

ETL:数据提取、转换和加载
本文发表于: &{ new Date(1755878400000).toLocaleDateString() }
什么是ETL?
ETL是“提取(Extract)、转换(Transform)、加载(Load)”三个词的缩写,它描述了一个经典的数据集成流程。该流程的目标是将分散在不同业务系统、数据库或文件中的数据进行整合,经过清洗和处理后,统一汇入一个集中的数据存储库(通常是数据仓库),以便进行后续的商业智能(BI)分析、报表制作和数据挖掘。
在数据驱动决策的商业环境中,ETL扮演着数据“搬运工”和“加工厂”的关键角色,它是确保数据质量、一致性和可用性的基础,为企业提供了一个统一、可靠的数据视图。可以说,几乎所有依赖历史数据进行分析的企业,其背后都有ETL流程在默默支撑。
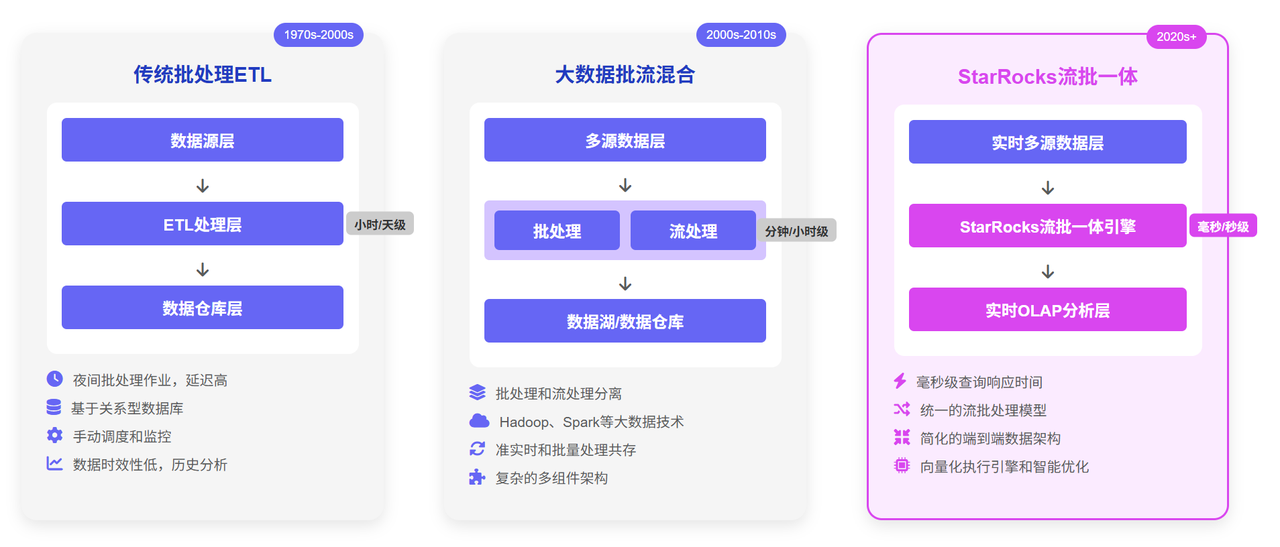
ETL的演进:从ETL到ELT的转变与新挑战
随着数据量级的爆炸式增长和业务对时效性要求的提高,传统ETL流程的局限性开始显现。其“先转换、后加载”的模式,需要在数据仓库之外设置一个专门的暂存区和转换服务器,这不仅增加了架构的复杂性,批处理的模式也导致数据延迟通常以小时甚至天为单位,难以满足实时决策的需求。为了应对这些挑战,数据架构领域出现了新的模式——ELT(提取、加载、转换)。
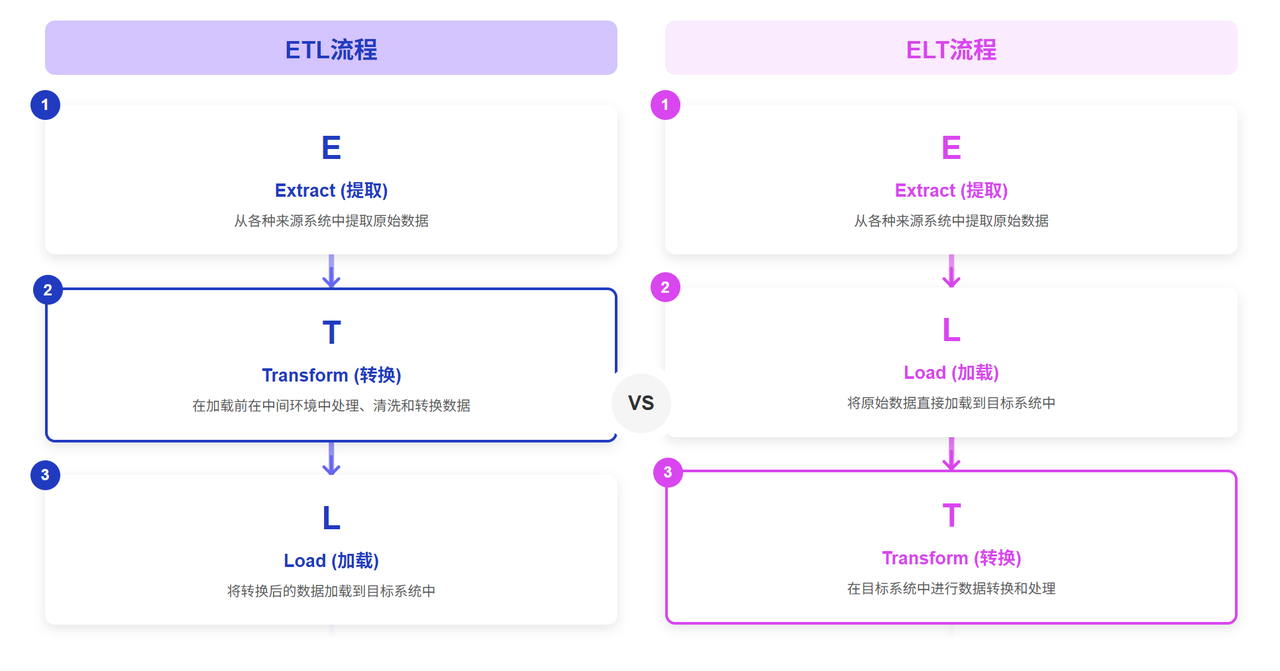
从ETL到ELT:转换环节的后移
ELT与ETL的核心区别在于它颠覆了“转换”和“加载”的顺序。ELT模式将从数据源提取的原始数据或半结构化数据,直接加载到目标数据仓库或数据湖中,然后利用目标存储强大的计算能力来进行数据转换。这种模式的兴起得益于云数据仓库技术的成熟,它简化了数据管道,将复杂的计算任务交给了可弹性扩展的目标系统。这使得企业能够更快地将原始数据集中起来,为数据科学家和分析师提供了更大的灵活性,可以直接访问和探索未经处理的原始数据。然而,ELT也带来了新的问题:它对目标数据仓库的计算性能提出了极高的要求,尤其是在处理高并发的即席查询和复杂转换时,成本和性能可能会成为瓶颈。
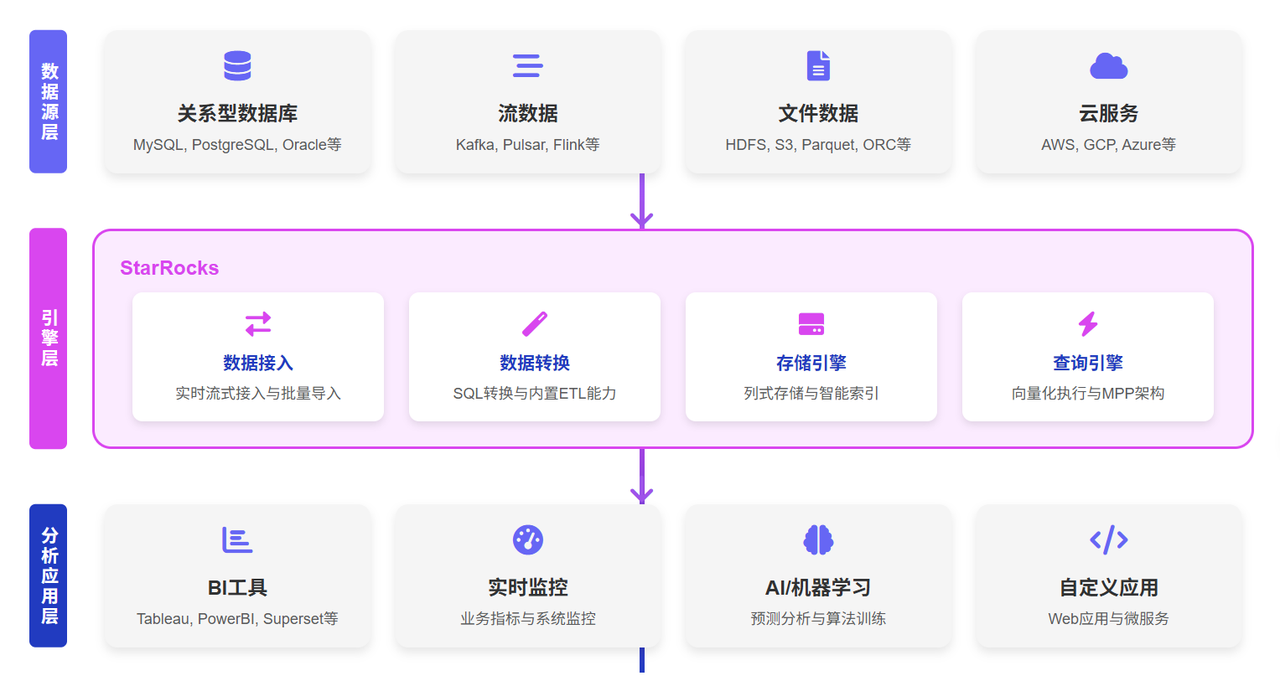
StarRocks如何革新ETL/ELT流程,赋能实时分析
无论是传统的ETL还是后续演进的ELT,其核心挑战都逐渐聚焦于如何平衡数据处理的效率、成本和时效性。新一代的分析型数据库正在通过技术革新,为这一难题提供更优解。作为一款为实时分析而设计的数据库,StarRocks(其企业版为镜舟数据库)通过其独特的架构,为现代数据管道带来了新的可能性。
StarRocks并非简单地取代ETL工具,而是通过优化数据管道的“L”和“T”环节,极大地提升了整体效率。
统一的实时与批处理能力
StarRocks打破了传统实时处理与批处理的界限,提供了统一的数据处理能力:
- 多种导入方式支持:StarRocks支持Stream Load、Routine Load、Broker Load、Spark Load等多种导入方式,可满足不同场景的ETL需求,无论是实时流数据还是批量历史数据。
- 实时数据摄入:借助Routine Load,StarRocks能够直接从Kafka等消息队列系统实时摄取数据,将ETL延迟从分钟级降至秒级。
- 灵活的转换能力:通过内置的数据转换功能和强大的SQL能力,StarRocks能在数据加载过程中同时完成转换操作,实现"边加载边转换"的高效处理模式。
湖仓一体架构简化ETL流程
StarRocks的湖仓一体架构从根本上简化了ETL流程:
- 直连数据湖:StarRocks可以直接查询Hive、Iceberg、Paimon等数据湖中的数据,无需传统的ETL过程即可进行分析,大幅简化了数据处理流程。
- 物化视图加速:通过异步物化视图,StarRocks能够自动维护预计算结果,在保持数据新鲜度的同时显著提升查询性能,将复杂ETL转换预计算化。
- 统一的分析入口:作为统一的分析引擎,StarRocks消除了多系统间的数据搬运需求,用户可以在一个系统内完成从原始数据到最终分析的全过程。
高性能计算引擎降低资源消耗
StarRocks的高性能计算引擎使ETL过程更加高效:
- 向量化执行引擎:StarRocks采用全面向量化的执行引擎,充分利用现代CPU的SIMD指令集,大幅提升数据处理效率,同等硬件条件下处理速度提升5-10倍。
- 智能查询优化器:StarRocks的CBO优化器能够根据数据特征自动选择最优执行计划,减少不必要的计算和资源消耗。
- 列存与实时更新:基于列存的存储引擎与主键模型的结合,使StarRocks在保持高性能分析能力的同时,支持高频的数据更新,为实时ETL提供了坚实基础。
云原生设计实现弹性扩展
StarRocks的云原生设计为ETL流程提供了前所未有的弹性:
- 存算分离架构:StarRocks 3.0引入的存算分离架构,使计算资源和存储资源可以独立扩展,轻松应对ETL处理中的峰值负载。
- 弹性资源调度:通过资源组管理,StarRocks可以为不同的ETL任务分配适当的资源,确保关键业务的处理优先级。
- 容器化部署支持:完善的Kubernetes集成使StarRocks部署更加灵活,支持按需扩缩容,优化资源使用效率。
这种模式模糊了ETL和ELT的界限,兼具两者的优点:既有ELT的架构简洁性,又通过强大的计算能力和预计算技术,实现了ETL模式下对查询性能的保障,最终帮助企业构建起一套真正面向实时场景的数据分析解决方案。
随着数据量的爆炸性增长和实时分析需求的日益迫切,传统ETL流程已无法满足现代企业的需求。StarRocks作为新一代实时分析数据库,通过创新技术重塑了ETL流程,为企业提供了显著价值:
- 极致性能:向量化执行引擎和智能优化器使ETL处理速度提升10倍以上,满足实时分析需求。
- 架构简化:湖仓一体架构显著减少了系统组件数量和数据流转环节,降低了复杂度和成本。
- 灵活多变:多种导入方式和强大的SQL能力,使StarRocks能够适应各类ETL场景,从实时流处理到批量历史数据加工。
- 弹性扩展:云原生设计和存算分离架构使系统能够根据负载弹性扩缩,优化资源使用效率。
- 开放生态:与Hadoop、Spark、Flink等开源生态的深度集成,使企业能够平滑迁移和渐进式采用。
未来,随着ETL与AI的深度融合,StarRocks将继续创新,为企业提供更智能、更高效的数据处理解决方案,助力企业在数据驱动的时代保持竞争优势。


