
StarRocks 技术内幕:查询原理浅析
本文发表于: &{ new Date(1650729600000).toLocaleDateString() }
一条查询 SQL 在关系型分布式数据库中的处理,通常需要经过 3 大步骤:
1. 将 SQL 文本转换成一个 “最佳的”分布式物理执行计划
2. 将执行计划调度到计算节点
3. 计算节点执行具体的物理执行计划
本文将详细解释在 StarRocks 中如何完成一条查询 SQL 的处理。
首先来了解 StarRocks 中的基本概念:
FE: 负责查询解析,查询优化,查询调度和元数据管理
BE:负责查询执行和数据存储
#01 从 SQL 文本到执行计划
从 SQL 文本到分布式物理执行计划, 在 StarRocks 中,需要经过以下 5 个步骤:
1. SQL Parse:将 SQL 文本转换成一个 AST(抽象语法树)
2. SQL Analyze:基于 AST 进行语法和语义分析
3. SQL Logical Plan:将 AST 转换成逻辑计划
4. SQL Optimize:基于关系代数、统计信息、Cost 模型,对逻辑计划进行重写、转换,选择出 Cost “最低” 的物理执行计划
5. 生成 Plan Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Plan Fragment
SQL Parse
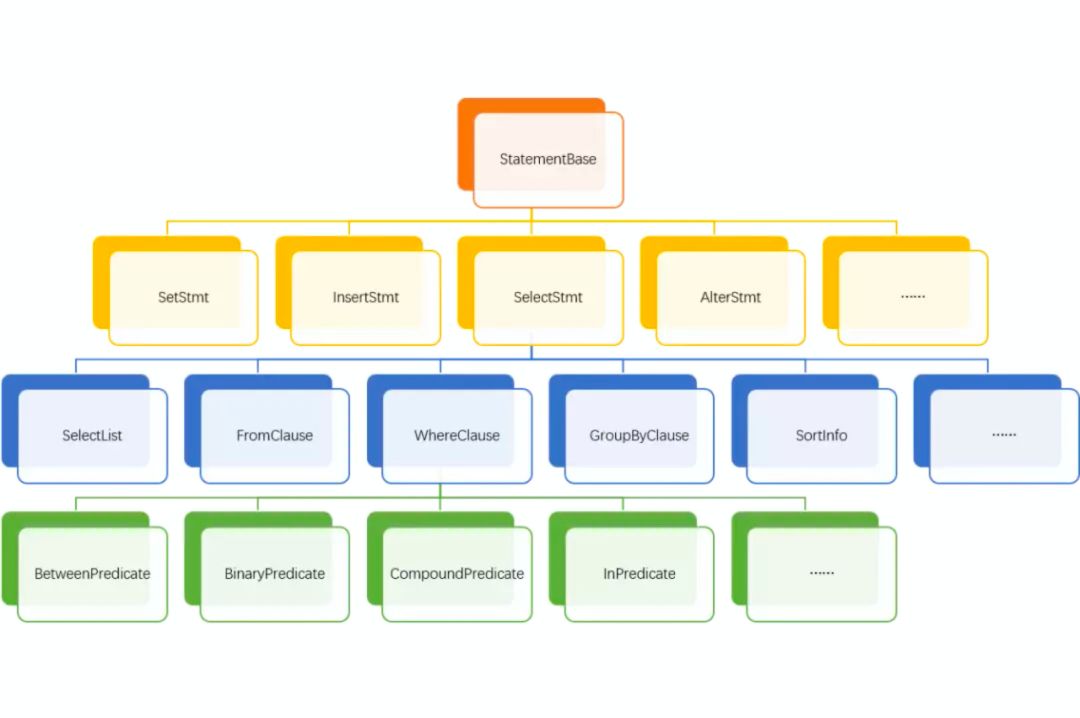
图1
Query Parse 的输入是 SQL 的 String 字符串,Query Parse 的输出是 Abstract Syntax Tree,每个节点都是一个 ParseNode 。
一个查询 SQL Parse 后生成一个 QueryStmt, 由 SelectList, FromClause, wherePredicate, GroupByClause, havingPredicate, OrderByElement, LimitElement 等组成,基本和 SQL 文本一一对应。
StarRocks 目前使用的 Parser 是 ANTLR4,语法规则定义的文件可在 GitHub 搜索 StarRocks g4 获取。
SQL Analyze
StarRocks 获取到 AST 后,接着会进行语法分析和语义分析,完成下面的工作:
1. 检查并绑定 Database, Table, Column 等元信息
2. SQL 的合法性检查:Where 中不能有 Grouping 操作, HLL 和 Bitmap 列不能 Sum 等
3. Table 和 Column 的别名处理
4. 函数参数的合法性检测: Sum的参数类型必须是数值类型,Lead 和 Lag 窗口函数第 2 和第 3 个参数必须常量等
5. 类型检查和类型转换:BIGINT 和 DECIMAL 比较,BIGINT 类型需要 Cast 成 DECIMAL
SQL Analyze 的结果是一个有层级结构的 Relation,如图 2 所示,比如一个 From 子句对应一个 TableRelation, 一个子查询对应一个 SubqueryRelation。
SQL Logical Plan
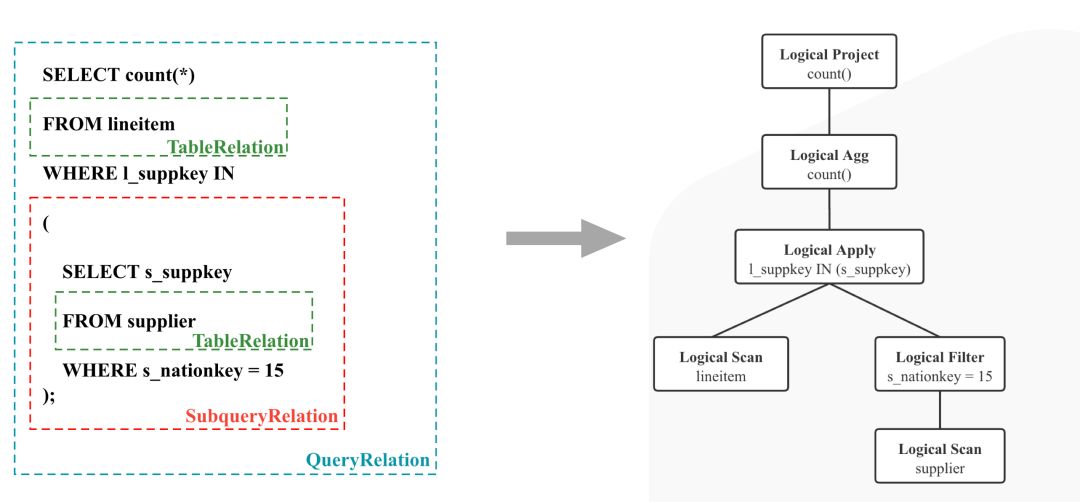
图2
接下来,StarRocks 会将 Relations 转化成一颗 Logical Plan Tree, 如图 2 所示,可以简单理解为每个集合操作都会对应一个 Logical Node。
SQL Optimize
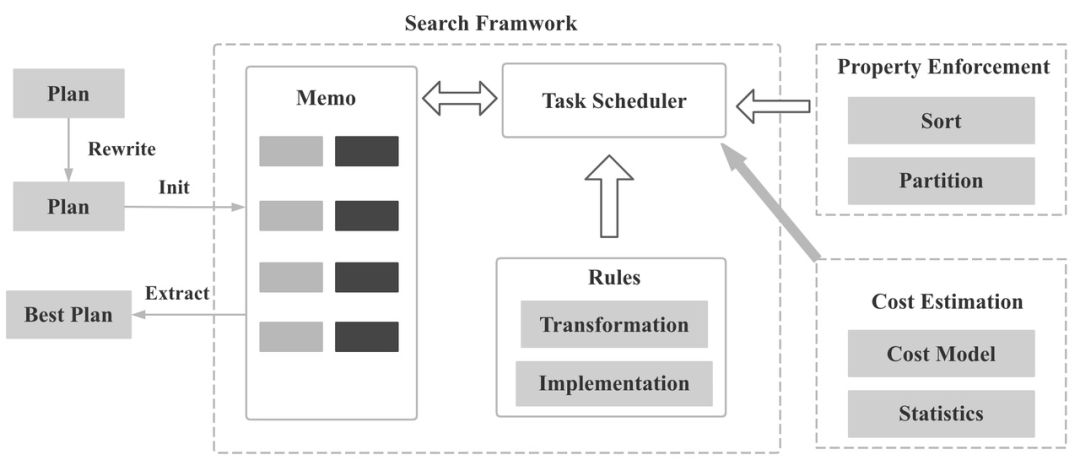
图 3
StarRocks Optimizer 的输入是一棵逻辑计划树,输出是一棵 Cost “最低” 的分布式物理计划树。
一般 SQL 越复杂,Join 的表越多,数据量越大,Optimizer 的意义就越大,因为不同执行方式的性能差别可能有成百上千倍。StarRocks 优化器完全自研,主要基于 Cascades 和 ORCA 论文实现,并结合 StarRocks 执行器和调度器进行了深度定制,优化和创新。
它完整支持了 TPC-DS 99 条 SQL,实现了公共表达式复用,相关子查询重写,Lateral Join, CTE 复用,Join Rorder,Join 分布式执行策略选择,Global Runtime Filter 下推,低基数字典优化等重要功能和优化。
Logical Plan Rewrite
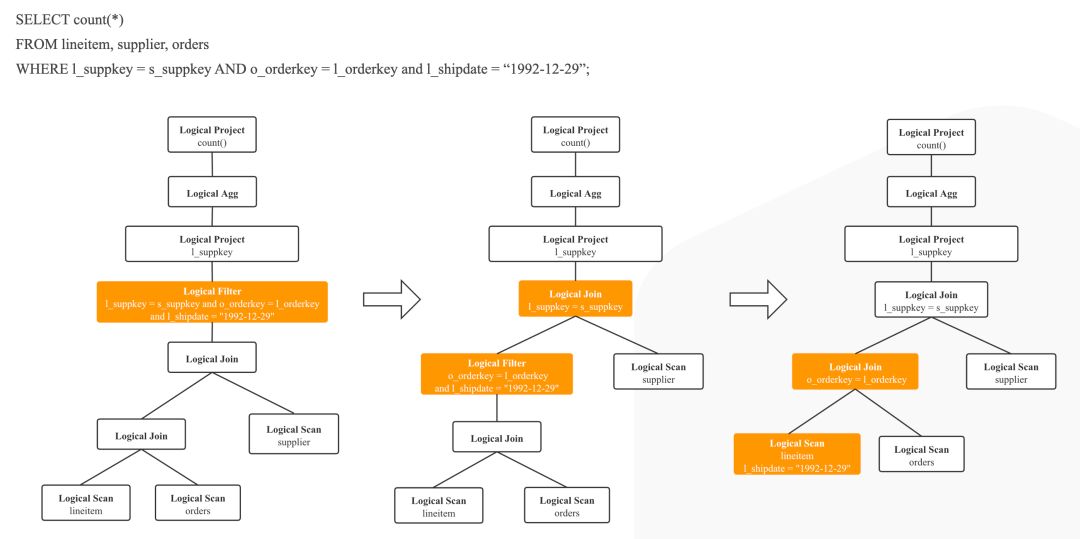
图 4
在正式进入 CBO 之前,StarRocks 会首先进行一系列 Logical Plan 的 Rewrite,Rewrite 阶段的 Rule 我们认为都会生成更优的 Logical Plan,主要的 Rewrite Rule 有下面这些:
- 各种表达式的重写和化简
- 列裁剪
- 谓词下推
- Limit Merge, Limit 下推
- 聚合 Merge
- 等价谓词推导(常量传播)
- Outer Join 转 Inner Join
- 常量折叠
- 公共表达式复用
- 子查询重写
- Lateral Join 化简
- 分区分桶裁剪
- Empty Node 优化
- Empty Union, Intersect, Except 裁剪
- Intersect Reorder
- Count Distinct 相关聚合函数重写
CBO Transform
我们在 Logical Plan Rewrite 完成后,正式基于 Columbia 论文进行 CBO 优化,主要包括下面的优化:
- 多阶段聚合优化:普通聚合(count, sum, max, min 等)会拆分成两阶段,单个 Count Distinct 查询会拆分成三阶段或是四阶段。
- Join 左右表调整:StarRocks 始终用右表构建 Hash 表,所以右表应该是小表,StarRocks 可以基于 cost 自动调整左右表顺序,也会自动把 Left Join 转 Right Join。
- Join 多表 Reorder:多表 Join 如何选择出正确的 Join 顺序,是 CBO 优化器的核心。当 Join 表的数量小于等于 5 时,StarRocks 会基于 Join 交换律和结合律进行 Join Reorder,大于 5 时,StarRocks 会基于贪心算法和动态规划进行 Join Reorder。
- Join 分布式执行选择:StarRocks 支持的分布式 Join 方式有 Broadcast、Shuffle、单边 Shuffle、Colocate、Replicated。StarRocks 会基于 Cost 估算和 Property Enforce 机制选择出 “最佳” 的 Join 分布式执行方式。
- Push Down Aggregate to Join
- 物化视图选择与重写
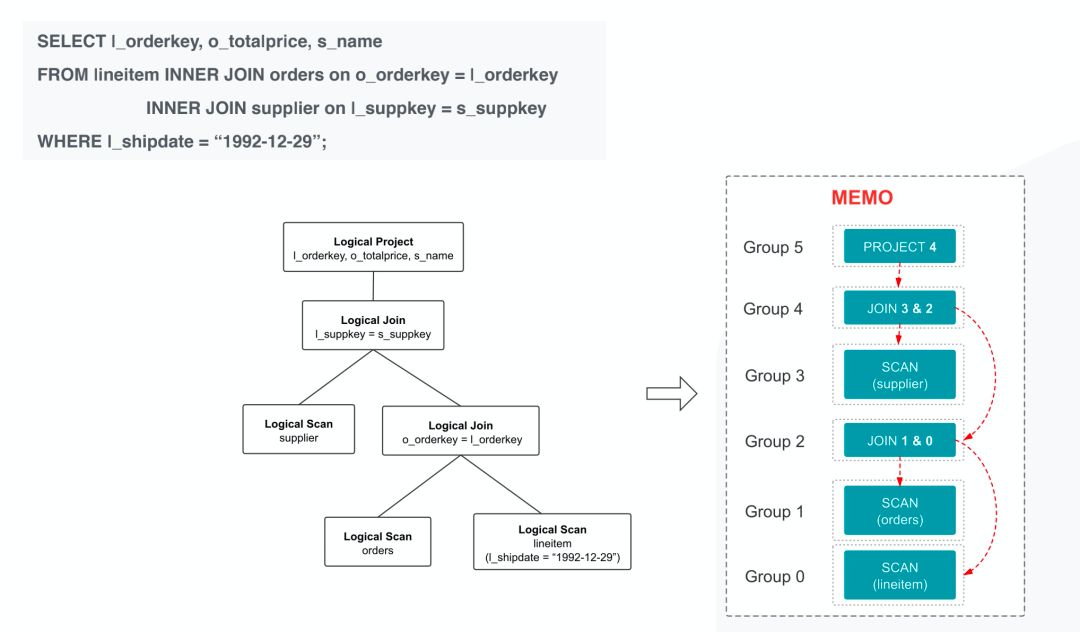
图 5
如图 5 所示, 在 CBO 优化中,Logical Plan 会先转成 Memo 的数据结构。Memo 的中文含义是备忘录,所有的逻辑计划和物理计划都会记录在 Memo 中, Memo 就构成了整个搜索空间 。
然后如图 6 所示,StarRocks 应用各种 Rule 扩展搜索空间,并生成对应的物理执行计划,再基于统计信息和 Cost 估计从 Memo 中选择一组 Cost 最低的物理执行计划。
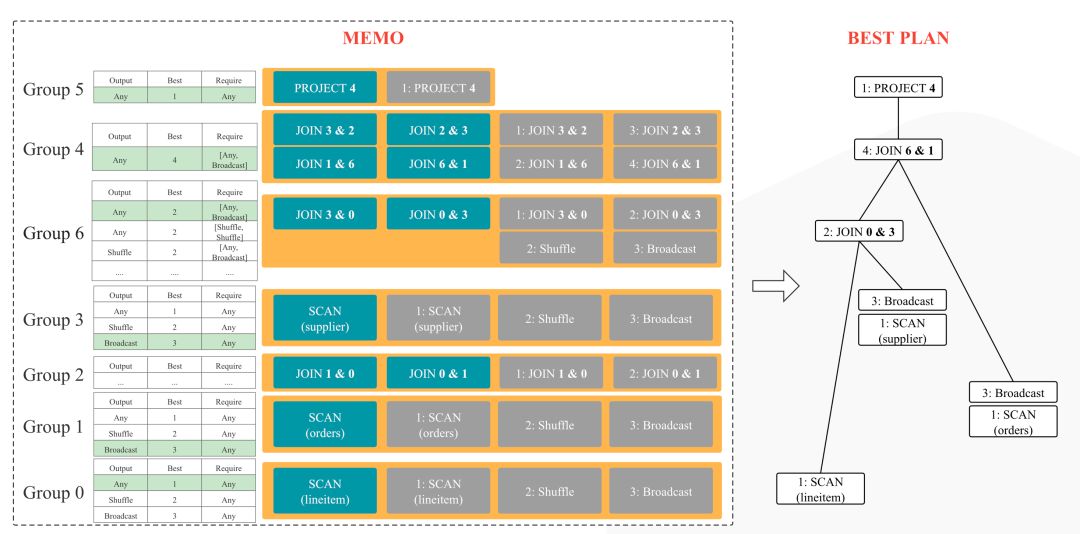
图 6
统计信息 和 Cost 估计
CBO 优化器好坏的关键之一是 Cost 估计是否准确,而 Cost 估计是否准确的关键点之一是统计信息是否收集及时准确。
StarRocks 目前支持表级别和列级别的统计信息,支持自动收集和手动收集两种方式。无论自动还是手动,都支持全量和抽样收集两种方式。
有了统计信息之后, StarRocks 就会基于统计信息进行 Cost 估算。StarRocks 估算 Cost 时会考虑 CPU、内存、网络、IO 等资源因子,每个资源因子会有不同的权重,每个执行算子的 Cost 计算公式都不太一样。
当你使用 StarRocks 发现 Join 左右表不合理、Join 分布式执行策略不合理时,可以参考 StarRocks CBO 使用文档收集统计信息。
生成 Plan fragment
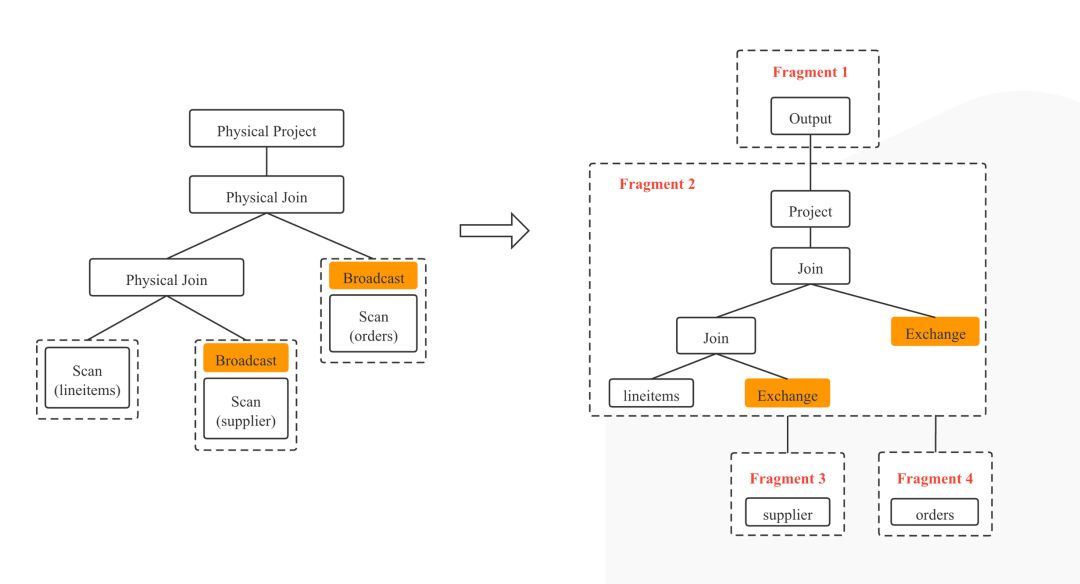
图 7
StarRocks Optimizer 的输出是一棵分布式物理执行计划树,但并不能直接被 BE 节点执行,所以需要转换成 BE 可以直接执行的 PlanFragment。转换过程基本是个一一映射的过程。
#02 执行计划的调度
在生成查询的分布式 Plan 之后,FE 调度模块会负责 PlanFragment 的执行实例生成、PlanFragment 的调度、每个 BE 执行状态的管理、查询结果的接收。

图8
有了分布式执行计划之后,我们需要解决下面的问题:
1. 哪个 BE 执行哪个 PlanFragment
2. 每个 Tablet 选择哪个副本去查询
3. 多个 PlanFragment 如何调度
StarRocks 会首先确认 Scan Operator 所在的 Fragment 在哪些 BE 节点执行,每个 Scan Operator 有需要访问的 Tablet 列表。然后对于每个 Tablet,StarRocks 会先选择版本匹配的、健康的、所在的 BE 状态正常的副本进行查询。在最终决定每个 Tablet 选择哪个副本查询时,采用的是随机方式,不过 StarRocks 会尽可能保证每个 BE 的请求均衡。假如我们有 10 个 BE、10 个 Tablet,最终调度的结果理论上就是每个 BE 负责 1 个 Tablet 的 Scan。
当确定包含 Scan 的 PlanFragment 由哪些 BE 节点执行后,其他的 PlanFragment 实例也会在 Scan 的 BE 节点上执行 (也可以通过参数选择其他 BE 节点 ),不过具体选择哪个 BE 是随机选取的。
当 FE 确定每个 PlanFragment 由哪个 BE 执行,每个 Tablet 查询哪个副本后,FE 就会将 PlanFragment 执行相关的参数通过 Thrift 的方式发送给 BE。
目前 FE 对多个 PlanFragment 调度的方式是 All At Once 的方式,是按照自顶向下的方式遍历 PlanFragment 树,将每个 PlanFragment 的执行信息发送给对应的 BE。
#03 执行计划的执行
StarRocks 是通过 MPP 多机并行机制来充分利用多机的资源,通过 Pipeline 并行机制来充分利用单机上多核的资源,通过向量化执行来充分利用单核的资源,进而达到极致的查询性能。
MPP 多机并行执行
MPP 是大规模并行计算的简称,核心做法是将查询 Plan 拆分成很多可在单个节点上执行的计算实例,然后多个节点并行执行。每个节点不共享 CPU、内存、磁盘资源。MPP 数据库的查询性能可以随着集群的水平扩展而不断提升。
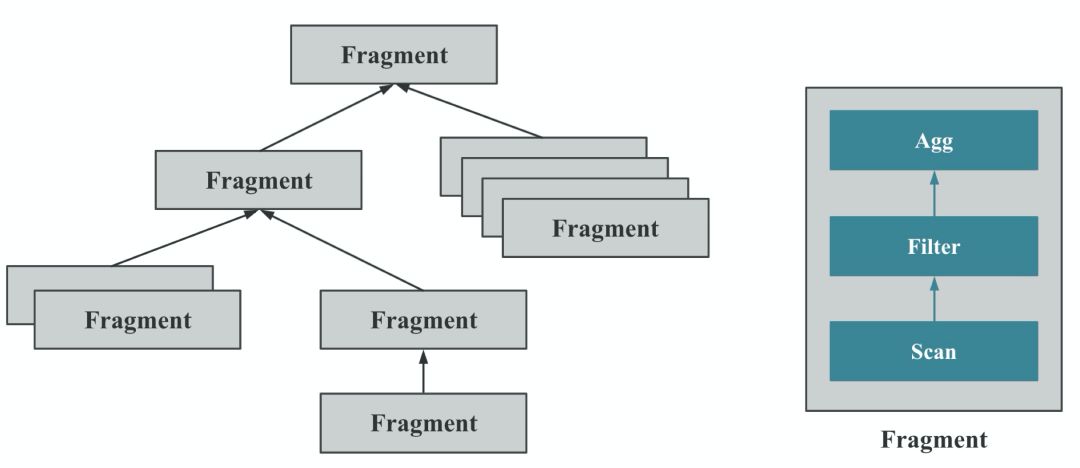
图9
如图 9 所示,StarRocks 会将一个查询在逻辑上切分为多个 Query Fragment(查询片段),每个 Query Fragment 可以有一个或者多个 Fragment 执行实例,每个 Fragment 执行实例会被调度到集群某个 BE 上执行。一个 Fragment 可以包括一个或者多个 Operator(执行算子),图中的 Fragment 包括了Scan、Filter、Aggregate。每个 Fragment 可以有不同的并行度。
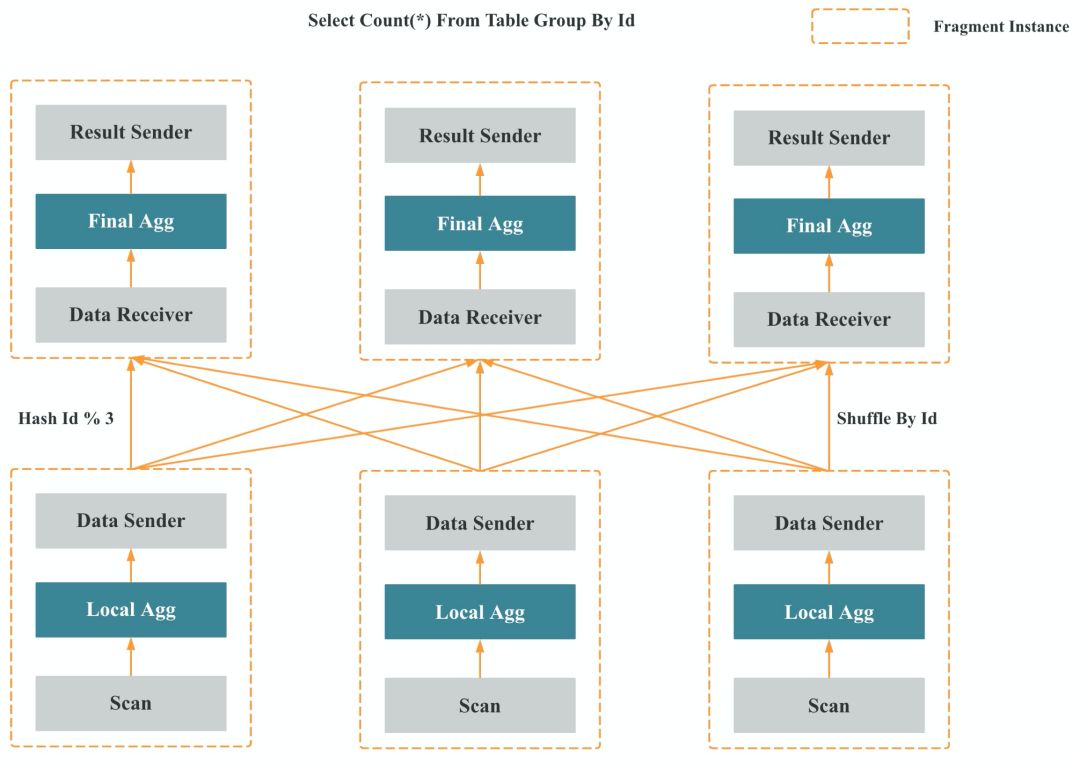
图 10
如图 10 所示,多个 Fragment 之间会以 Pipeline 的方式在内存中并行执行,而不是像批处理引擎那样 Stage By Stage 执行。Shuffle (数据重分布)操作是 MPP 数据库查询性能可以随着集群的水平扩展而不断提升的关键,也是实现高基数聚合和大表 Join 的关键。
Pipeline 单机并行执行
StarRocks 在 Fragment 和 Operator 之间引入了 Pipeline 的概念,一个 Pipeline 内的数据没有到达终点前不需要 Materialize,遇到需要 Materialize 的算子(Agg, Sort, Join),则需要拆分出一个新的 Pipeline,所以 1 个 Fragment 会对应多个 Pipeline。
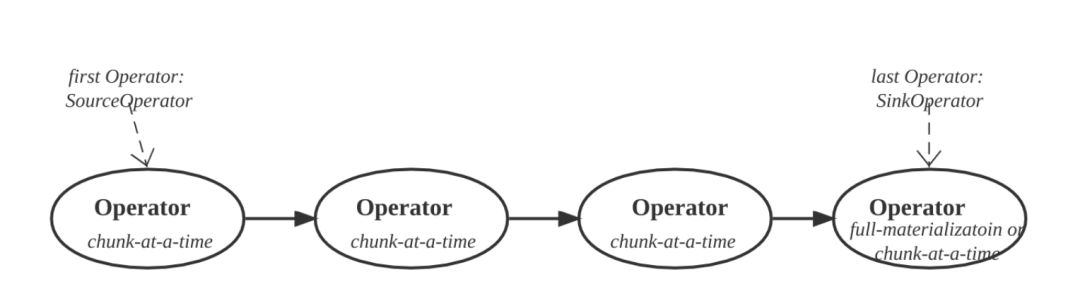
图 11
如图 11 所示,一个 Pipeline 由多个 Operator 组成。第一个 Operator 是 Source Operator,负责产生数据,一般是 Scan 节点 和 Exchange 节点。最后一个 Operator 是 Sink Operator,负责物化或者消费数据。中间的 Operator 负责对数据进行 Transform。
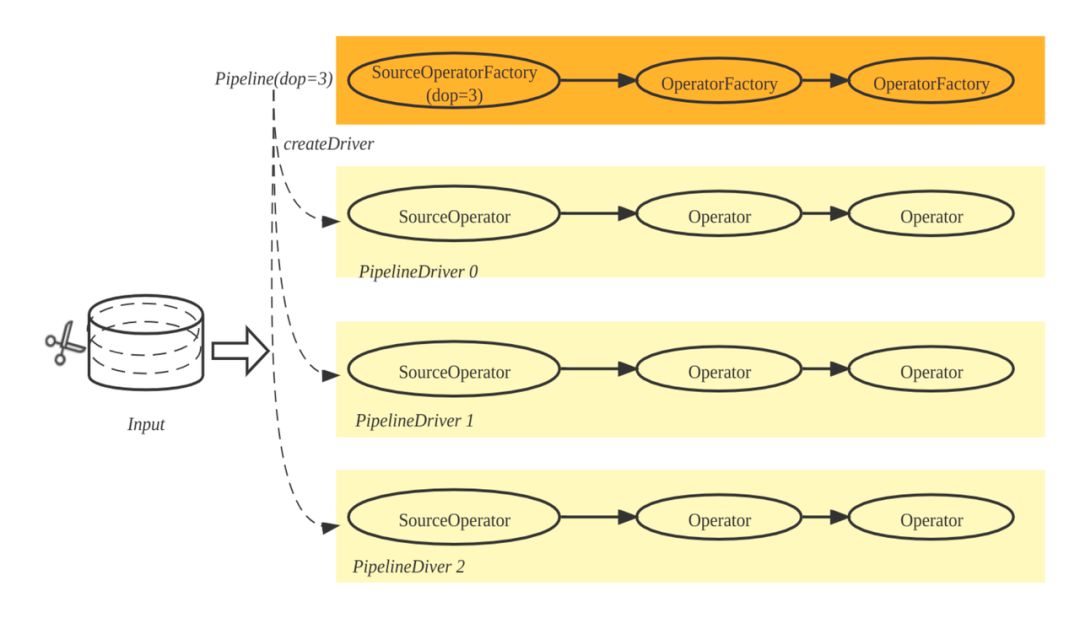
图 12
那么 Pipeline 如何并行呢?答案是 Pipeline 和 Fragment 一样,可以生成多个实例,每个实例称为一个 Pipeline Driver。当一个 Pipeline 需要 N 个并行度去执行时,一个 Pipeline 就会生成 N 个 Pipeline Driver,如图 12 所示,并行度是 3,一个 Pipeline 就产生了 3个 Pipeline Driver。
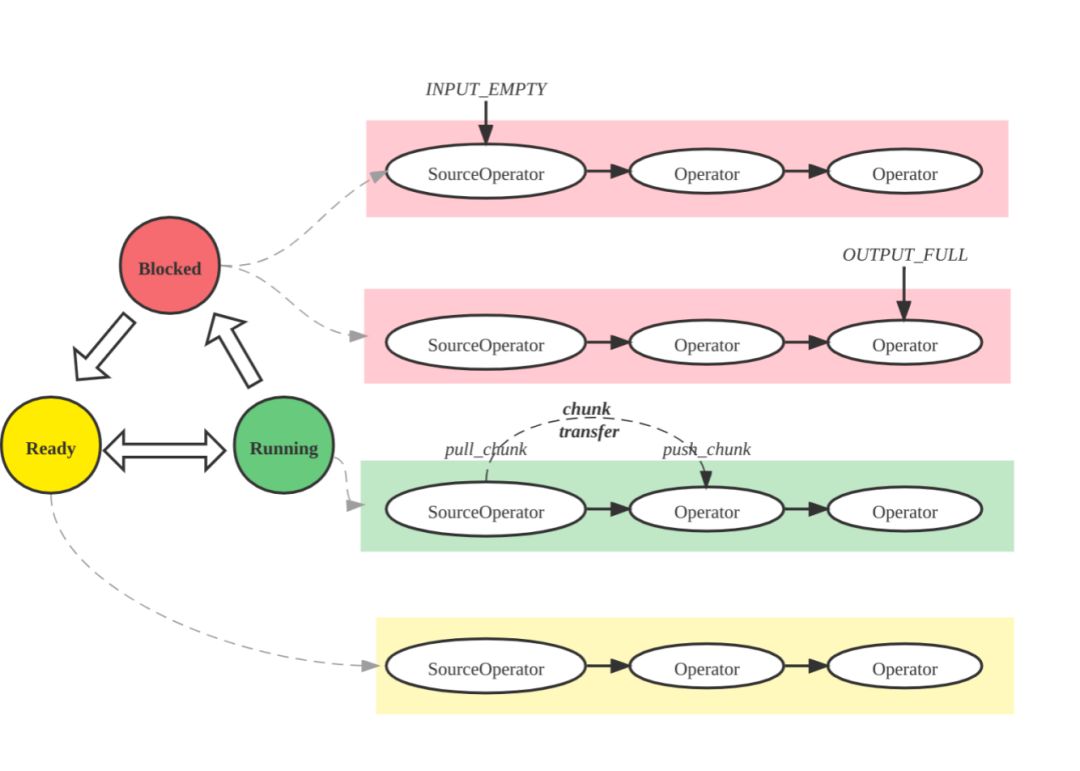
图 13
如图13 所示,一个 Pipeline 执行中,当前一个 Operator 可以产生数据,且后一个 Operator 可以消费数据时,Pipeline 的执行线程就会从前一个 Operator Pull 出数据,然后 Push 到后一个 Operator。每个 Pipeline 的执行状态是很清晰的,简单可以理解为有 Ready、Running、Blocked 等 3 种状态。当前面的 Operator 无法产生数据,或者后面的 Operator 不需要消费数据时,Pipeline 就会处于 Blocked 的状态。
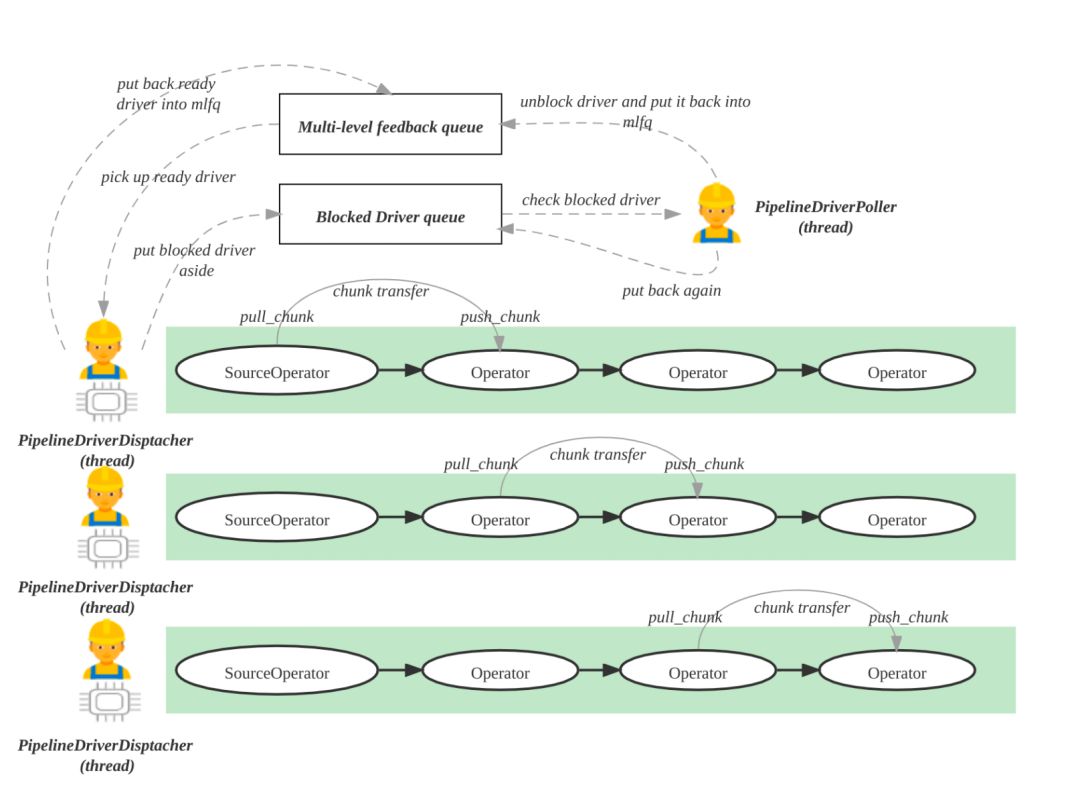
图 14
如图 14 所示, Pipeline 并行执行框架的核心是实现一个用户态的协程调度,不再依赖操作系统的内核态线程调度,减少线程创建、线程销毁、线程上下文切换的成本。
在 Pipeline 并行执行框架中,StarRocks 会启动机器 CPU 核数个执行线程,每个执行线程会从一个多级反馈就绪队列中获取 Ready 状态的 Pipeline 去执行,同时会有一个全局 Poller 线程不断检查 Blocked 队列中的 Pipeline 是否解除了阻塞,可以变为 Ready 状态。如果可以变为了 Ready 状态,就可以把 Pipeline 从 阻塞队列移到多级反馈就绪队列中。
向量化执行
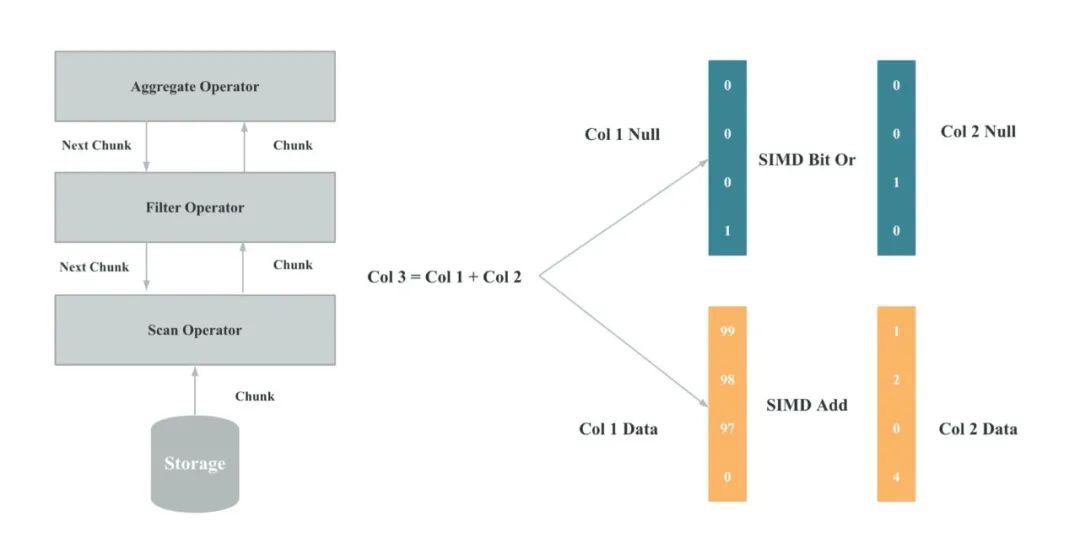
图 15、16
随着数据库执行的瓶颈逐渐从 IO 转移到 CPU,为了充分发挥 CPU 的执行性能,StarRocks 基于向量化技术重新实现了整个执行引擎,向量化执行引擎是为了充分利用单核 CPU 的能力。
向量化在实现上主要是算子和表达式的向量化,图 15 是算子向量化的示例,图 16 是表达式向量化的示例,算子和表达式向量化执行的核心是批量按列执行。相比于单行执行,批量执行可以有更少的虚函数调用,更少的分支判断;相比于按行执行,按列执行对 CPU Cache 更友好,更易于 SIMD 优化。
向量化执行不仅仅是数据库所有算子的向量化和表达式的向量化,而是一项巨大和复杂的性能优化工程,包括数据在磁盘、内存、网络中的按列组织,数据结构和算法的重新设计,内存管理的重新设计,SIMD 指令优化,CPU Cache 优化,C++ Level 优化等。经过努力,StarRocks 向量化执行引擎相比之前的按行执行,取得了整体 5 到 10 倍的性能提升。
每个算子和表达式具体如何实现、如何进行向量化,之后的文章会详细解释,本文不再赘述。
#04 总结
本文主要介绍了 StarRocks 如何完成一条查询 SQL 的处理:
1. 通过高效强大的 CBO 优化器生成最佳的分布式物理执行计划;
2. 通过查询调度器选择合适的数据副本,并将分布式物理执行计划调度到合适的计算节点进行计算;
3. 通过 MPP 分布式执行框架充分利用多机的资源,做到查询性能可以随着机器数量近似线性扩展;
4. 通过 Pipeline 并行执行框架充分利用多核资源,做到查询性能可以随着机器核数近似线性扩展;
5. 通过向量化执行引擎充分利用 CPU 单核资源,将单核执行性能做到极致。


