

深入解析数据模型与数据建模
本文发表于: &{ new Date(1755792000000).toLocaleDateString() }
什么是数据模型与数据建模?
数据模型本质上是组织内数据结构和业务规则的蓝图。它并非数据本身,而是对数据特征的抽象描述,定义了数据元素、它们之间的关系以及如何组织和存储。而数据建模,则是创建这一蓝图的过程。它是一项战略性工作,旨在通过符号、文本和图表的组合,将原始、零散的数据转化为结构清晰、机器可读且对业务有价值的信息资产。

一个精心设计的数据模型,能够确保数据的一致性、减少冗余,并为后续的数据分析、应用开发和决策支持提供一个稳固且易于理解的基础。它让数据架构师、业务分析师和开发人员能在同一个“语境”下沟通,有效避免因数据定义不清而导致的开发错误和沟通壁垒。
数据模型的层次与核心技术
数据建模并非单一行动,而是一个分层演进的过程,通常涉及多种技术选型。理解其核心类型和技术,是确保模型能够准确反映业务并被技术高效实现的关键。
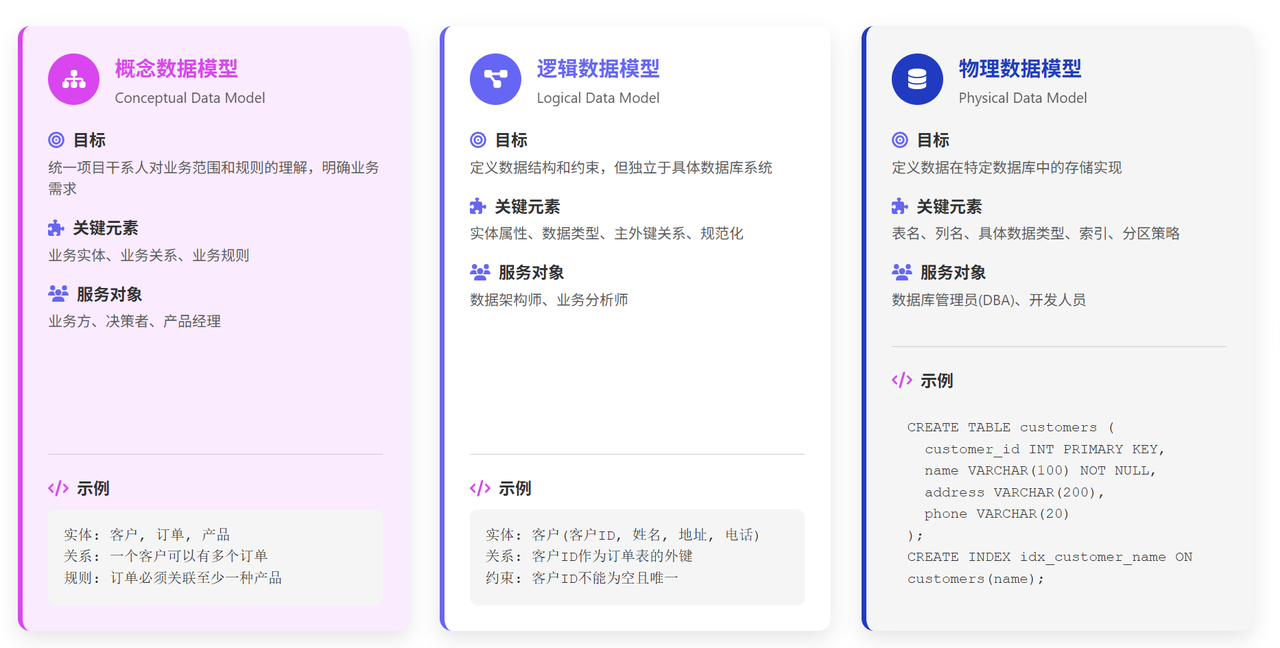
数据模型的三个核心层次
数据建模过程通常遵循从抽象到具体的三个层次,确保业务需求能够准确地转化为技术实现。
- 概念数据模型 (Conceptual Data Model): 这是最高层次的抽象视图,主要服务于业务方和决策者。它关注“是什么”,定义了核心的业务实体(如客户、产品、订单)及其之间的业务关系,不涉及任何技术细节。例如,一个电商业务的概念模型会清晰地展示“一个客户可以有多个订单,一个订单包含多种产品”这样的业务规则。它的主要目标是统一项目干系人对业务范围和规则的理解。
- 逻辑数据模型 (Logical Data Model): 逻辑模型是概念模型的细化和具体化,服务于数据架构师和业务分析师。它定义了每个实体所包含的属性(如客户实体的“客户 ID”、“姓名”、“地址”)、数据类型和实体间的主外键关系,但仍然独立于具体的数据库管理系统(DBMS)。这一层是数据库设计的核心蓝图,确定了数据的结构和约束。
- 物理数据模型 (Physical Data Model): 这是最具体的技术实现层,服务于数据库管理员(DBA)和开发人员。物理模型描述了数据在特定数据库中将如何存储,包括具体的表名、列名、数据类型、索引、分区策略等。它需要考虑存储空间、查询性能和数据库特性。例如,在物理模型中,会明确指出“客户 ID”字段是整数类型、作为主键,并为其创建索引以加速查询。
主流的数据建模技术
根据不同的应用场景和分析需求,业界发展出了多种建模技术。
- 关系数据建模 (Relational Modeling): 这是应用最广泛的技术之一,它将数据组织在二维表中(行和列),通过键(Key)来建立表与表之间的关联。关系模型遵循严格的范式理论(如第三范式 3NF),旨在最大限度地减少数据冗余,保证数据的一致性。它非常适合交易型系统(OLTP),如客户关系管理(CRM)和订单处理系统。
- 维度数据建模 (Dimensional Modeling): 专为数据分析和报告(OLAP)场景设计。它将数据分为“事实表”和“维度表”。事实表存储核心的、可度量的业务指标(如销售额、库存量),而维度表则存储描述性属性(如时间、地区、产品类别),形成经典的“星型模型”或“雪花模型”。这种结构虽然存在一定的冗备,但极大地简化了查询逻辑,非常有利于快速的多维分析和商业智能(BI)报表。
StarRocks 数据模型解决方案:平衡性能与灵活性
StarRocks 作为新一代实时分析数据库,提供了多种数据模型以适应不同的分析场景,同时在保持灵活性的基础上实现极致性能。

聚合模型(Aggregate Key)
聚合模型专为需要频繁聚合计算的场景设计,它在数据导入阶段自动执行预聚合,大幅减少存储空间和提升查询性能。适用场景包括:
- 指标分析系统:如销售统计、网站流量分析
- 监控系统:如服务器性能监控、业务指标监控
- 实时仪表盘:需要频繁刷新的业务驾驶舱
聚合模型通过定义聚合键和聚合函数,能自动合并相同键的多条记录,计算结果存储在聚合列中。经验表明,在适合的场景下,聚合模型可以将存储空间减少 90%以上,查询性能提升 5-10 倍。
唯一键模型(Unique Key)
唯一键模型确保指定列组合的唯一性,适用于需要实时更新数据的场景,如:
- 用户画像系统:实时更新用户标签和属性
- 库存管理:实时反映商品库存变化
- 配置中心:管理系统配置信息
唯一键模型会自动以新记录覆盖旧记录(基于唯一键判断),确保数据一致性。与传统数据库不同,StarRocks 的唯一键模型采用了列存优化设计,即使在高频更新场景下也能保持优异性能。
主键模型(Primary Key)
主键模型是 StarRocks 最新的表模型类型,结合了行存和列存的优势,特别适合:
- 实时数据湖分析:直接分析变更频繁的源数据
- HTAP 场景:同时支持事务处理和分析处理
- CDC 数据实时分析:处理从业务数据库捕获的变更数据
主键模型采用了行级别更新和版本控制机制,支持高效的点查询和范围扫描,同时通过后台 Compaction 过程优化存储结构,平衡了更新性能与查询性能。
数据湖加速模型
除了内部表模型,StarRocks 还提供了强大的外表功能,能够直接查询存储在数据湖中的数据,并通过多种优化技术提升查询性能:
- 智能缓存:自动缓存热点数据,减少 IO 操作
- 谓词下推:将过滤条件推送到数据源,减少数据传输
- 动态分区裁剪:智能识别并只读取必要的数据分区
- 物化视图加速:为外表创建物化视图,提供预计算结果
通过这些技术,StarRocks 能够为数据湖中的各类文件格式(如 Parquet、ORC、CSV 等)和表格式(如 Hive、Iceberg、Paimon 等)提供接近内部表的查询性能。
数据建模不仅是一项严谨的技术任务,更是连接原始数据与商业洞察的关键桥梁。从高层级的概念规划,到精细的逻辑设计,再到具体的物理实现,一个清晰、高效的数据模型为企业理解和利用其最宝贵的数据资产奠定了坚实的基础。
然而,模型的价值最终体现在其分析效率上。一个设计再完美的蓝图,如果缺少一个强大的执行引擎,也难以转化为实际的业务价值。正如文中所探讨的,StarRocks 凭借其为极速分析而生的架构,能够让企业在复杂的维度模型或关系模型上实现毫秒级的查询响应,打破了传统数据分析的性能瓶颈。这不仅是技术的升级,更是推动企业建立真正数据驱动决策文化的关键一步。


