

实时数据仓库:现代企业数据分析的关键基础设施
本文发表于: &{ new Date(1756396800000).toLocaleDateString() }
实时数据仓库的本质与演进
实时数据仓库代表着数据处理技术的重要演进,它突破了传统批处理模式的时间限制,实现数据的即时摄取、存储和分析。与传统数据仓库需要等待定时ETL任务完成不同,实时数据仓库能够在数据产生的瞬间就开始处理,将数据延迟从小时级降低到秒级甚至毫秒级。这种转变不仅仅是技术上的改进,更是对业务响应速度和决策效率的根本性提升。

现代应用系统产生的数据具有高频率、高并发、多样化的特征,包括用户行为数据、物联网传感器数据、金融交易数据等。这些数据的价值往往具有时效性,错过处理的黄金时间窗口,数据的商业价值就会大幅降低。实时数据仓库正是为了捕获和利用这些瞬时价值而设计的现代化数据基础设施。
.PNG)
核心技术架构与关键特性
流式数据摄取与处理
实时数据仓库的核心在于其流式数据处理能力。系统通过与Kafka、Pulsar等消息队列技术的深度集成,实现数据的持续摄取。数据从源系统产生后,无需等待批处理窗口,直接通过流式管道进入数据仓库。这种架构设计确保了数据的新鲜度,使分析结果能够反映业务的实时状态。
流式处理不仅体现在数据摄取层面,还扩展到数据转换和计算过程。实时数据仓库支持增量计算模式,当新数据到达时,系统只需处理增量部分,而不是重新计算整个数据集。这种设计大幅提高了处理效率,降低了计算资源消耗,使大规模实时分析成为可能。
高并发查询与低延迟响应
现代实时数据仓库必须支持高并发查询场景,特别是面向用户的实时应用。系统需要同时服务数千甚至数万个并发查询请求,每个查询都要求在秒级甚至亚秒级时间内返回结果。为实现这一目标,实时数据仓库采用了多项创新技术,包括列式存储、智能索引、查询优化器等。
.PNG)
列式存储格式天然适合分析型查询,能够显著减少IO操作和内存使用。配合压缩技术,不仅节省存储空间,还提升了数据传输效率。智能索引技术,如倒排索引、布隆过滤器等,能够快速定位目标数据,避免全表扫描,大幅缩短查询响应时间。
StarRocks:新一代实时分析型数据库
StarRocks作为专为实时分析场景设计的MPP数据库,在实时数据仓库建设中发挥着重要作用。其原生的流批一体处理能力,能够无缝整合实时流数据和历史批量数据,为企业提供统一的分析视图。StarRocks采用了Share-Nothing架构,通过水平扩展实现性能的线性提升,满足不同规模企业的分析需求。
在数据摄取方面,StarRocks支持多种实时数据源,包括Kafka、Flink、Spark Streaming等。其独特的主键模型和更新机制,能够处理复杂的实时数据更新场景,如订单状态变更、用户信息修改等。这种能力对于构建实时业务监控和决策系统具有重要意义。
.PNG)
镜舟数据库作为StarRocks的企业版,在开源版本基础上提供了更多企业级特性,包括多租户管理、细粒度权限控制、高可用性保障等。这些特性使企业能够更安全、更稳定地运行生产级实时数据仓库,满足严格的业务连续性要求。
实践案例:构建智能化实时分析平台
滴滴的实时数据洞察实践
滴滴作为出行服务提供商,面临着海量实时数据的处理挑战。网约车业务产生的订单数据、轨迹数据、司机状态数据等具有高频率、高并发的特点,需要实时分析以支持调度决策、风控监测、业务监控等关键场景。
滴滴基于StarRocks构建的实时数据仓库,成功解决了高并发精确去重的技术难题。在网约车实时看板中,需要对海量用户行为数据进行实时去重统计,传统方案在高并发场景下性能急剧下降。通过StarRocks的物化视图技术,滴滴实现了增量计算和查询加速的完美结合。物化视图能够预先计算并存储复杂聚合结果,当查询到达时直接返回预计算结果,将查询响应时间从分钟级降低到秒级。
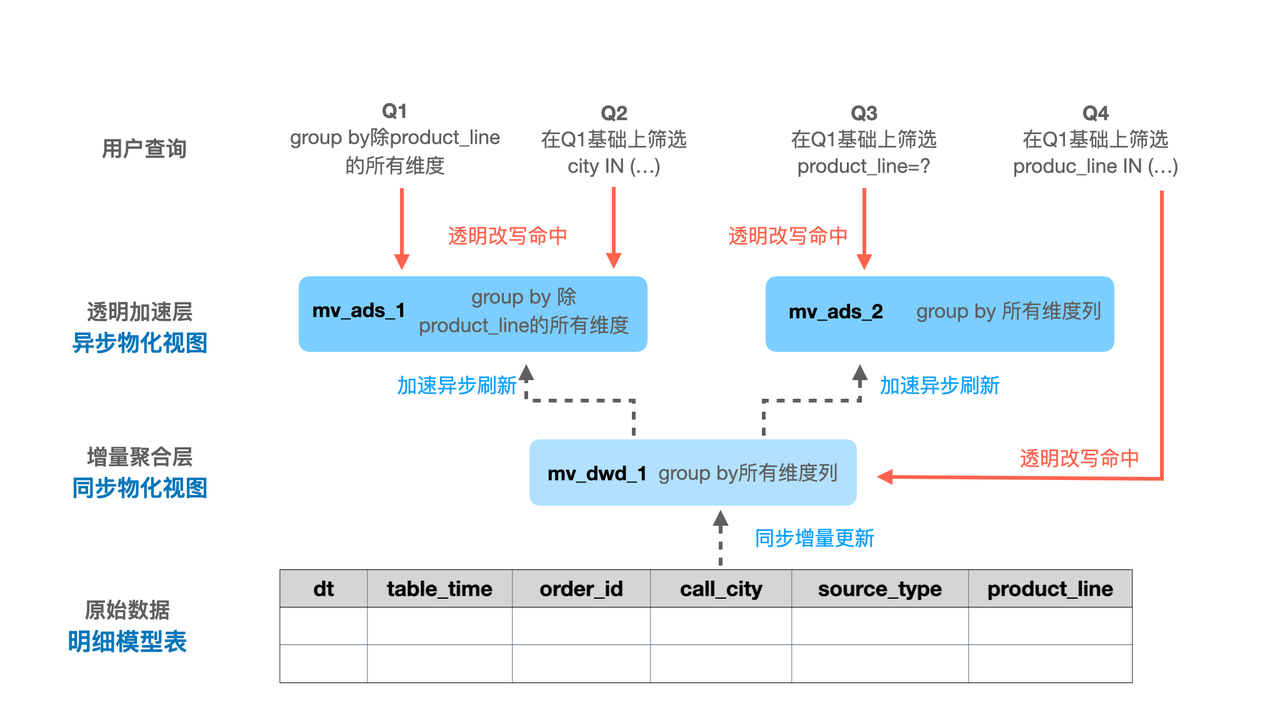
这一实践案例的成功,不仅提升了业务决策的及时性,还显著降低了系统资源消耗。滴滴的技术团队发现,通过合理设计物化视图策略,能够在保证查询性能的同时,将计算资源使用效率提升数倍。这种优化效果直接转化为运营成本的降低和用户体验的改善。


