();
}
st.to_protobuf(response->mutable_status());
}PInternalServiceImpl::exec_plan_fragment 调用 _exec_plan_fragment:
// 文件:/home/grakra/workspace/sr/be/src/service/internal_service.cpp
template <typename T>
Status PInternalServiceImpl<T>::_exec_plan_fragment(brpc::Controller* cntl) {
auto ser_request = cntl->request_attachment().to_string();
TExecPlanFragmentParams t_request;
{
const uint8_t* buf = (const uint8_t*)ser_request.data();
uint32_t len = ser_request.size();
RETURN_IF_ERROR(deserialize_thrift_msg(buf, &len, TProtocolType::BINARY, &t_request));
}
bool is_pipeline = t_request.__isset.is_pipeline && t_request.is_pipeline;
LOG(INFO) << "exec plan fragment, fragment_instance_id=" << print_id(t_request.params.fragment_instance_id)
<< ", coord=" << t_request.coord << ", backend=" << t_request.backend_num
<< ", is_pipeline=" << is_pipeline << ", chunk_size=" << t_request.query_options.batch_size;
if (is_pipeline) {
auto fragment_executor = std::make_unique<starrocks::pipeline::FragmentExecutor>();
auto status = fragment_executor->prepare(_exec_env, t_request);
if (status.ok()) {
return fragment_executor->execute(_exec_env);
} else {
return status.is_duplicate_rpc_invocation() ? Status::OK() : status;
}
} else {
return _exec_env->fragment_mgr()->exec_plan_fragment(t_request);
}
}当采用 Pipeline 执行引擎时,创建 FragmentExecutor,完成下列操作:
- 调用 FragmentExecutor::prepare 函数, 初始化 Fragment Instance 的执行环境,创建和注册 QueryContex、FragmentContext,将Fragment Instance 拆分成 Pipelines,创建 PipelineDrivers。
- 调用 FragmentExecutor::execute 函数,向 Pipeline 执行线程提交 PipelineDrivers 运行。
FragmentExecutor::prepare 函数
参考 be/src/exec/pipeline/fragment_executor.cpp,主要的逻辑如下:
1. 判断 Fragment Instance 是否为重复投递,如果是,直接返回错误状态 Status::DuplicateRpcInvocation。
2. 注册或获得已有的 QueryContext,处理 Query 的第一个 Fragment Instance 时,注册 QueryContext,后续到达的 Fragment Instance 复用已注册的 QueryContext。设置 QueryContext 需要处理的 Fragment Instance 的数量和 Query 过期时间等参数,Query 过期时间用于自动取消长期得不到执行的 Query;如果 Query 有大量的 Fragment Instance,先到达的部分 Fragment Instance 完成执行而退出,在没有活跃的 Fragment Instance 的情况下,QueryContext 依然需要保留一段时间,等到后续 Fragment Instance 全部达到或者自动过期而取消执行。
3. 创建和初始化 FragmentContext 对象,FragmentContext 需要注册到 QueryContext.fragment_mgr 中,注册的时机为 FragmentContext::prepare 函数的末尾。因为有的异步逻辑(比如 Global Runtime Filter 的投递),需要访问 FragmentContext 的成员变量,在 FragmentContext 未完成所有的初始化之前注册,会对异步逻辑暴露 FragmentContext,导致访问未初始化的成员变量而出错。
4. 调用函数 Exec::create_tree 生成 Non-pipeline 执行树,使用 PipelineBuilder 将执行树拆解成为 Pipeline。
5. 调用 convert_scan_range_to_morsel 函数将 ScanNode 需要访问的 TScanRangeParams 转换为 ScanOperator 可访问的 Morsel。
6. 将 Non-pipeline 执行引擎的 DataSink 转换为 Pipeline 引擎的 SinkOperator,调用 _decompose_data_sink_to_operator
7. 根据 DOP(degree-of-parallelism),为 Pipeline 创建 PipelineDriver,并且将 MorselQueue 和相应的 ScanOperator 关联。
8. 完成其他的必要的初始化,并且注册 FragmentContext。
FragmentExecutor::execute函数
//文件: be/src/exec/pipeline/fragment_executor.cpp
Status FragmentExecutor::execute(ExecEnv* exec_env) {
for (const auto& driver : _fragment_ctx->drivers()) {
RETURN_IF_ERROR(driver->prepare(_fragment_ctx->runtime_state()));
}
if (_fragment_ctx->enable_resource_group()) {
for (const auto& driver : _fragment_ctx->drivers()) {
exec_env->wg_driver_executor()->submit(driver.get());
}
} else {
for (const auto& driver : _fragment_ctx->drivers()) {
exec_env->driver_executor()->submit(driver.get());
}
}
return Status::OK();
}
FragmentExecutor::execute 函数的主要操作如下:
1. 变量 FragmentContext 中的所有 PipelineDriver,执行 PipelineDriver::prepare 函数。该函数主要完成 PipelineDriver 范围的 profile 注册、调用每个算子的 prepare 函数、设置 Driver 之间前置等待条件,比如 HashJoin 左侧的 PipelineDriver 需要等待右侧 PipelineDriver 完成,消费 RuntimeFilter 的 PipelineDriver 需要等待生产 RuntimeFilter 的 PipelineDriver 完成。
2. 把 PipelineDriver 提交给 Pipeline 执行线程。PipelineDriver 提交后,FragmentExecutor 的生命周期结束,FragmentExecutor 是临时性的,禁止在 FragmentExecutor 中定义 PipelineDriver 可引用的对象。
3.PipelineBuilder 拆分 pipeline
BE 上的 PipelineBuilder 会把 PlanFragment 拆分成多个 Pipeline,拆分过程中,PlanFragment 中物理算子会转化为 Pipeline 算子。
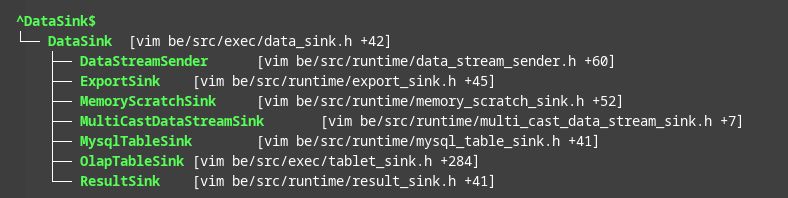
物理算子
物理算子是 ExecNode 的子类,FE 投递给 BE 的 Fragment Instance 中,包含构成所属 PlanFragment 的物理算子, 物理算子如下图所示:

另外,在 Fragment Instance 中,一般用 DataSink 的子类描述该 Fragment Instance 计算结果的去向,比如 DataStreamSink 会把计算结果发给下游 Fragment Instance的ExchangeNode。在 Pipeline 执行引擎中,DataStreamSink 和 ExchangeNode 会分别转化为 ExchangeSinkOperator 和 ExchangeSourceOperator。
Pipeline 算子
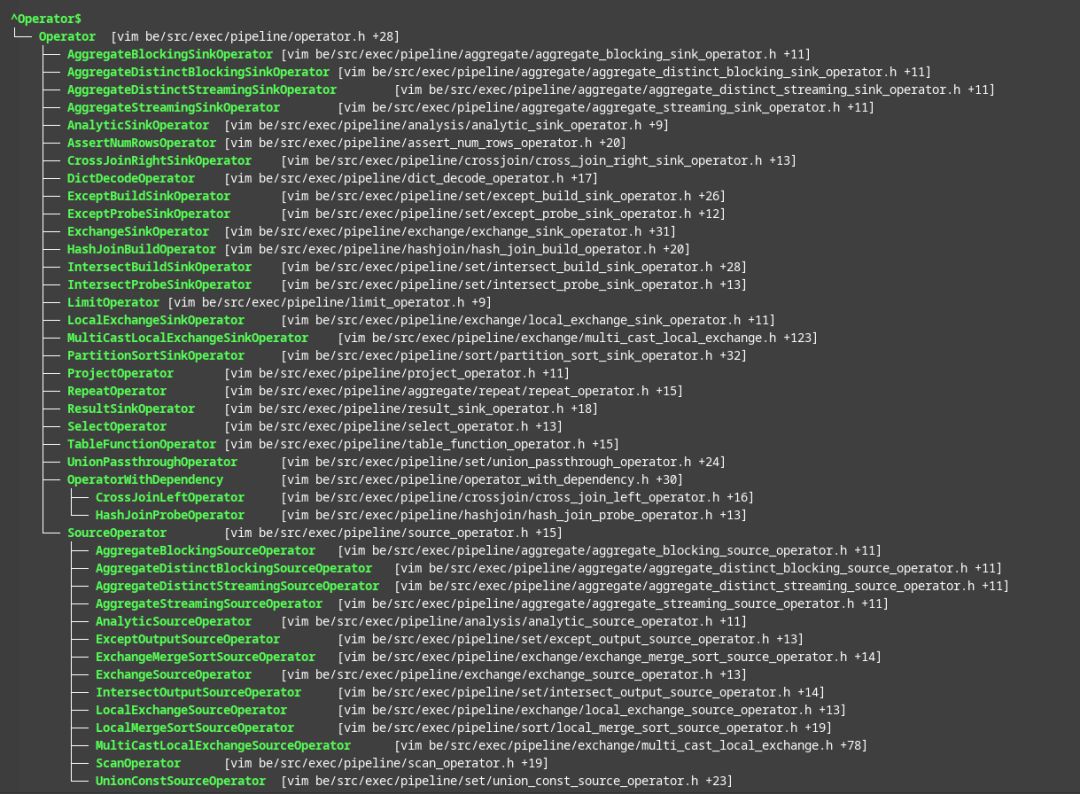
Pipeline 算子的数量比物理算子的数量多,这是因为,Pipeline 算子最多只有一路输入和一路输出,多路输入的物理算子和全量物化的物理算子,会拆解成多个 Pipeline 算子。Pipeline 算子接口定义,请参考 /home/grakra/workspace/sr/be/src/exec/pipeline/operator.h,部分接口定义如下:
- pull_chunk:从算子中拉取 chunk,一般计算时,从一对算子的前置算子拉取 chunk,然后推给后继算子。
- push_chunk:向算子推 chunk。
- has_output:表示状态,当前算子可输出,可以执行 pull_chunk。
- need_input:表示状态,当前算子可输入,可以执行 push_chunk。
- is_finished:当前算子已经结束,不能执行 pull_chunk/push_chunk。
- prepare:prepare 和 open 表达式和调用其他内部数据结构的 prepare 函数。
- close:close 表达式和调用其他内部数据结构的 close 函数。
- set_finishing:关闭输入,执行 set_finishing 之后,算子的 need_input 始终返回 false,不可调用 push_chunk,但算子内部可能有缓存的计算结果,has_output 可能返回 true,可以调用 pull_chunk。
- set_finished:关闭输入和输出,调用后,is_finished、has_output、need_input 都返回 false,pull_chunk 和 push_chunk 不可调用,当 Pipeline 中 HashJoinProbeOperator 和 LimitOperator 算子产生短路并且提前结束时,需要调用前置算子 set_finished 函数。如果两个算子之间通过专门的 Context 交换数据,则 set_finished 函数中,需要正确地重置 Context 状态,一个算子需要感知到另外一个算子的 set_finished 函数调用。比如 LocalExchangeSinkOperator 和 LocalExchangeSourceOperator。
- set_canceled:类似 set_finished,但表示算子异常结束,如果算子需要区分正常或者异常结束,则需要重载 set_canceled 函数,目前只有 ExchangeSinkOperator 用到该函数。
- pending_finish:表示状态,当算子实现了异步化,算子结束时,异步化任务尚未完成,算子需要等待异步化任务结束后,才能销毁所在的 PipelineDriver。提前销毁 PipelineDriver 可能会导致异步化任务延后执行引用算子中的已销毁对象。
一个算子会经过 prepare -> finishing -> finished -> [cancelled] -> closed 的转换,Pipeline 执行引擎根据算子的状态, 执行相应的接口。
Pipeline 执行引擎中,每个算子有一个 OperatorFactory 类,Pipeline 由 OperatorFactory 组成,PipelineDriver 是 Pipeline 的实例,PipelineDriver 由 Operator 构成,OperatorFactory 创建 Operator 对象,从 Pipeline 创建 PipelineDriver 时,遍历 Pipeline 中的 OperatorFactory,调用 OperatorFactory::create 方法。
// 文件:be/src/exec/pipeline/pipeline.h
// 函数: Pipeline::create_operators
Operators create_operators(int32_t degree_of_parallelism, int32_t i) {
Operators operators;
for (const auto& factory : _op_factories) {
operators.emplace_back(factory->create(degree_of_parallelism, i));
}
return operators;
}
OperatorFactory 如下:
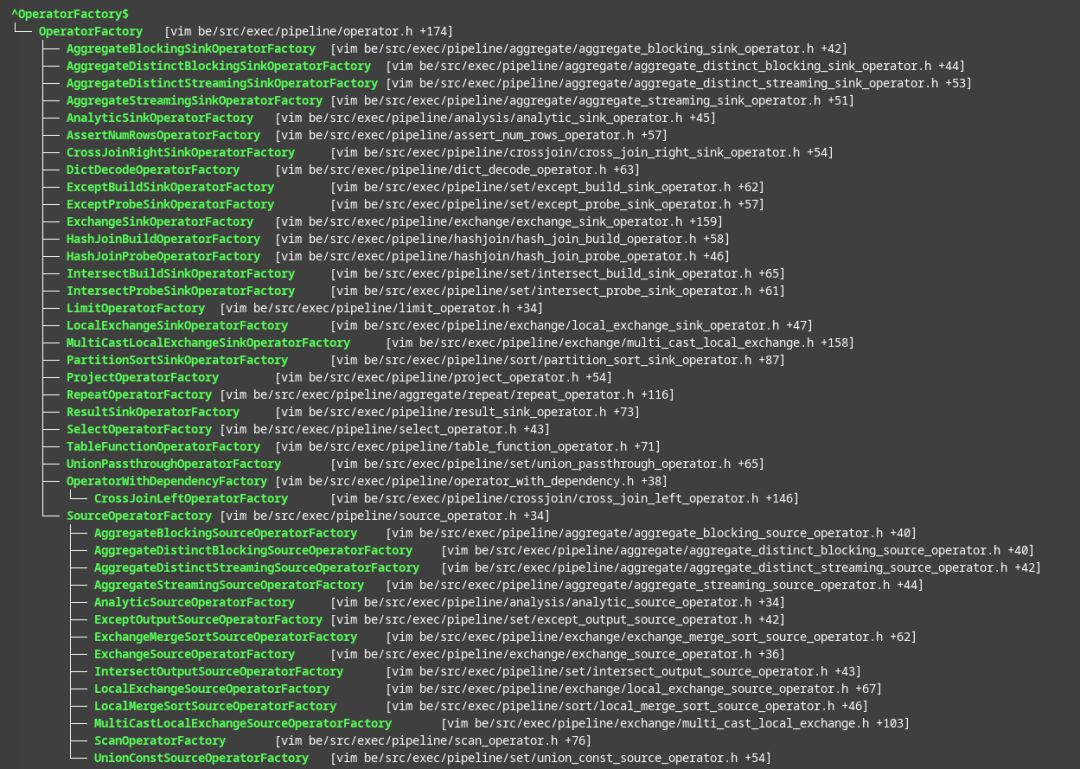
对于某些算子,比如 ScanOperator,来自同一个 OperatorFactory 的多个算子,会共享一份表达式,共享的表达式放置在 OperatorFactory 中,通过 OperatorFactory::prepare函数调用表达式的 prepare/open 函数,通过 OperatorFactory::close 函数调用表达式的 close 函数。
如果表达式不可重入,在计算时,算子在多个线程中执行,存在线程不安全问题。因此新添加的表达式,要保证:
1. 表达式是线程安全的。
2. 线程不安全的表达式,不在 OperatorFactory 中共享,每个算子有自己私有的副本。
Pipeline 拆分
当 BE 收到 FE 发来的 Fragment Instance 时,会创建一个 FragmentExecutor 对象初始化 Fragment Instance 的执行环境。FragmentExecutor::prepare 函数使用 PipelineBuilder 将 PlanFragment 拆分成Pipeline。
// file: be/src/exec/pipeline/fragment_executor.cpp
// function: FragmentExecutor::prepare
ExecNode* plan = nullptr;
RETURN_IF_ERROR(ExecNode::create_tree(runtime_state, obj_pool, fragment.plan, *desc_tbl, &plan))
// ...
PipelineBuilderContext context(_fragment_ctx, degree_of_parallelism);
PipelineBuilder builder(context);
_fragment_ctx->set_pipelines(builder.build(*_fragment_ctx, plan))- 首先通过 ExecNode::create_tree 函数获得 PlanFragment 的物理算子构成执行树。
- 初始化 PipelineBuilderContext 对象,传入 degree_of_parallelism 参数。
- 构建 PipelineBuilder 对象,调用 PipelineBuilder::build 拆分 Pipeline。
PipelineBuilder::build 主要从执行树 root 节点开始,递归调用 decompose_to_pipeline 函数。
Pipelines PipelineBuilder::build(const FragmentContext& fragment, ExecNode* exec_node) {
pipeline::OpFactories operators = exec_node->decompose_to_pipeline(&_context);
_context.add_pipeline(operators);
_context.get_pipelines().back()->set_root();
return _context.get_pipelines();
}
物理算子需要重载 ExecNode 的 decompose_to_pipeline 函数。
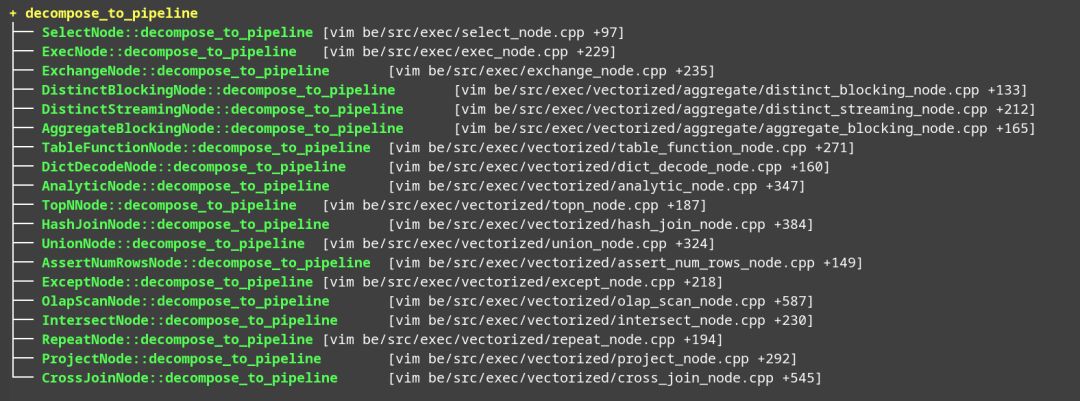
decompose_to_pipeline 函数递归地调用,完成算子的拆分。以 ProjectNode 为例,ProjectNode 调用decompose_to_pipeline 函数对 _children[0] 先完成 Pipeline 拆解,并返回 OperatorFactory 数组,然后 ProjectNode 自身转变为 ProjectOperatorFactory,追加 OperatorFactory 数组的末尾,参考下面代码:
pipeline::OpFactories ProjectNode::decompose_to_pipeline(pipeline::PipelineBuilderContext* context) {
using namespace pipeline;
OpFactories operators = _children[0]->decompose_to_pipeline(context);
// Create a shared RefCountedRuntimeFilterCollector
auto&& rc_rf_probe_collector = std::make_shared<RcRfProbeCollector>(1, std::move(this->runtime_filter_collector()));
operators.emplace_back(std::make_shared<ProjectOperatorFactory>(
context->next_operator_id(), id(), std::move(_slot_ids), std::move(_expr_ctxs),
std::move(_type_is_nullable), std::move(_common_sub_slot_ids), std::move(_common_sub_expr_ctxs)));
// Initialize OperatorFactory's fields involving runtime filters.
this->init_runtime_filter_for_operator(operators.back().get(), context, rc_rf_probe_collector);
if (limit() != -1) {
operators.emplace_back(std::make_shared<LimitOperatorFactory>(context->next_operator_id(), id(), limit()));
}
return operators;
}复杂算子的拆分可能会用到 LocalExchange 算子,目前 LocalExchange 算子支持 Passthrough、broadcast 和 shuffle 模式。更多复杂的算子拆分可以参考针对这些算子的详细源码解析。
DataSink 的拆分和 ExecNode 不同,可以参考函数 FragmentExecutor::_decompose_data_sink_to_operator,此处不再赘述。
4.PipelineDriver 的调度逻辑
PipelineDriver 的调度主要涉及下面几个函数:
- GlobalDriverExecutor::worker_thread:Pipeline 引擎执行线程的入口函数,该函数持续从就绪 Driver 队列获取 PipelineDriver,执行 PipelineDriver::process 函数。在 PipelineDriver 阻塞或者时间片用完时,主动 yield,换其他就绪 PipelineDriver 执行。
- PipelineDriver::process 函数:调用 Operator::pull_chunk/push_chunk 函数进行计算,判断 PipelineDriver 是否阻塞或者需要 yield。
- PipelineDriverPoller::run_internal:阻塞 PipelineDriver 的轮询线程的函数,遍历阻塞 PipelineDriver,将已经解除阻塞的 PipelineDriver 放回就绪队列。
GlobalDriverExecutor::worker_thread
该函数的主要功能是:
- 从就绪队列取 PipelineDriver。
- 执行 PipelineDriver::process 函数
- PipelineDriver 执行完一轮之后,判断 PipelineDriver 的当前状态
- PipelineDriver 正常结束,异常结束或者计算出错,则调用 PipelineDriver::finalize_driver 函数完成 PipelineDriver 的清理;
- PipelineDriver 仍然处于 RUNNING 状态,则设置其状态为 READY,放回就绪 Driver 队列;
- PipelineDriver 处于阻塞状态,则调用 PipelineDriverPoller->add_blocked_driver 函数,将 PipelineDriver 加入到阻塞 Driver 队列中。
- 就绪 Driver 队列采用多级反馈队列(mlfq)实现,小查询优先调度,同时避免大查询饥饿。
- 请参考 https://github.com/StarRocks/starrocks/blob/main/be/src/exec/pipeline/pipeline_driver_executor.cpp
PipelineDriver::process
该函数的功能主要有:
- 遍历 PipelineDriver 中的相邻算子对,只有当两个算子 is_finished() 返回 false,前置算子 has_output() 返回 true,后置算子 need_input() 返回 true 时,调用前置算子的 pull_chunk 获得 chunk,调用后置算子的 push_chunk,将 chunk 推给它,从而完成 chunk 的转移。请参考: https://github.com/StarRocks/starrocks/blob/main/be/src/exec/pipeline/pipeline_driver.cpp
- 当 PipelineDriver 中转移的 chunk 数量超过 100 个,本轮累积执行时间超过 100ms,则主动 yield,退出当前 process,返回就绪队列,换其他 PipelineDriver 执行。
- 当 PipelineDriver 中当前无 chunk 可以移动,则说明 PipelineDriver 处于阻塞状态,退出当前 process,放回阻塞队列。
PipelineDriverPoller::run_internal
该函数遍历阻塞 Driver 队列,唤醒解除阻塞态的 PipelineDriver,放入就绪 Driver 队列,等待 Pipeline 执行线程调度。具体参考见:https://github.com/StarRocks/starrocks/blob/main/be/src/exec/pipeline/pipeline_driver_poller.cpp
#04 总结
本文主要讲解了 Pipeline 执行引擎想解决的问题及一般性原理。针对 Pipeline 执行引擎的实现,着重说明了 BE 端拆分 Pipeline 的逻辑,以及 Pipeline 实例 PipelineDriver 的调度执行逻辑。
想要深入学习 StarRocks 的执行引擎,还需要研究 MPP 调度和向量化执行,后续我们会继续撰文与大家分享。


