
StarRocks 3.2 新鲜出炉,性能与易用性再上新台阶
本文发表于: &{ new Date(1703174400000).toLocaleDateString() }
2023年12月21日,StarRocks 3.2 版本正式发布,新版本不仅夯实了一系列重磅功能特性,还全面升级了易用性,让 StarRocks 更加顺滑好用。
其中,存算分离架构、数据湖分析、物化视图等重要特性都得到了进一步的优化和完善;易用性方面,从建表、表变更、数据导入、查询、到数据导出整条链路的运维操作都已变得更加简单。
随着 3.2 版本的发布,StarRocks 的优势不再限于性能卓越、功能全面,易用性也将成为一大特色。
StarRocks 3.2 版本的升级内容包括:
- 在建表中,优化随机分桶[1]、提供更快的 Schema Evolution[2]、提供 optimize table[3] 功能;在导入中,新增 PIPE[4] 和优化表函数 FILES[5];导出中提供了和导入相对应的易用语法,实现统一的导入导出;查询中提供了 HTTP SQL API[6] 和 Runtime Profile。让整条链路的易用性上升了一个大台阶。
- 存算分离架构功能上继续对齐存算一体,完善主键模型表的索引持久化功能。
- 数据湖分析继续优化了文件读取/谓词改写/分区裁剪/统计加速等很多场景下的查询性能,同时还提供了可读又可写的 Hive Catalog[7]、可以在同一个 Hive Metastore 或 AWS Glue 元数据服务中包含多种表格式的 Unified Catalog[8],实现更方便灵活的数据湖分析。
- 异步物化视图提供了 Iceberg/Paimon Catalog 分区级别的增量刷新,支持了自动尝试激活失效的物化视图,以及多项查询改写一致性相关优化、开启中间结果落盘等,让异步物化视图既稳定又好用。
提升易用性
3.2 版本重点在易用性上做了大量提升,让建表、数据导入导出等操作都变得更加简单和高效。在这一版本中,可以使用 optimize table 功能调整优化原有表结构、通过 PIPE 轻松从云存储 S3 或 HDFS 中导入大规模数据、使用 INSERT INTO FILES 统一数据导出……可以说是全链路地提升了系统的易用性。
01建表与表变更
- 在 3.1 版本中,明细模型的表支持了[随机分桶(Random Bucketing)][1]功能,让用户一般不再需要关注如何分桶、分多少桶的问题。3.2 版本中,系统进一步优化了分桶方式,会根据集群信息、导入中的数据量、以及导入方式按需动态调整 Tablet 数量,在 Tablet 特别多、以及较为实时的导入中批次特别多等情况下,能大量减少对内存的占用和 I/O 的开销,而创建出来的分桶大小也更符合实际动态数据量。
- 随着业务查询模式的变化,用户经常需要修改表结构/排序键、分区模式等来适应不同类别的查询性能要求。StarRocks 通过增强 ALTER TABLE 命令来提供 optimize table 的功能,让用户可以根据最新的业务场景和性能需要调整表结构、重组数据,包括重新设置分桶方式和分桶数、排序键,以及可以只调整部分分区的分桶数。
- 支持 Fast Schema Evolution 模式, 对 add/drop column 类型的 DDL 支持了更加轻量快速的修改方式。Fast Schema Evolution 不新创建 Tablet,而只是修改 FE 上的元数据,并且是同步完成,当返回客户端时就代表 Alter 任务已经完成,通常情况下可以在几毫秒内完成加减列的操作。可以在建表时通过设置表属性 fast_schema_evolution 为 TRUE 或 FALSE 开启或关闭 Fast Schema Evoluiton。
- 分区表支持设置动态降冷时间[9],相对原来的设置,能更方便进行分区的冷热管理。后续的版本中,StarRocks 也即将支持降冷成 Iceberg/Hive 表来帮助用户更灵活的管理冷热数据。
02 导入
- 支持使用 PIPE 命令从云存储 S3 或 HDFS 中导入大规模数据和持续导入数据。在导入大规模数据时,PIPE 命令会自动根据导入数据大小和导入文件数量将一个大导入任务拆分成很多个小导入任务穿行运行,降低任务出错重试的代价、减少导入中对系统资源的占用,从而提升数据导入的稳定性。同时,PIPE 也能不断监听云存储目录中的新增文件或文件内容修改,并自动将变化的数据文件数据拆分成一个个小的导入任务,持续地将新数据导入到目标表中,用户不再需要自己维护一个批量任务调度系统,大大简化了数据导入维护。

- 同时,也进一步补充和完善了表函数 FILES 的功能,新增功能包括:
- 支持导入 Azure 和 GCP 中的 Parquet 或 ORC 格式文件的数据。
- 支持 columns_from_path 参数,以能够从文件路径中提取字段信息。
- 支持导入复杂类型(ARRAY、MAP 及 STRUCT)的数据。

从功能上讲,INSERT from FILES[10] 已基本对齐 Broker Load,在性能上保持和 Broker Load 一致,而易用性上则大大超越了 Broker Load。你几乎可以像使用一个普通 Table 一样操作:很简单自然地用 SELECT 查看数据、用 WHERE 过滤数据、结合 INSERT 进行数据导入、甚至采用 CTAS 直接导入数据而无需提前建表。你不仅可以通过 columns_from_path 参数获取 Hive 等系统维护的分区数据中的分区列信息,还可以让系统自动进行 Schema Merge [preview],从而无感处理有 Table Schema 变动的不同文件数据。INSERT from FILES 作为统一的导入形态,后续将继续提供更丰富的功能和进一步提升易用性。
03 导出
- 和统一导入形式 INSERT from FILES() 相对应,本版本提供了对应的统一导出形式:INSERT INTO FILES()[11],能够将数据导出为 AWS S3 或 HDFS 中的 Parquet 格式的文件,从而实现统一的导入导出语法,大大提升了这一操作的便利性。同时,数据导出后,可以直接使用 SELECT from FILES() 来轻松检验数据。
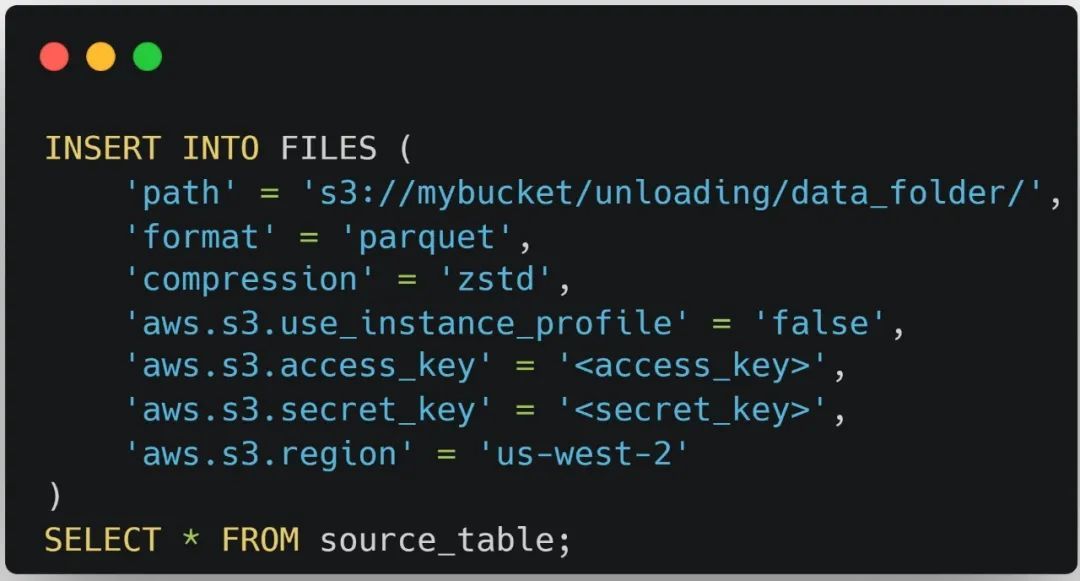
04 查询
- 支持 HTTP SQL API。用户可以通过 HTTP 方式访问 StarRocks 数据,执行 SELECT、SHOW、EXPLAIN 或 KILL 操作。在不具备 MySQL 客户端的情况下,也能轻松访问 StarRocks。
- 新增 Runtime Profile[12],以及基于文本的 Profile 分析指令[13](SHOW PROFILELIST, ANALYZE PROFILE, EXPLAIN ANALYZE),用户可以通过 MySQL 客户端进行 Profile 分析,能够直接知道最耗时的操作是哪些、分别占比多少,还可以通过在参数中指定节点来进一步获取更细节的资源消耗信息,方便定位瓶颈点并发现性能优化机会。这些功能也已合入到 3.1 版本。
如下图中的 runtime profile,此 query 还在执行中,通过几个小图标就能很清晰地了解到哪些 operator 已经完成,哪些正在运行、或者还未运行,以及截止到当前哪几个阶段最耗时。

存算分离架构
- 存算分离架构也在不断打磨,此版本支持了主键模型(Primary Key)表的索引在本地磁盘持久化的功能,从而使主键模型在存算分离架构下基本对齐存算一体架构,减少内存的使用。后续还会马上推出主键模型表的索引存在云存储中的功能,以消除机器异常或变更后因索引重建带来的查询和导入性能的较大波动。
- 在3.2后续版本中,Storage Volume 将增强 HDFS 相关的参数化配置,包括支持 simple 认证方式支持配置 username、Kerberos 认证、NameNode HA、ViewFs 。用户可以通过参数化的方式配置 HDFS 的相关信息,不再依赖 HDFS 相关的配置文件,通过配置信息参数化的方式,在一个 StarRocks 集群内,可以配置多个 HDFS 类型的 Storage Volume。
- 支持 Datacache 在多磁盘间均匀分布,用户可以挂载多块本地盘。
数据湖分析
- 优化了很多场景的下数据湖查询性能,包括优化 ORC/Paruqet/CSV 文件的读取/解压缩/字典解码性能、自适应 I/O 合并、更快的针对字典编码的谓词改写和按需字典译码、优化 count 操作性能、支持 Iceberg Catalog 的复杂分区列的分区裁剪,不断提升数据湖分析的极致性能。
- 支持通过 Analyze Table 收集 Hive 和 Iceberg 表的统计信息以加速后续查询。同内表一致,更多的统计信息会为 CBO 提供更多养料,从而生成更加合理的执行计划,提升查询性能。
- 3.1 版本已经支持了在 Iceberg Catalog 内创建库/表以及写入能力,此版本新增支持在 Hive Catalog 中创建、删除 Database 以及 Managed Table,并支持通过使用 INSERT 或 INSERT OVERWRITE 语句写入数据到 Hive Catalog 的 Managed Table,相当于导出了数据。这意味着用户可以通过 StarRocks 完成湖上数据的加工,或者将内部表的数据写回湖上开放格式归档并为后续其他数据应用提供便利。为数据湖 Single Source of Truth 提供了能力基础。
- 支持 Unified Catalog。在同一个 Hive Metastore 或 AWS Glue 元数据服务中包含多种表格式(Hive、Iceberg、Hudi、Delta Lake 等)时,可以通过创建 Unified Catalog 来统一管理和访问,简化 Catalog 的创建和使用。不仅避免了不必要的重复创建,更让终端用户可以不再关心具体的表格式。尤其在数据湖升级过程中(例如从 Hive 迁移升级到 Iceberg 或 Hudi),让用户不用感知底层的迁移进度,就能享受统一、丝滑的查询体验。
- 支持外部 Catalog 的系统表(Information Schema)。用户可以更方便地获取结构化的库表信息,同时也为外部系统(如BI)与 StarRocks 的交互提供更多便利。
物化视图
01 异步物化视图
- 2.5.5 以上版本中,基于 Hive Catalog 创建的外表异步物化视图已经支持了分区级别的增量刷新,此版本中新增了基于 Iceberg Catalog 或 Paimon Catalog 创建的外表物化视图也支持分区级别的增量刷新,能大大降低刷新的资源消耗。
- 支持了自动尝试激活失效的物化视图。在真实场景中,很多操作会导致物化视图失效,例如基础表删除重建、原子替换,或者用于建模的视图发生了schema change,会导致查询改写不能生效。3.2 版本中,StarRocks 会尝试对失效的物化视图进行激活,让查询更加速加丝滑。
- 在查询透明改写的数据一致性方面也做了一些改进,用户可以根据业务对于查询性能和数据一致性的要求,通过配置合适的参数值,得到一个在查询性能和数据一致性要求之间较佳的平衡点,对于基于实时数据的物化视图和基于外表的物化视图特别有用。
- 更多开发者功能:支持物化视图的 Trace Rewrite 和 Query Dump。Trace rewrite 可以用于分析物化视图透明改写失败的场景,为后续改写优化的开发提供便利;Query Dump 新增了物化视图的信息,即如果引用了物化视图,会将物化视图信息一起写到 Dump 信息中,用于查询分析。
02 同步物化视图
- 在 3.1 版本中,同步物化视图的创建中已经支持了 CASE-WHEN、CAST、数学运算等表达式,以及支持设置多个聚合列;此版本中,新增支持创建带有 WHERE 子句的同步物化视图,进一步拓展同步物化视图的能力边界。
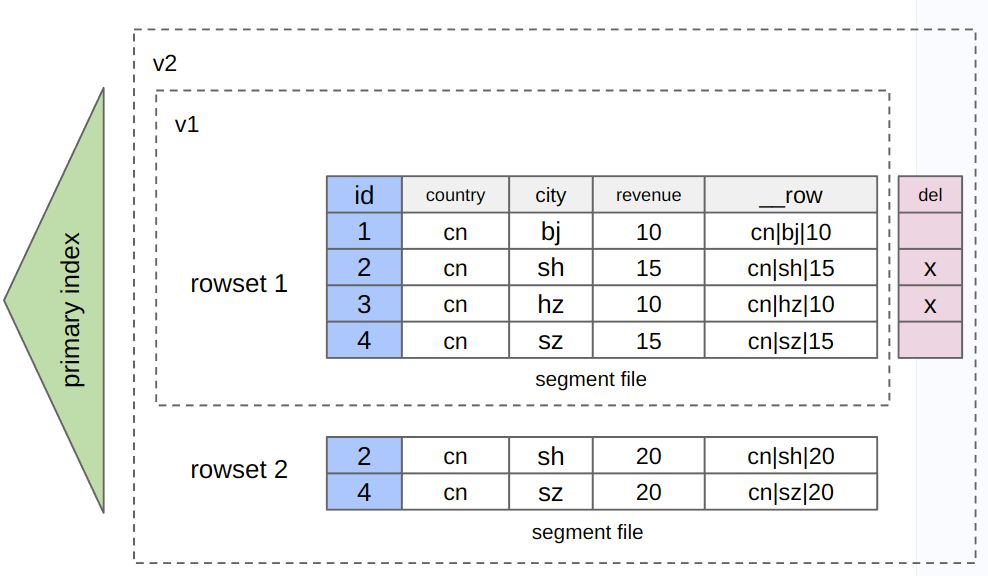
行列混存
在 3.2 后续版本中 StarRocks 将在主键模型上支持行列混存的表存储格式,行列混存表通过增加隐藏列 __row 存储整行数据。用户可以在建表时在 PROPERTIES 中配置 "STORE_TYPE" = "column_with_row" 指定该表为定行列混存模式。行列混存主要的使用场景包括:
- 基于主键的高并发点查
- 数据部分列更新的场景
通过这项优化,StarRocks 旨在为用户提供更高效的并发查询能力和数据更新能力,同时保留了原有列存的高效分析能力。
其它
- 支持预处理语句(Prepared Statement),可以提高处理高并发点查查询的性能,同时也能有效防止 SQL 注入。
- 优化主键模型(Primary Key)表持久化索引功能,优化内存使用逻辑,同时降低 I/O 的读写放大。
- 主键模型(Primary Key)表支持本地多块磁盘间数据均衡。
- 新增了很多函数,包括一些字符串函数、日期函数、窗口函数 、等等。
- 提升与 Metabase、Superset 的兼容性,支持集成 External Catalog。
Release note:
https://github.com/StarRocks/starrocks/blob/main/docs/zh/release_notes/release-3.2.md
下载:
https://www.mirrorship.cn/zh-CN/download
直播回放
相关链接
[1]https://docs.starrocks.io/zh/docs/table_design/Data_distribution/#%E9%9A%8F%E6%9C%
BA%E5%88%86%E6%A1%B6%E8%87%AA-v31
[2]https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-definition/CREATE_TABLE/#properties
[3]https://docs.starrocks.io/zh/docs/table_design/Data_distribution/#%E5%BB%BA%E8%A1%
A8%E5%90%8E%E4%BC%98%E5%8C%96%E6%95%B0%E6%8D%AE%
E5%88%86%E5%B8%83%E8%87%AA-32
[4]https://docs.starrocks.io/zh/docs/loading/s3/#%E9%80%9A%E8%BF%87-pipe-%E5%AF%BC%E5%85%A5
[5]https://docs.starrocks.io/zh/docs/sql-reference/sql-functions/table-functions/files/
[6]https://docs.starrocks.io/zh/docs/reference/HTTP_API/SQL/
[7]https://docs.starrocks.io/zh/docs/data_source/catalog/hive_catalog/#%E5%90%91-hive-%E8%A1%A8%E4%B8%AD%E6%8F%92%E5%85%A5%E6%95%B0%E6%8D%AE
[8]https://docs.starrocks.io/zh/docs/data_source/catalog/unified_catalog/
[9]https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-definition/CREATE_TABLE/#properties
[10]https://docs.starrocks.io/zh/docs/loading/s3/
[11]https://docs.starrocks.io/zh/docs/unloading/unload_using_insert_into_files/
[12]https://docs.starrocks.io/zh/docs/administration/query_profile/#runtime-profile
[13]https://docs.starrocks.io/zh/docs/administration/query_profile/#%E5%9F%BA%E4%BA%8E%
E6%96%87%E6%9C%AC%E7%9A%84-query-profile-%E5%88%86%E6%9E%90


