
StarRocks 技术内幕 | Join 查询优化
本文发表于: &{ new Date(1667318400000).toLocaleDateString() }
导读:欢迎来到 StarRocks 技术内幕系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你逐步上手这款明星开源数据库产品。
本文整理自作者在 StarRocks 线下 MeetUp 的分享,主要介绍 StarRocks 在 Join 查询规划上的经验和探索。文章主要分为四个部分:Join 背景,Join 逻辑优化,Join Reorder,分布式 Join 规划。
#01 Join 背景
1.Join 类型
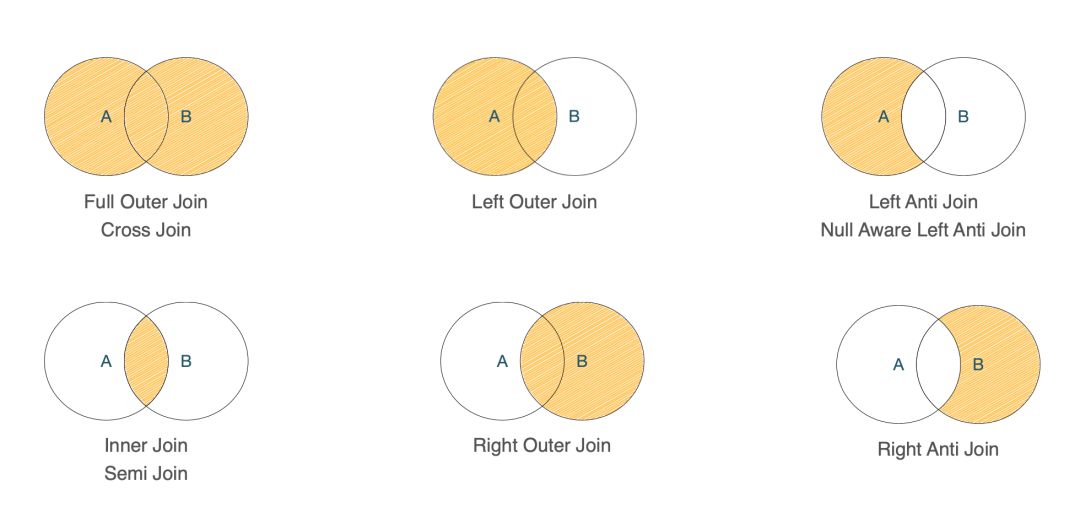
上图列举了常见的 Join 类型:
- Cross Join:左表和右表的一个笛卡尔积。
- Full / Left / Right Outer Join:Outer Join 需要根据语义,对两表/左表/右表上没有匹配上的行进行补 Null。
- Anti Join:输出连接关系上没有匹配上的数据行,通常 Anti Join 出现在not in 或者not exists 子查询的规划中。
- Semi Join:与 Anti Join 相反,只输出在连接关系上匹配的数据行即可。
- Inner Join:输出左表和右表的交集,根据连接条件产生一对多的结果行。
2.Join 优化的难点
Join 的执行效率通常分成两部分来优化,一是提高单机上 Join 算子的效率,二是规划一个合理的 Join 计划,尽可能地减少 Join 的输入/执行成本。本文主要集中在后者的介绍上,那么接下来就从 Join 优化的难点开始讲起。
- 难点一,Join 的实现方式多。
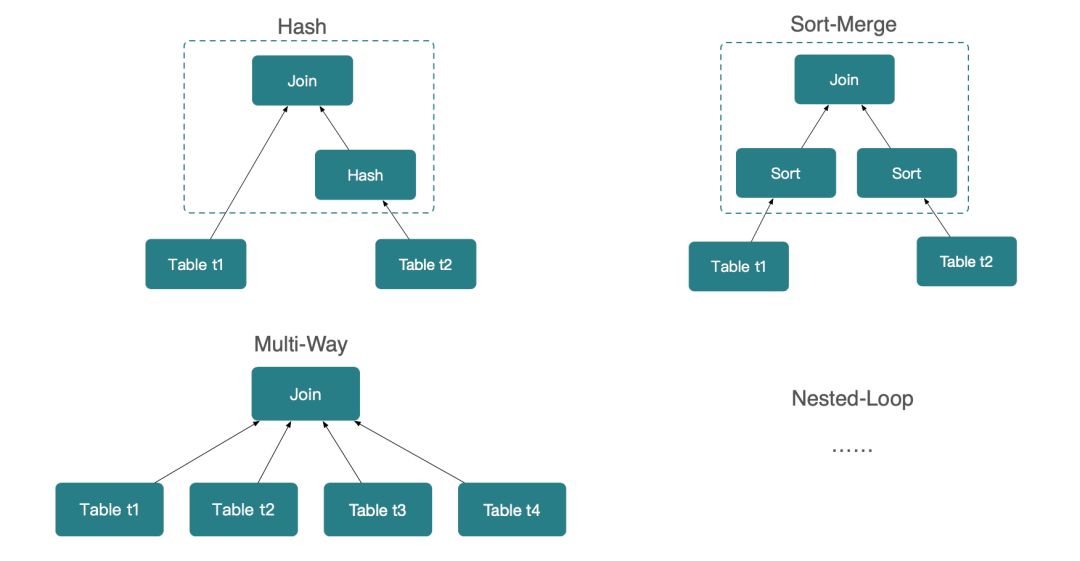
如上图所示,不同 Join 的实现方式在不同场景下效率不同,如 Sort-Merge Join 在 Join 有序数据时,效率可能远高于 Hash Join,但是在数据 Hash 分布的分布式数据库里,Hash Join 的效率可能远比 Sort-Merge 高。而数据库则需要针对不同的场景,选择合适的 Join 方式。
- 难点二,多表 Join 的执行顺序。
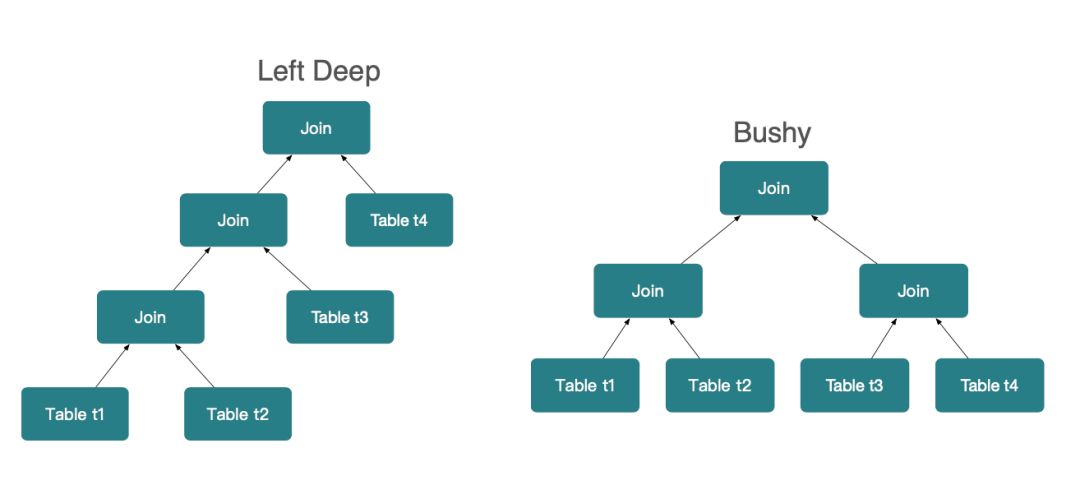
在多表 Join 的场景下,选择度高的 Join 先执行,会提高整个 SQL 的效率,但是怎么判断出 Join 的执行顺序呢?这却是十分困难的。
如上图所示,在 Left-Deep 模型下,N 个表 Join 可能的排列个数有2^n-1个,但是在 Bushy 模型下,排列个数高达2^(n-1) * C(n-1)个,对于数据库而言,查找一个最佳 Join 顺序的耗时和成本是指数级的增长。
- 难点三,Join 的效果难以评估。
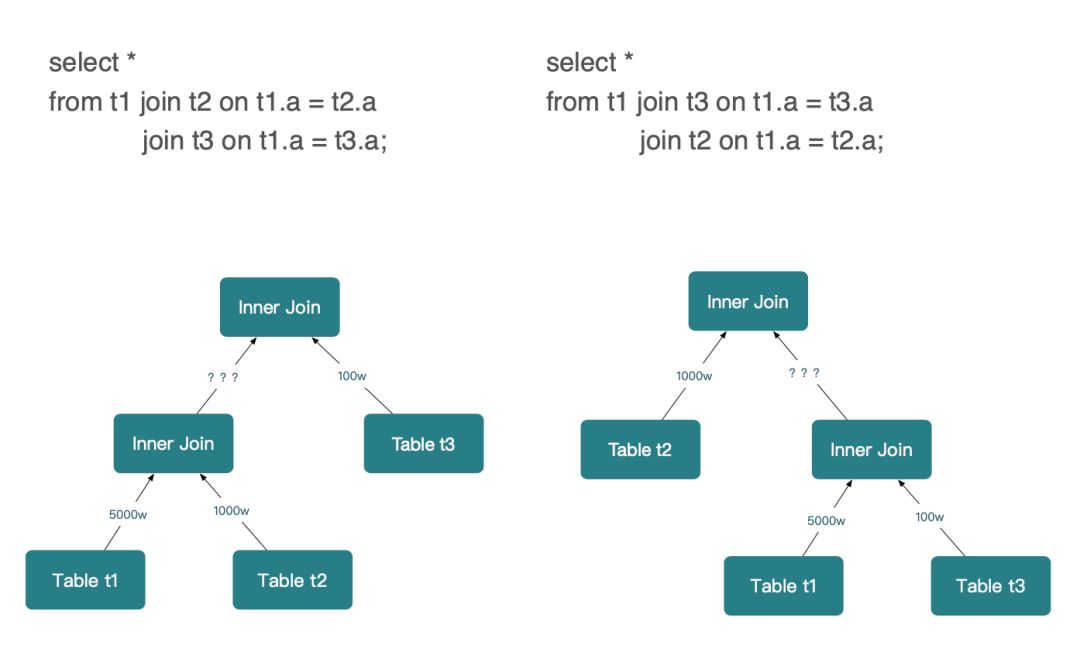
在执行 SQL 之前,数据库难以准确评估一个 Join 实际的执行效果,通常我们都认为小表 Join 大表的选择度高于大表 Join 大表。但是实际情况下呢?显然并不是这样的,还有很多一对多的场景,甚至在更复杂的 SQL 中,存在各种聚合、过滤的算子,在数据经过一系列运算后,数据库系统对于 Join 的输入都会难以评估准确。
- 难点四,单机最优的计划不等于分布式最优。
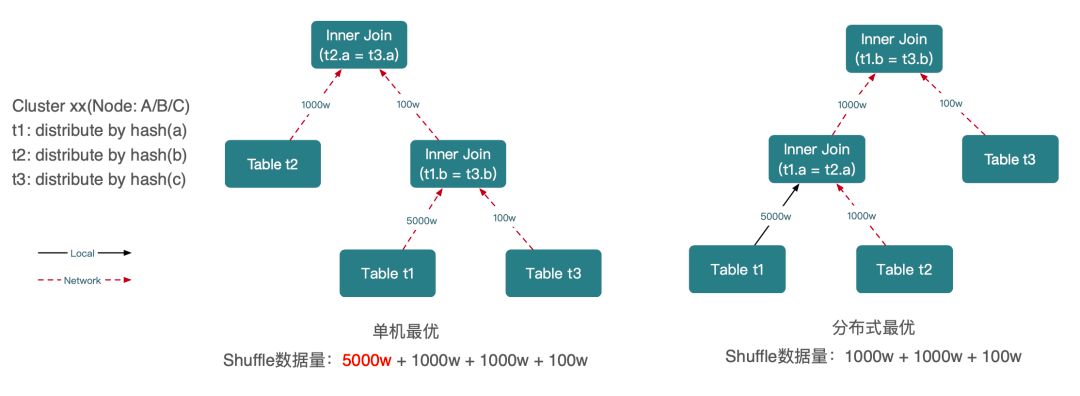
在分布式系统中,会通过 Re-Shuffle 或者广播数据的方式,将需要的数据发送到目的端参与计算,分布式数据库中 Join 也是如此。但这也带来了另外一个问题,一个单机数据库上最优的执行计划,因为没有考虑数据的分布 & 网络传输的开销,放在分布式数据库上未必是最优的执行计划。分布式数据库在规划 Join 的执行计划和执行方式时,需要考虑数据的分布和网络成本。
3.SQL 的优化流程
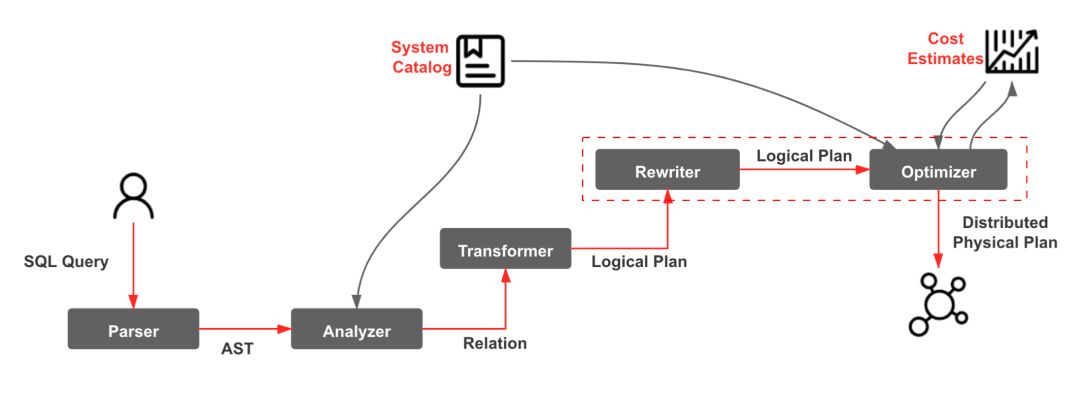
StarRocks 对于 SQL 的优化主要通过优化器完成,主要集中在 Rewrite 和 Optimize 阶段。关于优化器的详细介绍可以参考 StarRocks 优化器代码导读(https://zhuanlan.zhihu.com/p/577956480)。
4.Join 优化的原则
StarRocks 目前 Join 的算法主要是一个 Hash Join,默认使用右表去构建 Hash 表,在这个前提下,我们总结了五个优化方向:
1. 不同 Join 类型的算子,性能是不同的,尽可能使用性能高的 Join 类型,避免使用性能差的 Join 类型。根据 Join 输出的数据量,大致上的性能排序:Semi-Join/Anti-Join > Inner Join > Outer Join > Full Outer Join > Cross Join。
2. Hash Join 实现时,使用小表做 Hash 表,远比用一个大表做 Hash 表高效。
3. 多表 Join 时,优先执行选择度高的 Join,能大幅减少后续 Join 的开销。
4. 尽可能减少参与 Join 的数据量。
5. 尽可能减少分布式 Join 产生的网络成本。
#02 Join 逻辑优化
这部分主要给大家介绍一些 Join 上的启发式规则。
1.类型转换
第一个优化规则紧贴着前面所说的第一个优化原则,也就是把低效率的 Join 类型转为高效的 Join 类型,主要包括以下三个转换规则。
- 转换规则一:Cross Join 转换为 Inner Join
当 Cross Join 满足某个约束时,可以将 Cross Join 转为 Inner Join。该约束为:Join 上至少存在一个表示连接关系的谓词。例如:
-- 转换前
Select * From t1, t2 Where t1.v1 = t2.v1;
-- 转换后, Where t1.v1 = t2.v1是连接关系谓词
Select * From t1 Inner Join t2 On t1.v1 = t2.v1;转换规则二:Outer Join 转换为 Inner Join
当满足以下约束时,可以将 Outer Join 转为 Inner Join:
1. Left / Right Outer Join 上存在一个 Right / Left 表的相关谓词;
2. 该相关谓词是一个严格(Restrick Null)谓词。例如:
- 转换前
Select * From t1 Left Outer Join t2 On t1.v1 = t2.v1 Where t2.v1 > 0;
-- 转换后, t2.v1 > 0 是一个 t2 表上的严格谓词
Select * From t1 Inner Join t2 On t1.v1 = t2.v1 Where t2.v1 > 0;需要注意的是,在 Outer Join 中,需要根据 On 子句的连接谓词进行补 Null 操作,而不是过滤,所以该转换规则不适用 On 子句中的连接谓词。例如:
Select * From t1 Left Outer Join t2 On t1.v1 = t2.v1 And t2.v1 > 1;
-- 显然,上面的SQL和下面SQL的语义并不等价
Select * From t1 Inner Join t2 On t1.v1 = t2.v1 And t2.v1 > 1;这里需要提到一个概念,即严格(Restrick Null)谓词。StarRocks 把一个可以过滤掉 Null 值的谓词叫做严格谓词,例如a > 0;而不能过滤 Null 的谓词,叫做非严格谓词,例如:a IS Null。大部分谓词都是严格谓词,非严格谓词主要是IS Null、IF、CASE WHEN或函数构成的谓词。
StarRocks 对于严格谓词的判断,用了一个简单的方法:将需要检测的列全部替换成 Null,然后进行表达式化简。如果结果是 True,意味着输入为 Null 时,Where 子句无法过滤数据,那么该谓词是一个非严格谓词;反之,如果结果是 False 或 Null,那么是一个严格谓词。

- 转换规则三:Full Outer Join 转为 Left / Right Outer Join
同样,当满足该约束时,Full Outer Join 可以转为 Left / Right Outer Join:存在一个可以 bind 到 Left / Right 表的严格谓词。例如:
-- 转换前
Select * From t1 Full Outer Join t2 On t1.v1 = t2.v1 Where t1.v1 > 0;
-- 转换后, t1.v1 > 0 是一个左表上的谓词,且是一个严格谓词
Select * From t1 Left Outer Join t2 On t1.v1 = t2.v1 Where t1.v1 > 0;2.谓词下推
谓词下推是一个 Join 上非常重要,也是很常用的一个优化规则,其主要目的是提前过滤 Join 的输入,从而提升 Join 的性能。
对于 Where 子句,当满足以下约束时,我们可以进行谓词下推,并且伴随着谓词下推,我们可以做 Join 类型转换:
1. 任意 Join 类型;
2. Where 谓词可以 bind 到其中一个输入上。例如:
Select *
From t1 Left Outer Join t2 On t1.v1 = t2.v1
Left Outer Join t3 On t2.v2 = t3.v2
Where t1.v1 = 1 And t2.v1 = 2 And t3.v2 = 3;其谓词下推的流程如下。
第一步,分别下推 (t1.v1 = 1 And t2.v1 = 2) 和 (t3.v2 = 3),由于满足类型转换规则(t1 Left Outer Join t2) Left Outer Join t3 转换为 (t1 Left Outer Join t2) Inner Join t3。
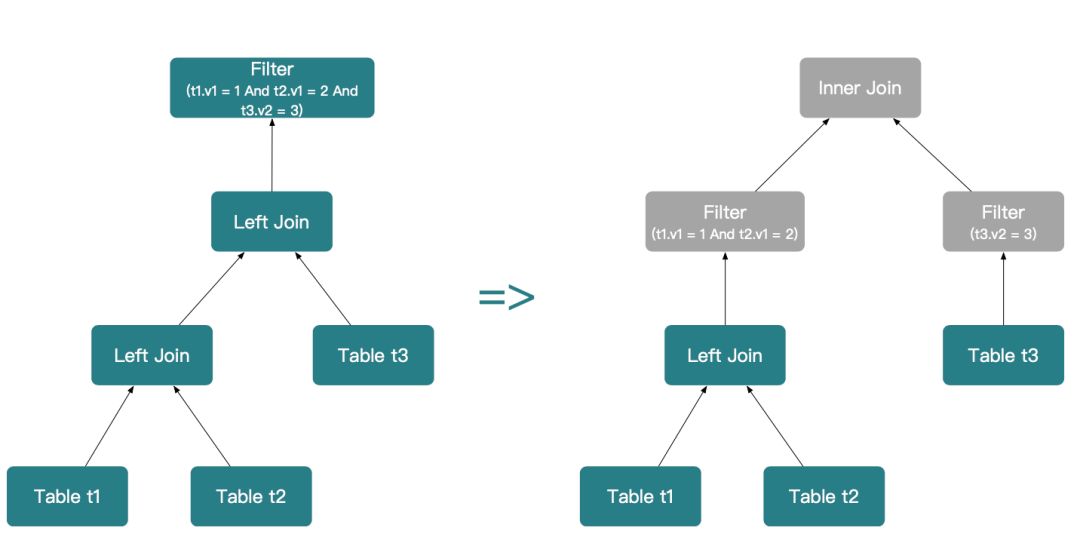
第二步,继续下推 (t1.v1 = 1) 和 (t2.v1 = 2),且 t1 Left Outer Join t2 转换为 t1 Inner Join t2。
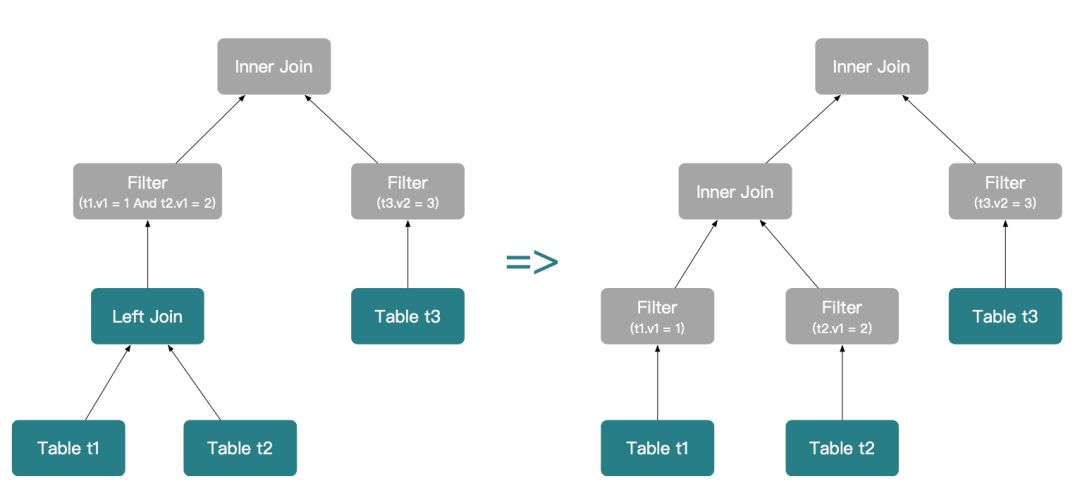
需要注意的是,对于 On 子句上的连接谓词,其下推的规则和 Where 子句有所不同,这里我们分为 Inner Join 和其他 Join 类型两种情况。
第一种情况是,对于 Inner Join,On 子句上的连接谓词下推,和 Where 子句相同,上面已经叙述过,这里不再重复。
第二种情况是,对于 Outer / Semi / Anti Join 的连接谓词下推,需要满足以下约束,且下推过程中无法进行类型转换:
- 必须为 [Left/Right] Outer/Semi/Anti Join;
- 连接谓词只能 bind 到 [Right/Left] 输入上。
例如:
Select *
From t1 Left Outer Join t2 On t1.v1 = t2.v1 And t1.v1 = 1 And t2.v1 = 2
Left Outer Join t3 On t2.v2 = t3.v2 And t3.v2 = 3;其 On 连接谓词下推的流程如下。
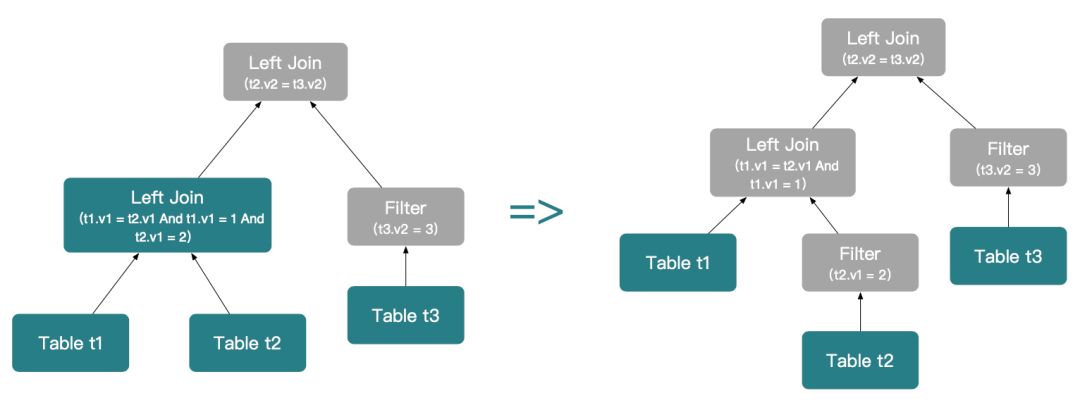
第一步,下推 t1 Left Join t2 Left Join t3 上可以 bind 到右表的连接谓词 (t3.v2 = 3),此时无法将 Left Outer Join 转换为 Inner Join。

第二步,下推 t1 Left Join t2 上可以 bind 到右表的连接谓词 (t2.v1 = 2)。由于t1.v1 = 1是 bind 到左表的,下推以后会过滤 t1 的数据,所以该行为与 Left Outer Join 语义不符,无法下推该谓词。
3.谓词提取
在之前的谓词下推的规则中,只能下推满足合取语义的谓词,例如 t1.v1 = 1 And t2.v1 = 2 And t3.v2 = 3 中,三个子谓词都是通过合取谓词连接,而无法下推析取语义的谓词,例如t1.v1 = 1 Or t2.v1 = 2 Or t3.v2 = 3。
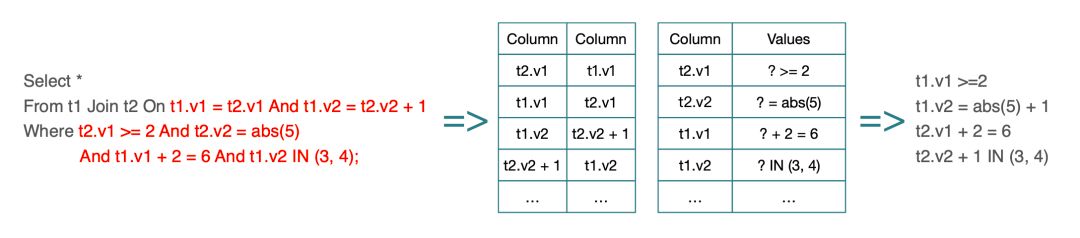
但是在实际场景中,析取谓词也十分常见,对此 StarRocks 做了一个提取谓词(列值推导)的优化。通过一系列的交并集操作,将析取谓词中的列值范围提取出合取谓词,继而下推合取谓词。例如:
-- 谓词提取前
Select *
From t1 Join t2 On t1.v1 = t2.v1
Where (t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)
-- 利用(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)进行列值推导,推导出(t2.v1 >= 2),(t1.v2 IN (3, 4))两个谓词
Select *
From t1 Join t2 On t1.v1 = t2.v1
Where (t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)
AND t2.v1 >= 2 AND t1.v2 IN (3, 4);这里需要注意的是,提取出来的谓词范围可能是原始谓词范围的超集,所以不一定能直接替换原始谓词。
4.等价推导
在谓词上,除了上述的谓词提取,还有另一个重要的优化,叫等价推导。等价推导主要利用了 Join 的连接关系,从左表/右表列的取值范围,推导出右表/左表对应列的取值范围。例如:
-- 原始SQL
Select *
From t1 Join t2 On t1.v1 = t2.v1
Where (t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)
-- 利用(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)进行列值推导,推导出(t2.v1 >= 2),(t1.v2 IN (3, 4))两个谓词
Select *
From t1 Join t2 On t1.v1 = t2.v1
Where (t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)
AND t2.v1 >= 2 AND t1.v2 IN (3, 4);
-- 利用连接谓词(t1.v1 = t2.v1)和(t2.v1 >= 2)进行等价推导,推导出(t1.v1 >= 2)谓词
Select *
From t1 Join t2 On t1.v1 = t2.v1
Where (t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)
AND t2.v1 >= 2 AND t1.v2 IN (3, 4) AND t1.v1 >= 2;当然,等价推导的作用范围并不像谓词提取一样广泛,谓词提取可以在任意谓词上进行,但等价推导和谓词下推类似,在不同的 Join 上有不同的条件约束,这里同样分为 Where 谓词和 On 连接谓词来解析。
Where 谓词:
- 几乎没有约束,可以从左表的谓词推导出右表,反之亦可。
On 连接谓词:
- 在 Inner Join 上和 Where 谓词相同,没有条件约束;
- 除 Inner Join 外,仅支持 Semi Join 和 Outer Join,且仅支持与 Join 方向相反的单向推导。例如,Left Outer Join 可以从左表的谓词推导出右表的谓词,Right Outer Join 可以从右表的谓词推导出左表的谓词。
为什么在 Outer / Semi Join 上存在单向的限制呢?原因也很简单,以 Left Outer Join 为例,在谓词下推的规则中有提到,Left Outer Join 只能下推右表的谓词,而左表的谓词则由于违法语义导致无法下推。所以执行等价推导时,从右表谓词推导出的左表谓词,同样需要满足该约束。
那么在这个前提下,推导出来的左表谓词并不能起到提前过滤数据的作用,而且还会带来执行额外谓词的开销,所以 Outer / Semi Join 只支持单向推导。
关于等价推导的实现,StarRocks 是通过维护了两个 Map 实现的。一个 Map 用于维护 Column 和 Column 之间的等价关系,另一个 Map 则用来维护 Column 到 Value 或者表达式的等值关系,通过这两个 Map 相互查找,实现等价推导。如图:
5.Limit 下推
除了谓词可以下推,Join 上也支持 Limit 的下推。当 SQL 是一个 Outer Join 或 Cross Join 时,可以将 Limit 下推到输出行数稳定的孩子上。其中,Left Outer Join 输出行数至少和左孩子一致,那么 Limit 可以下推到左表上,Right Outer Join 反之。
-- 下推前
Select *
From t1 Left Outer Join t2 On t1.v1 = t2.v1
Limit 100;
-- 下推后
Select *
From (Select * From t1 Limit 100) t Left Outer Join t2 On t.v1 = t2.v1
Limit 100;比较特殊的是 Cross Join 和 Full Outer Join、Cross Join 的输出是一个笛卡尔积,行数是左表 x 右表;而 Full Outer Join 的输出行数,则至少是左表 + 右表,所以这两种 Join 可以在左表和右表上各下推一个 Limit。例如:
-- 下推前
Select *
From t1 Join t2
Limit 100;
-- 下推后
Select *
From (Select * From t1 Limit 100) x1 Join
(Select * From t2 Limit 100)
Limit 100;#03 Join Reorder
Join Reorder 用于推断多表 Join 的执行顺序,数据库需要尽可能地先执行一个高选择度的 Join,这样就能减少后续 Join 的输入数据,从而提升性能。
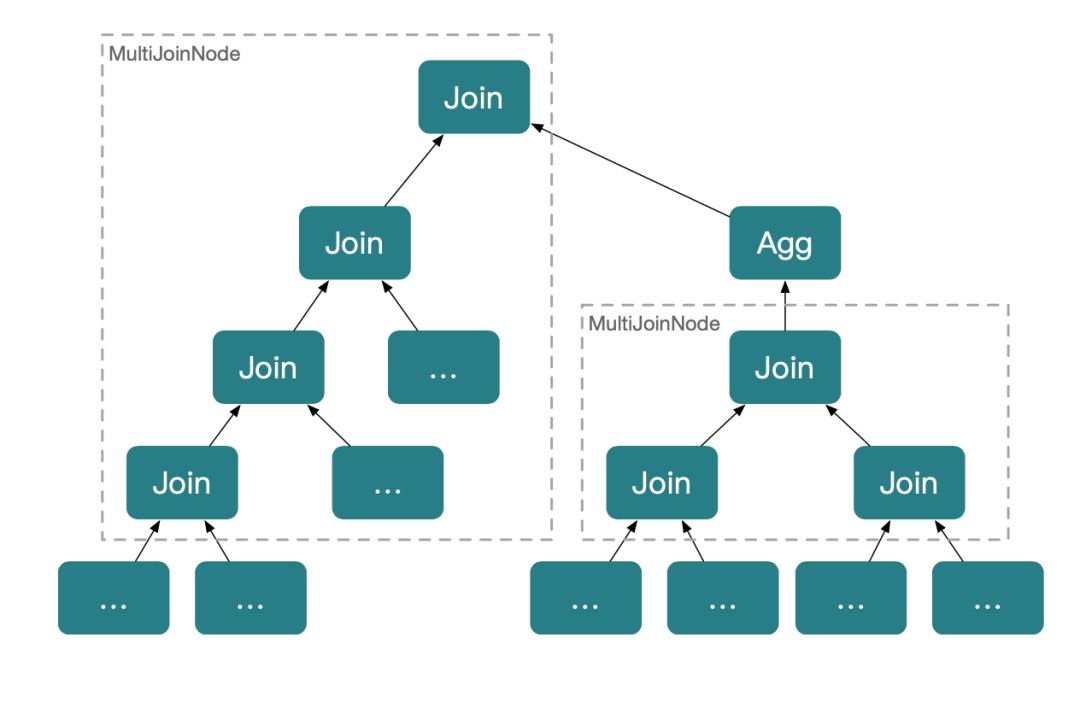
StarRocks 的 Join Reorder,主要是在一个连续的 Inner Join 或者 Cross Join 上工作。以下图为例,StarRocks 会将一组连续的 Inner / Cross Join 叫做一个 Multi Join Node,而 Multi Join Node 就是一个Join Reorder 的单位,即下推存在两个 Multi Join Node,StarRocks 将分别对着两个 Multi Join Node 进行 Join Reorder 推导。
目前业界实现 JoinReorder 的算法有很多种,或者基于不同模型的,例如:
- Heuristic:基于启发式规则的,类似 MemSQL,通过定义维度表中心表排 Join 顺序。
- Left-Deep:左深树模型,搜索空间小,但是不一定最优。
- Bushy:稠密树模型,搜索空间大,包含最优解。其常见的一些 reorder 算法有:
- Exhaustive(Commutativity + Associativity)
- Greedy
- Simulated annealing
- DP(DPsize, DPsub,DPccp...)
- Genetic:GreenPlum
- ......
其中 StarRocks 实现了 Left-Deep、Exhaustive、Greedy、DPsub,接下来会着重介绍一下 StarRocks 中 Exhaustive、Greedy 的实现。
1.Exhaustive
穷举算法通常包括两个规则,通过这两个规则基本上覆盖 Join 的全排列组合。
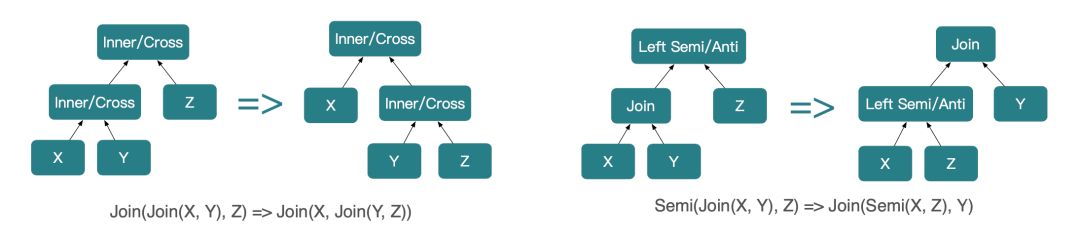
- 规则一:Join 的交换律。
A Join B 转为 B Join A,转换过程中需要注意 Join 类型的变化,比如 Left Outer Join 交换后变为 Right Outer Join。

- 规则二:Join 的结合律。
(A Join B) Join C 转为 A Join(B Join C)。结合律上 StarRocks 又分为两种,一种是 Inner / Cross Join 的结合律,另一种是 Semi Join 的结合律。
2.Greedy
StarRocks 在贪心算法上主要参考多序列贪心算法,其次做了一个小改进,就是对于贪心算法每层产生的结果,StarRocks 都会保留 10 个最优解(可能不是全局最优),以此往后迭代,最终计算出 10 个贪心最优的 Plan。
当然,由于贪心算法的局限性,这样的优化只是提高了计算出全局最优解的概率,并不能保证一定得到全局最优的 Plan。
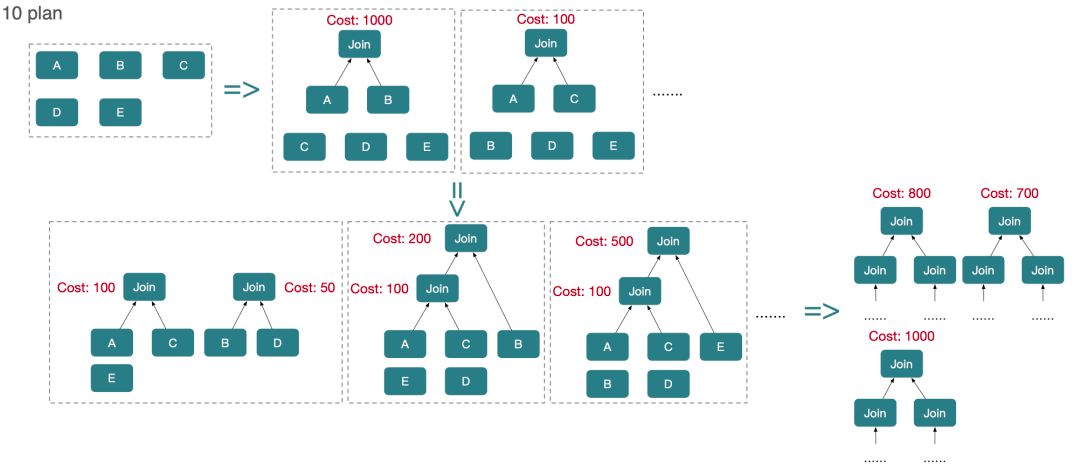
3.Cost Model
StarRocks 使用这些 Join Reorder 的算法推导出 N 个 Plan,最终会根据 Cost Model 的算法,估算出每个 Join 的 Cost,整个 Cost 的计算公式如下:
Join Cost: CPU * (Row(L) + Row(R)) + Memory * Row(R)其中 Row(L)、Row(R) 分别表示 Join 左右孩子的输出行数,公式主要是考虑 CPU 开销,以及 Hash Join 右表做 Hash 表内存的开销,下图详细展示了 StarRocks 中 Join 的输出行数的计算方式。
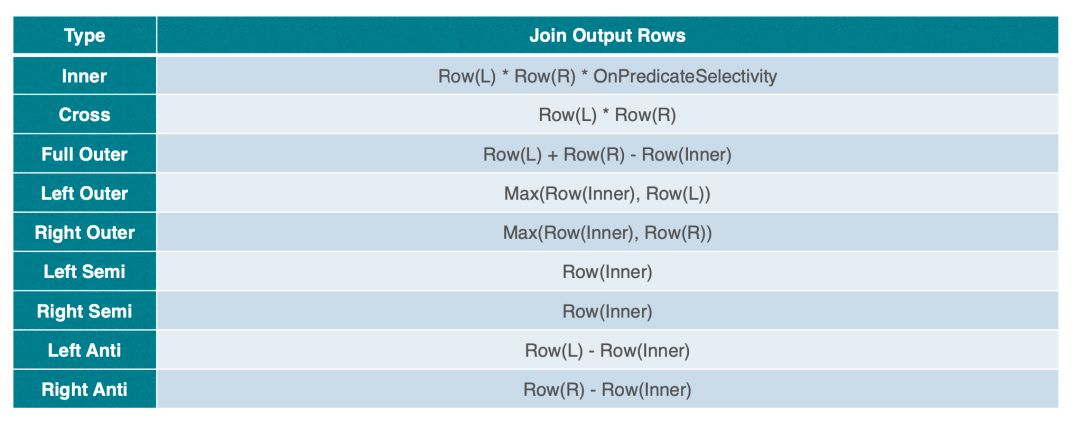
此外,由于不同算法探索 Join Reorder 的空间不同,StarRocks 按照算法的空间复杂度和耗时做了基本的测试,具体如下。
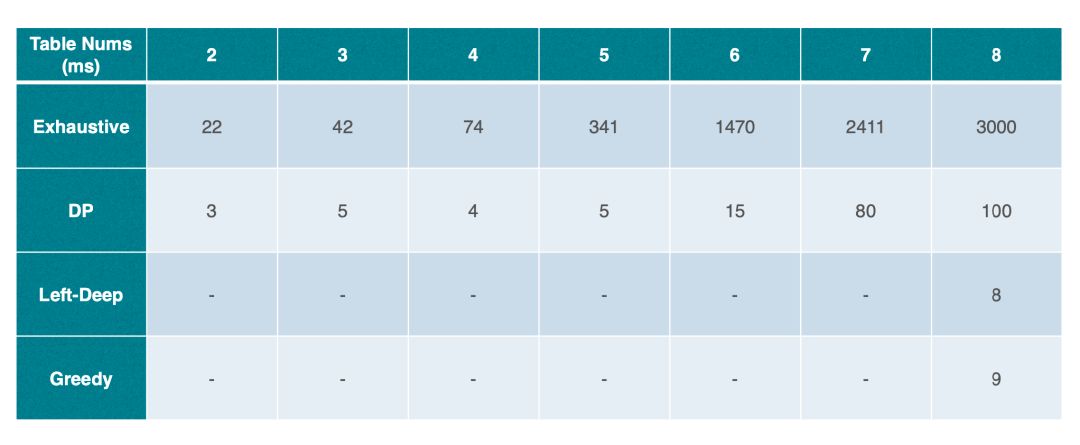
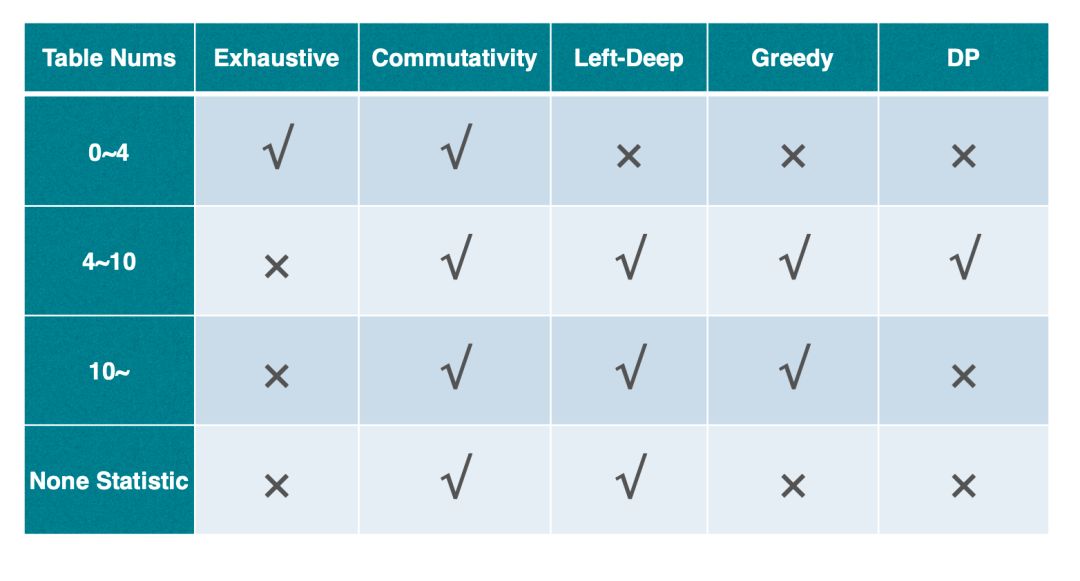
基于上述耗时的结论,StarRocks 对各个算法的执行做了简单的限制。当在 4 表以内的 Join Reorder 使用穷举算法;4~10 表时会分别使用左深、贪心、动态规划算法产生 1 个、10 个、1 个计划,并且在此基础上会使用 Join 交换律探索更多的 Plan;当 10 表以上时,StarRocks 就只使用贪心和左深产生的 11个 Plan 为基础进行 Reorder;另外,在 StarRocks 没有统计信息时,基于 Cost 的贪心和动规都无法很好地工作,所以只会使用左深产生的 1 个 Plan 为基础 Reorder。
#04 分布式 Join 规划
在前面介绍完一个 Join 查询的一些逻辑上的优化点后,后面会结合 StarRocks 作为一个分布式数据库,在分布式 Join 执行上的优化。
1.MPP 并行执行
首先,StarRocks 的执行框架是一个 MPP 的并行执行架构,整体架构如图所示,以一个简单的 Join SQL 为例,StarRocks 执行 A Join B 的流程如下:
1. 按照 A 表和 B 表的分布信息分别从不同的机器上读取数据;
2. 按照 Join 的连接谓词,将 A 表和 B 表的数据 Re-Shuffle 到同一批机器上;
3. 单机 Join 执行,输出结果。
可以看到,实际执行过程中,不只是一台机器参与计算,A 表的机器、B 表的机器、Join 的机器可能都不是同一批机器,中间会涉及到网络传输、数据交换等操作。而在这个过程中,很自然地就带来了网络操作的开销。所以对于 StarRocks,优化分布式 Join 效率中比较重要的一个措施,就是尽可能地减少网络开销,更合理地拆分/分发整个查询计划,尽可能将并行执行的优势发挥出来。
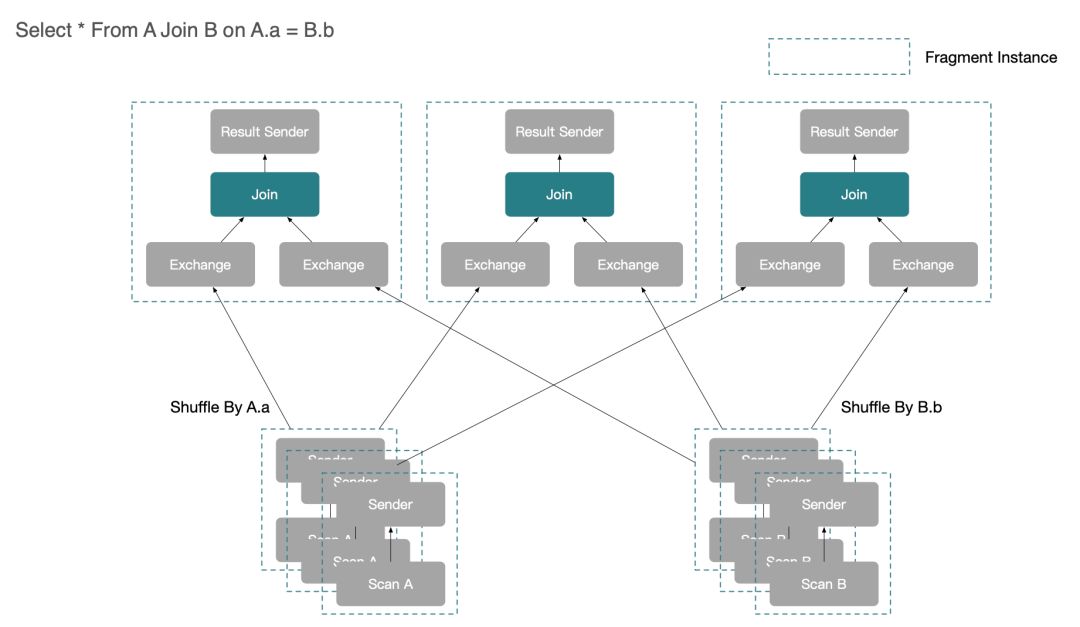
2.分布式 Join 优化
这里先介绍一些 StarRocks 可以生成的分布式执行计划,以一个最简单的 Join 为例:
Select * From A Join B on A.a = B.b 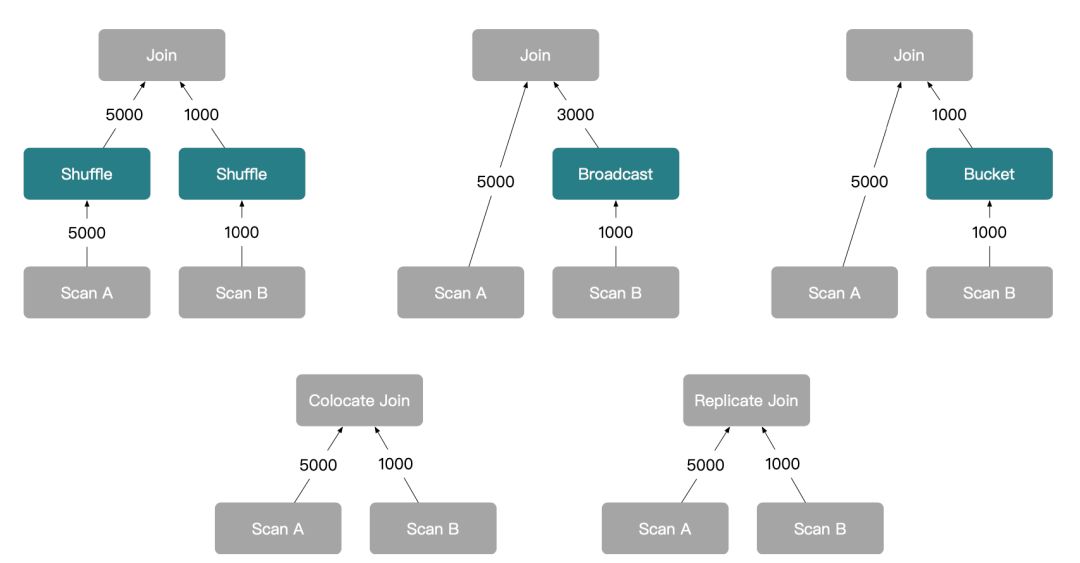
可以看到,StarRocks 实际执行中会产生 5 种最基本的分布式 Plan:
- Shuffle Join:分别将 A、B 两表的数据按照连接关系都 Shuffle 到同一批机器上,再进行 Join 操作。
- Broadcast Join:通过将 B 表的数据全量的广播到 A 表的机器上,在 A 表的机器上进行 Join 操作,相比较于 Shuffle Join,节省了 A 表的数据 Shuffle,但是 B 表的数据是全量广播,适合 B 表是个小表的场景。
- Bucket Shuffle Join:在 Broadcast 的基础上进一步优化,将 B 表按照 A 表的分布方式 Shuffle 到 A 表的机器上进行 Join 操作,B 表 Shuffle 的数据量全局只有一份,比 Broadcast 少传输了很多倍数据量。当然,有约束条件限制,Join 的连接关系必须和 A 表的分布一致。
- Colocate Join:通过建表时指定 A 表和 B 表是同一个 Colocate Group,意味着 A、B 表的分布完全一致,那么当 Join 的连接关系和 A、B 表分布一致时,StarRocks 可以直接在 A、B 表的机器上直接 Join,不需要进行数据 Shuffle。
- Replicate Join:StarRocks 的实验性功能,当每一台 A 表的机器上都存在一份完整的 B 表数据时,直接在本地进行 Join 操作,该 Join 的约束条件比较严格,基本上意味着 B 表的副本数需要和整个集群的机器数保持一致,所以实践意义并不理想。
StarRocks 会对每个 Join 都尝试生成上述 5 种分布式 Join 计划,但是由于不同 Join 类型的语义限制,实际上一些特殊的 Join 类型只能生成特定的分布式 Join 计划。例如,Cross Join 只能生成 Broadcast Join。
3.探索分布式 Join
StarRocks 的分布式 Join 计划,是通过一系列的 Distribution Property 推导产生的。以下述的 Join SQL 的 Shuffle Join Plan 为例,Join 会自顶向下地向 A、B 表分别要求 Shuffle Property。
当 Scan 节点无法满足该要求时,会通过 Enforce 操作,加入一个 Shuffle 的操作节点,用于满足 Join 的要求。最后在生成执行计划时,StarRocks 会将 Shuffle 节点“翻译”成一个 Exchange 节点,通过该节点完成网络数据的传输和交换。
其他的分布式 Join 生成方式和 Shuffle Join 类似,都是由 Join 向下要求不同的属性推导出。
Select * From A Join B on A.a = B.b 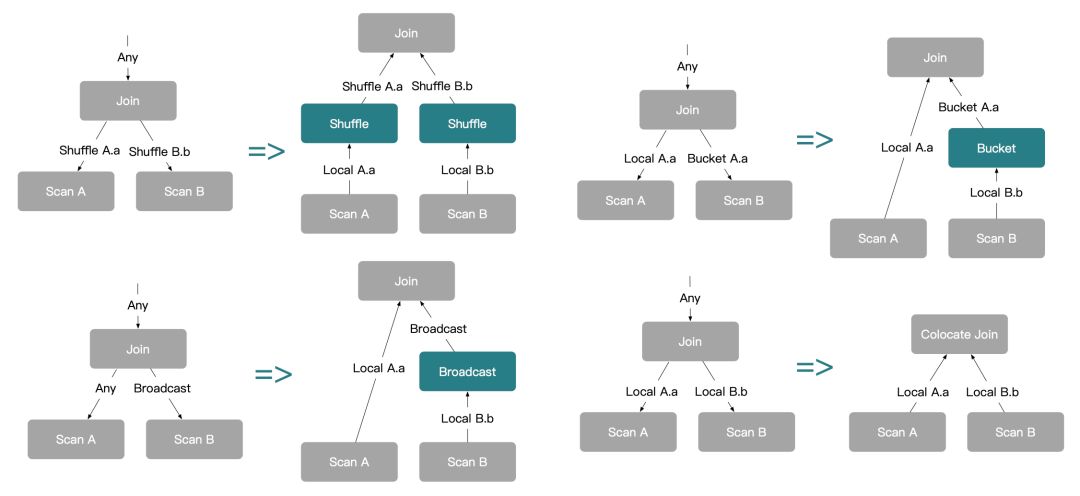
4.复杂的分布式 Join
在用户场景中,用户的 SQL 远比前面的一个 A Join B 复杂得多,可能是 3 表 Join,也可能是 4 表 Join。实际上,StarRocks 对于更复杂的 Join,同样也会生成更复杂多样的分布式 Plan,但都是基于上述最基础的几种 Join 方式推导出来的。例如:
Select * From A Join B on A.a = B.b Join C on A.a = C.c这里简单举几个 StarRocks 基于 Shuffle Join 和 Broadcast Join 生成的分布式 Plan:

当然,如果继续引入 Colocate Join 和 Bucket Shuffle Join,StarRocks 还可以推导出下面这样一些 Plan:
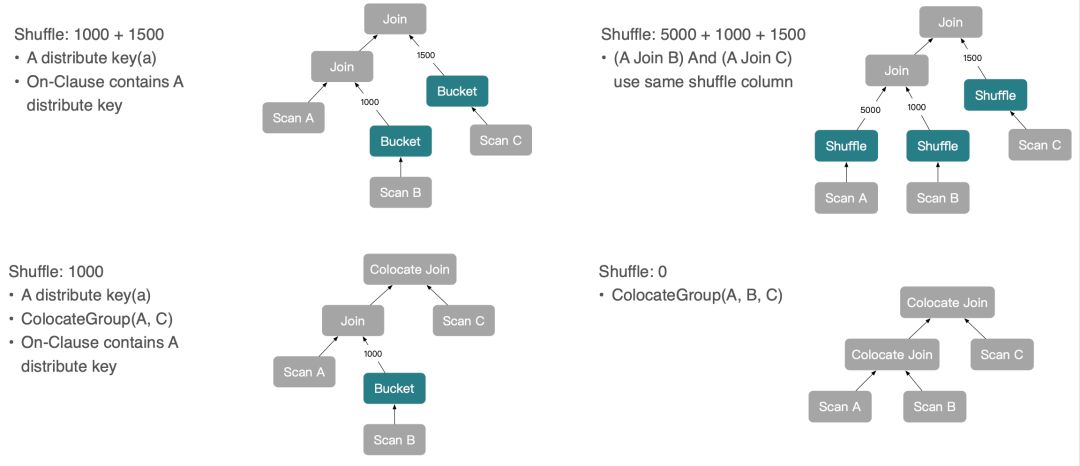
对于上面这些复杂的分布式 Join Plan,其推导原理和前面的原理几乎一致。Distribution Property 在节点间会一直向下传递,进而推导出各种 Join 组合的分布式 Plan。具体的推导实现也可以参考 StarRocks 优化器代码导读(https://zhuanlan.zhihu.com/p/577956480)。
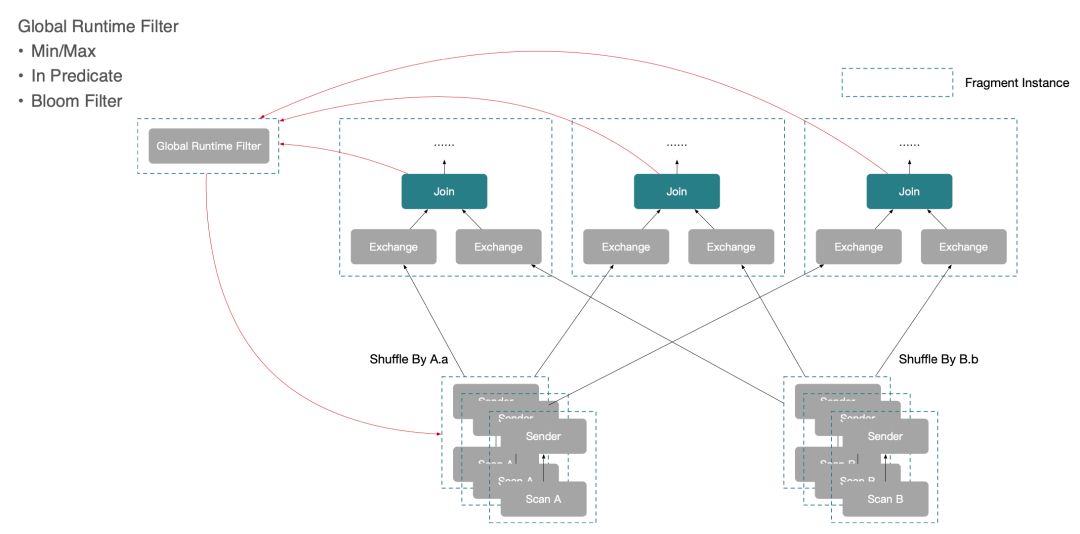
5.Global Runtime Filter
除了分布式 Plan 的这样一些探索外,StarRocks 在规划 Plan 时,还会结合 Join 算子的执行特点,来构造全局性的 Global Runtime Filter 这样一个优化。StarRocks 的 Hash Join 执行过程如下:
1. StarRocks 先查询得到全量的右表数据;
2. 将右表的数据构造为一个 Hash 表;
3. 再去拉取左表的数据;
4. 基于 Hash 表来构建 Join 的连接关系;
5. 输出 Join 结果。
那么,Global Runtime Filter 的工作时机就在 Step 2 和 Step 3 之间,StarRocks 在得到右表的数据后,通过这些运行时数据构造出来一个过滤谓词,在拉取左表数据前先将这样一个 Runime 的过滤谓词下发到左表的 Scan 节点,从而帮助左表的 Scan 节点提前过滤数据,最终达到减少 Join 输入的目的。目前 Global Runtime Filter 支持的过滤方式为:Min / Max、In predicate 和 Bloom Filter。示意图如下:
#05 总结
本文讲述了 StarRocks 对 Join 查询优化的实践和探索,所有的优化都是紧贴提到的优化原则。当然,用户在自行优化 SQL 时,也完全可以参考如下 5 点,以及 StarRocks 提供的功能进行优化。
1. 不同 Join 类型的算子,性能是不同的,尽可能使用性能高的 Join 类型,避免使用性能差的 Join 类型。根据 Join 输出的数据量,大致的性能排序为:Semi-Join/Anti-Join > Inner Join > Outer Join > Full Outer Join > Cross Join。
2. Hash Join 的实现时,使用小表做 Hash 表,远比用一个大表做 Hash 表高效。
3. 多表 Join 时,优先执行选择度高的 Join,能大幅减少后续 Join 的开销。
4. 尽可能减少参与 Join 的数据量。
5. 尽可能减少分布式 Join 产生的网络成本。
StarRocks 在支持了那么多优化后,也有了更多的心得和更多的规划,比如:
- 支持更多的 Join 实现方式,更智能地结合上下文选择更合适的 Join 实现算子;
- 结合 StarRocks 的特性,支持更多特定的 Join Reorder 算法;
- 尽可能地解决 Cost 估算的问题,引入更多的算法或者数据结构来确保估算结果;
- 支持更多调度方式,可能优化网络成本开销。


