
同时满足实时及离线数据分析需求!京东到家的StarRocks应用实践
本文发表于: &{ new Date(1640707200000).toLocaleDateString() }
作者:李德宏, 京东到家大数据开发工程师
京东到家是达达集团旗下中国领先的本地即时零售平台,依托达达快送和零售合作伙伴,为消费者提供超市便利、生鲜果蔬、医药健康、3C 家电、鲜花绿植、蛋糕美食、服饰运动、家居时尚、个护美妆等海量商品约1小时配送到家的即时消费服务体验。海博系统是京东到家基于多年深耕零售 O2O 以及服务众多零售企业数字化转型的经验,自主研发的集商品、用户、营销、履约、数据五大数字化赋能模块于一体的全渠道数字化解决方案。
业务现状
海博系统建设了全渠道全业态融合的数据中台,可以同时满足实时及离线数据分析需求,提供可配置的数据看板功能,能有效提升商家运营效率,助力商家线上业务增长。海博数据中台目前支撑了超百亿级数据的统计分析,包括销售、运营、品类、履约等多主题经营分析数据报表70+, 涵盖了商家、门店、渠道、省、市等多维度分析指标350+。
平台数据量大,根据源表数据计算,数据中台日增数据量在数亿级别;查询分析维度多,以商品分析为例,查询维度包括省、市、商家、门店、渠道、品牌、子品牌以及不同时间范围的组合,组合后查询维度高达上百种;准实时数据推送频率高:数据中台的实时数据是以微批方式处理,窗口时间为10分钟,这样每天会有大量的准实时数据推送任务要执行,对数据存储引擎的实时导入性能要求较高。
StarRocks 可以快速存储并查询数亿量级的数据,支持高效的多维数据分析,加上产品本身的高可用、高可靠等特性,很好地支持了我们目前的业务场景。
数据中台数据流转图如下图所示:

商品、库存、订单等系统产生的源数据信息落库在 MySQL,经由数仓抽数后进行一系列加工处理,将计算好的结构化数据存储在统一的数据仓库中,根据数据的特点,我们使用了 MySQL 和 StarRocks 数据库并存的方式进行数据存储。集群会根据数据的不同特征采取不同的推送方式,实时数据使用 stream load、离线数据使用 broker load,结合我们自研的调度平台等多种方式进行数据推送, StarRocks 现阶段存储数据量整体占比估算为80%+,未来 StarRocks 也会作为我们数据应用层最主要的存储引擎,将充分利用 StarRocks 的向量化及物化视图等技术,支撑数据中台数据量的快速增长。
StarRocks 实践经验
遇到的挑战及解决方案
StarRocks 是面向列式存储的分布式架构,虽然兼容 MySQL 协议,但是与 MySQL 也有一些不同的特性。数据中台是首次接入 StarRocks,不可避免的,在实际开发过程中我们也踩到了一些坑。下面是我们遇到的问题汇总及解决方案:
1 分页查询使用不同的排序列,导致查询结果不一致问题
部分建表语句:
CREATE TABLE `api_hw_prd_sku_brand_sku_di` (
`create_date` date NOT NULL COMMENT "日",
`upc` VARCHAR ( 255 ) NOT NULL COMMENT "upc",
`stk_avl_cnt` BIGINT ( 20 ) NOT NULL COMMENT "",
...
) ENGINE = OLAP
DUPLICATE KEY (`create_date` )
COMMENT "商品表"
PARTITION BY RANGE ( `create_date` ) (PARTITION p20200726 VALUES [ ( '2020-07-26' ), ( '2020-07-27' ) ) ) DISTRIBUTED BY HASH ( `brand_trademark_id`, `vender_id` ) BUCKETS 10 PROPERTIES (
"replication_num" = "3",
...
);分别使用2个分页查询语句进行测试,查询排序列分别为 UPC 和 create_date :
分页查询语句1,使用 upc 列进行排序:
select stk_avl_cnt from api_hw_prd_sku_brand_sku_di
where create_date = ‘xx’order by upc desc limit ‘xx’,‘xx’分页查询语句2,使用 create_date 列进行排序:
select stk_avl_cnt from api_hw_prd_sku_brand_sku_di
where create_date = ‘xx’order by create_date desc limit ‘xx’,‘xx’为了验证问题,我们把查询的结果进行累加。以下为4次测试的结

从结果中可以看到,order by UPC 排序后累加的结果是一致的,4次结果都是19908,order by create_date 每次的结果都不相同21663,19344,18457, 15856,那么是什么原因导致的使用 order by create_date 排序,每次查询结果都有差异呢?
原因为 StarRocks 采用分布式存储数据,一条分页语句在查询执行过程中,一个 job 会把多个 task 任务分发到多个 BE 中并发的查询 tablet 中数据,最后进行数据的汇总,由于 order by 指定的列区分度低,导致查询时每个节点返回的数据顺序不一样,这样某条数据在第 N 页和 N+1 页查询都被命中,导致最终的排序结果不一样,所以最后累加的结果不一致。

解决方案:提高 order by 后指定列的区分度,在建表时我们新增了一个类似 MySQL 中 id 特性的字段,在分页查询时,除指定业务需要排序的列以外,另加上此 id 列,保证查询的数据整体是有序的。
2 一条 SQL 中包含多个 case when 语句,导致执行耗时长问题
场景是分析商品明细表,统计出每天的在售、铺货、动销商品数等几个指标的数据。StarRocks 表中数据量为亿级,以下是优化前 SQL 执行耗时情况:

在执行计划中可以看到 SQL 耗时为 4s468ms,性能非常低,是不可以接受的。分析原因是 SQL 中包含多个 case when 语句,数据要从表中查询出来,在通过 case when 指定的条件进行过滤,在分布式的场景下,数据在多机之间传递,非常消耗性能。
解决方案:将 SQL 进行拆分,利用 StarRocks 支持高并发查询的特性,将多个 SQL 并行执行,结果数据进行汇总,提高整体的查询效率。
以下是通过 StarRocks 提供的 Profile 工具分析出的优化后 SQL 执行耗时情况:

拆分后的 SQL 并行执行最长的为 248ms ,性能提高了 18 倍。
3 数组类型使用及问题
场景是给商品打上各种属性标签,比如:品类->生活用品,价格带-> 15-20 (元),也就是说商品和属性是一对多的关系。常规数据存储格式会把商品和对应的每个属性分行进行存储,这样同一商品包含多个属性时,就会保存多条数据了。

采用这种格式存储数据,当页面通过商品的多个属性条件分页查询过滤商品时:

在查询时,需要进行商品主表与商品属性表 Join 过滤商品,由于商品和属性一对多的关系,所以 Join 时产生笛卡尔积一个商品会有多条记录。
解决方案:可以采用商品属性表使用子查询过滤商品后再与主表 Join 的方式解决,但是我们想可不可以让数据在存储时就是一对一的关系,既可以保证查询效率,还可以简化 SQL 开发。此时数组类型就派上用场了。StarRocks 当前支持多维数组嵌套、数组切片、比较、过滤等特性,可以很好地支持 A / B Test、用户标签分析、人群画像等场景。
商品属性表部分建表语句:
CREATE TABLE `sku_and_attribute_info` (
...,
`upc` VARCHAR(255) NOT NULL COMMENT “upc”,
`attribute_info` ARRAY<VARCHAR(1000)> NOT NULL COMMENT “商品属性信息”,
...
) ENGINE = OLAP商品属性采用数组类型时,一个商品对应的多个属性只保存一条记录,以6903148044698 品为例,数据存储格式如下图:
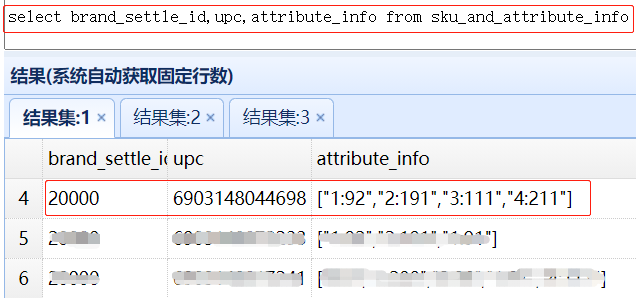
以数组方式建表后,在分页查询时,可以使用数据的array_contains (any_array, any_element)函数,将商品主表与属性表直接进行 Join 查询了。
使用示例:
SELECT s.* FROM api_hw_prd_sku_brand_sku_di s
INNER JOIN sku_and_attribute_info a on s.upc = a.upc and array_contains(a.attribute_info, 'xxx') = 1
WHERE s.upc = 6903148044698
ORDER BY s.upc
LIMIT 0,10但是真正在使用数组类型进行分页查询时,发现返回的数据,与预期结果并不一致。针对出现的问题,我们用2个测试用例执行看下结果有什么不同(同样以 6903148044698 品为例):
用例 1 :

用例 2 :

从以上2个结果可以看出,用例2的结果与源数据是不一致的。那么问题出在哪里呢?
仔细观察 SQL 语句,只有 brand_settle_id 字段的传值类型不一样。用例1是字符串,用例2是数字,以字符串类型传入时,结果是正确的。针对出现的问题,我们与 StarRocks 官方进行了沟通确认,验证在1.17版本中确实存在此问题,并在1.18版本中得到了修复,问题得到了解决。
SQL 语句使用经验总结
StarRocks 虽然兼容 MySQL 协议,可以使用 JDBC 客户端进行连接,但是 StarRocks 是分布式的 MPP 数据库,在 SQL 语句执行过程与 MySQL 底层实现原理还是有区别的。在一些关键词的配合使用上,与 MySQL 还是有部分差异需要注意的,下面是我们在开发过程中遇到的几点差异:
1、SQL 中包含 group by 语句时,group by 指定列不参加聚合操作,select 中的其他列都要指定聚合函数。
正确示例:
select a, max(b), max(c) from tx group by a错误示例:
select a, b, c from tx group by a以上示例中,select 查询的 b 和 c 列没有参与到 group by 分组中,所以查询时必须要指定聚合函数。
2、SQL 中包含 limit 语句,当从查询第二页开始,limit 后要加 order by 排序列,排序列区分度一定要高,否则一条数据可能会被重复查出。
正确示例:
select id , b, c from tx limit 10, 10 order by id desc错误示例:
select id , b, c from tx limit 10, 10以上示例中,进行分页查询时,没有指定 order by 情况下,MySQL 有默认的处理排序机制,StarRocks 必须指定排序列才可以进行分页查询。
未来工作
为更好地满足用户的多维分析场景,提高数据的查询效率,用数据驱动业务,在未来使用 StarRocks 过程中,主要的方向有以下几点:
- 通过对用户的行为分析,统计出报表高频的查询场景,使用物化视图进行数据的预聚合,进一步提升查询性能。
- 对于商品、订单等单维度聚合统计类型的报表,这类报表维度相对固定,并且没有查询明细数据的需求,因而可以采用聚合模型来替代明细模型,这样不仅可以提升聚合查询性能,也能减少数据存储,节约开发成本。
- 优化多表 Join 分析查询场景的性能,使用 Colocation Join ,通过预先的数据分布,减少节点间网络传输带来的延迟开销,进一步提升查询性能。
- 使用 StarRocks 统一数据分析层,并在更多的业务中使用 StarRocks 。


