
StarRocks 算子落盘:让大查询又快又稳
本文发表于: &{ new Date(1698940800000).toLocaleDateString() }
内存是对数据库非常重要的数据存储介质,它承载了所有查询计算的请求,在提升性能、实时分析等场景都有着重要的作用。正是由于内存如此重要,经常会遇到内存不够的情况,从而导致查询被强制终止,甚至对线上其他查询性能产生负面影响。例如:
- 在轻量级 ETL 或查询加速场景(如 INSERT INTO AS SELECT 任务,或构建大宽表的物化视图进行建模),由于涉及查询通常是多张大表关联或者是高基数聚合等复杂计算,从而在实际任务计算时难以应用查询优化,导致内存占用过高,引发任务失败
- 在 ad-hoc 随机探查中,分析师偶然写了非常复杂、涉及到非常大数据集的查询,导致查询失败
实际上,相比于线上关键业务的查询,这类偶发查询和 ETL 任务对查询性能的要求通常并不高。我们只需要它们能够在有限的资源下平稳地运行出结果,而不要对在线业务产生影响,以免因小失大。
01
中间结果落盘
内存现在交通管理,请绕行磁盘
为了更加合理地利用有限的内存资源,StarRocks 自2.2版本就推出了资源隔离功能,通过资源组来对内存及 CPU 进行分配。如果把内存比作数据计算的高速公路,资源隔离就像是公交车道。它虽然一定程度上隔离了线上查询和 ETL、偶发性大查询,让线上查询能有独立车道、更加稳定,但并没有解决如何让其他车道的 ETL 和大查询能够平稳通行、不发生交通堵塞甚至事故。
自3.0版本起,StarRocks 推出了中间结果落盘功能( Spill )。简单来讲,中间结果落盘通过将查询中涉及的大算子的中间结果暂时写入磁盘,从而释放内存空间。中间结果落盘就像是交警,它能够在内存阻塞的时候进行交通管制,让部分中间结果绕行磁盘等待,从而可以确保查询操作继续执行,而不会因内存不足而失败。
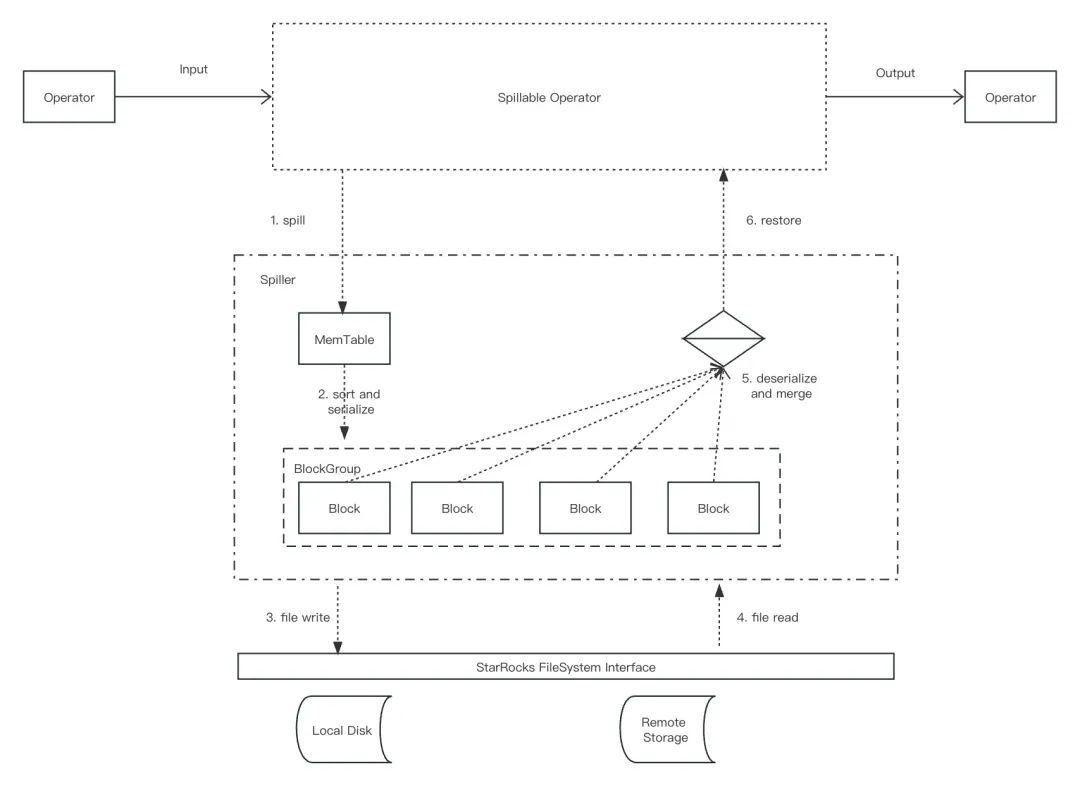
目前,StarRocks 支持聚合算子、排序算子、HASH JOIN(LEFT JOIN、RIGHT JOIN、FULL JOIN、OUTER JOIN、SEMI JOIN 以及 INNER JOIN)算子的中间结果落盘。
通过落盘,查询使用的内存可以被放大十倍,从而可以支持更多大查询以及 ETL 的应用场景。
02
算子落盘
内存的智能管理助手
然而,中间结果落盘是一种用磁盘空间换内存空间的方式,一定会涉及到额外的 I/O 开销以及性能损耗。如何能够根据内存情况动态地进行落盘、保证查询性能损耗较低是一个比较大的挑战。
StarRocks 支持强制落盘与自动落盘两种落盘机制。
在自动落盘模式下,系统会自动根据当前内存的占用情况实时判断当前查询是否需要开启落盘。
具体来讲,在每个算子真实处理数据之前,StarRocks 会预估需要申请多少内存才可以执行完成,并尝试预留。如果预留结束仍旧没有超过查询内存限制的80%,则不会触发算子落盘,否则即触发算子落盘预留内存为其他查询服务。
03
查询更稳定,性能仍旧领先
基于 StarRocks 3.1 版本针对 TPC-DS 10T 测试集来测试中间结果落盘的能力。
1.在极小的集群上是否能够稳定跑出结果?
集群配置:1FE (8C 16G) 3BE (16C 64G),每个BE下挂载两块阿里云PL1级别云盘
在没有开启中间结果落盘时,99个查询中有15个查询失败。在开启中间结果落盘后,所有查询均执行成功。
算子落盘显著提升了查询稳定性。
2.性能如何?
在相同的机器配置下对 StarRocks 和 Spark 进行了对比。在均开启自动算子落盘、查询平稳跑成功的情况下,
StarRocks 整体查询性能是 Spark 的4.35倍。
04
物化视图+中间结果落盘
灵活加速的利器
在重新定义物化视图,你必须拥有的极速湖仓神器 中,我们介绍了如何通过物化视图来对湖仓进行灵活加速。在湖仓一体架构中,物化视图起到关键作用,在数据建模、透明加速、增量计算中都能够进一步降低数据处理的复杂度、提高查询性能和优化数据的时效性,使得用户在数据架构升级的同时,能够享受到使用体验的升级。
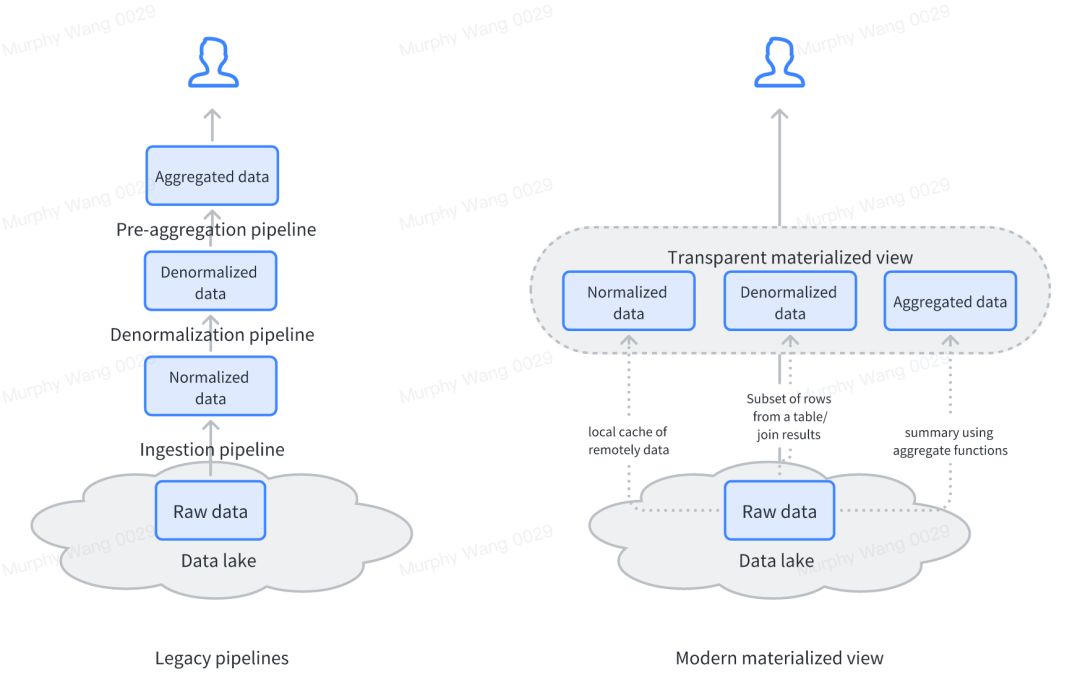
试想一种很常见的查询加速场景:ODS 层内包含多张事实表和维度表,查询经常需要在多表关联的基础上再进行各类聚合计算,频繁查询对内存消耗极大,也会对查询性能有一定影响。一个直观的想法是构建物化视图,并利用物化视图的智能查询改写功能,做到透明加速。
为了能够让更多的查询被透明改写到物化视图上,我们建议对查询中最公共的部分创建物化视图。在这种场景下,即是构建不带谓词的大宽表物化视图,后续所有涉及相关表的查询均可以被自动改写,详情请见:
https://docs.starrocks.io/zh-cn/latest/using_starrocks/query_rewrite_with_materialized_views
然而由于不带有谓词,物化视图的构建和刷新就无法应用任何下推优化,通常需要将巨大的多张表进行完整关联,对内存是一个不小的挑战。
物化视图和中间结果落盘的结合正是应对这种场景。我们以 TPC-H 1TB 测试集为例,该测试集内涉及大量订单表与维度表聚合后上卷筛选的查询。
测试结果:
集群信息:StarRocks 3.1,1 FE 3 BE,16Core 64GB,每台 BE 600GB 磁盘
1.直接查询
a.在直接查询的情况下,很多查询因为内存超限而失败。
b.开启中间结果落盘后,所有查询都能稳定跑出结果。
2.创建大宽表物化视图对查询进行加速
a.在直接构建的情况下,构建因内存超限失败。
b.开启中间结果落盘后,物化视图可以成功构建与刷新,并且查询速度有显著提升。
物化视图加速SQL示例:
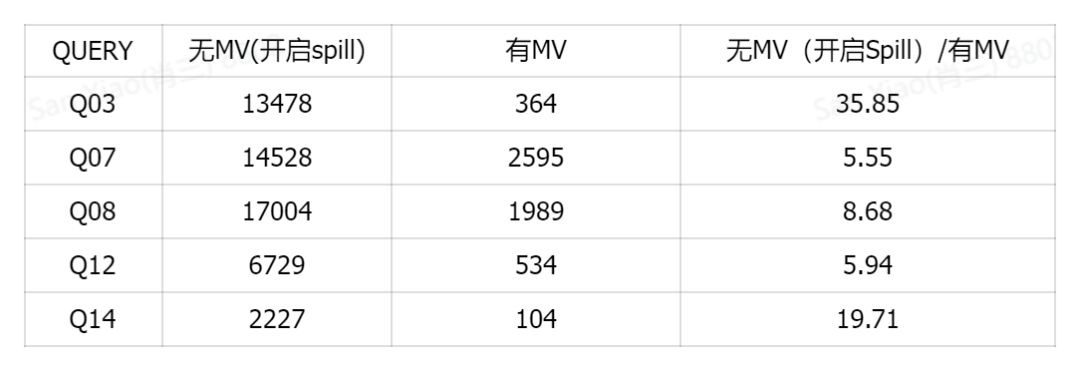
从案例中可以看出:
- 在直接查询的情况下,中间结果落盘显著地提高了查询的稳定性
- 中间结果落盘提高了物化视图构建和刷新的成功率,创建物化视图后对查询有显著加速作用
未来展望
中间结果落盘是 StarRocks 湖仓一体架构中非常重要的一环。在大数据量下的复杂分析、数据处理、物化视图构建等场景都发挥着重要作用。释放了内存枷锁,解决了更多用户的分析场景和需求。对于复杂计算的查询或是数据加工与建模,都能够在资源可控的情况下平稳运行。未来,中间结果落盘还会与资源隔离、multi-warehouse 能力进行结合,实现更加细粒度的资源隔离与资源管控,让您能够对不同的 workflow 进行定制化的资源配置和使用规则。


