

ClickHouse 是什么?高性能列式数据库全面解析(vs StarRocks)
本文发表于: &{ new Date(1753372800000).toLocaleDateString() }
ClickHouse 简介:为实时分析而生的高性能数据库
ClickHouse 是一款开源的列式数据库管理系统(DBMS),专为 OLAP(在线分析处理)场景设计。它由俄罗斯搜索巨头 Yandex 开发并于 2016 年开源,如今已成为高性能数据分析领域的重要玩家。ClickHouse 提供开源软件和云服务两种使用方式,让企业可以根据自身需求灵活选择部署模式。
作为一款专注于分析场景的数据库,ClickHouse 能够处理海量数据集,支持复杂 SQL 查询,并在毫秒级别返回结果。这种极速的查询性能使其成为实时分析、大规模日志处理、时序数据分析等场景的理想选择。
什么是分析型数据库?OLAP 与 OLTP 的关键区别
在深入了解 ClickHouse 之前,我们需要先理解分析型数据库的定位。数据库系统通常分为两大类:OLTP(联机事务处理)和 OLAP(联机分析处理)。

OLTP 系统主要处理日常事务操作,如订单创建、库存更新等,特点是高并发、小批量数据读写,通常只涉及少量记录。典型的 OLTP 数据库包括 MySQL、PostgreSQL 等。
而 OLAP 系统则专注于复杂的分析查询,通常需要处理海量历史数据,执行聚合、过滤、连接等复杂操作,为业务决策提供支持。ClickHouse 正是一款专为 OLAP 场景优化的数据库系统。
OLAP 查询的特点:
- 需要处理大量数据(通常是数十亿到数万亿行)
- 查询涉及复杂计算(如聚合、字符串处理、算术运算)
- 对实时性有较高要求(秒级甚至亚秒级响应)
ClickHouse 核心技术:列式存储
ClickHouse 最显著的技术特点是其列式存储架构。与传统的行式存储相比,列式存储在分析场景下具有显著优势。
行式存储 vs 列式存储:根本性的设计差异
在行式数据库中,表的数据是按行连续存储的。这种存储方式适合快速检索和更新单条记录,因为一行中的所有列数据都存储在一起。然而,当需要分析大量数据时,这种存储方式会导致大量不必要的 I/O 操作,因为即使查询只需要少数几列,系统也必须读取整行数据。
相比之下,列式数据库如 ClickHouse 将每一列的数据连续存储在一起。这种设计在分析场景下有显著优势:
- 减少 I/O 开销:分析查询通常只涉及少数几列,列式存储允许数据库只读取查询所需的列,大幅减少 I/O 操作。
- 更高的压缩率:同一列的数据通常具有相似性,这使得列式存储能够实现更高效的数据压缩,进一步减少存储空间和 I/O 需求。
- 向量化处理:列式存储天然适合向量化执行,可以充分利用现代 CPU 的 SIMD 指令集,提高计算效率。
.PNG)
以一个实际例子说明:假设有一个包含 100 列的表,而分析查询只需要其中 3 列。在行式数据库中,系统需要读取全部 100 列的数据;而在 ClickHouse 这样的列式数据库中,只需读取 3 列数据,I/O 量减少了 97%。
ClickHouse 官方文档中提供了一个真实世界的例子:对包含 1 亿行的网络分析数据执行查询,ClickHouse 能够在 92 毫秒内处理完毕,相当于每秒处理超过 10 亿行数据,或每秒传输近 7GB 数据。这种性能在传统行式数据库中几乎不可能实现。
ClickHouse 架构:为极速分析而生的设计哲学
ClickHouse 的架构设计充分体现了其对分析性能的极致追求。作为一个分布式系统,ClickHouse 可以部署在单机上,也可以扩展到包含数百甚至数千个节点的集群。
分布式架构与水平扩展
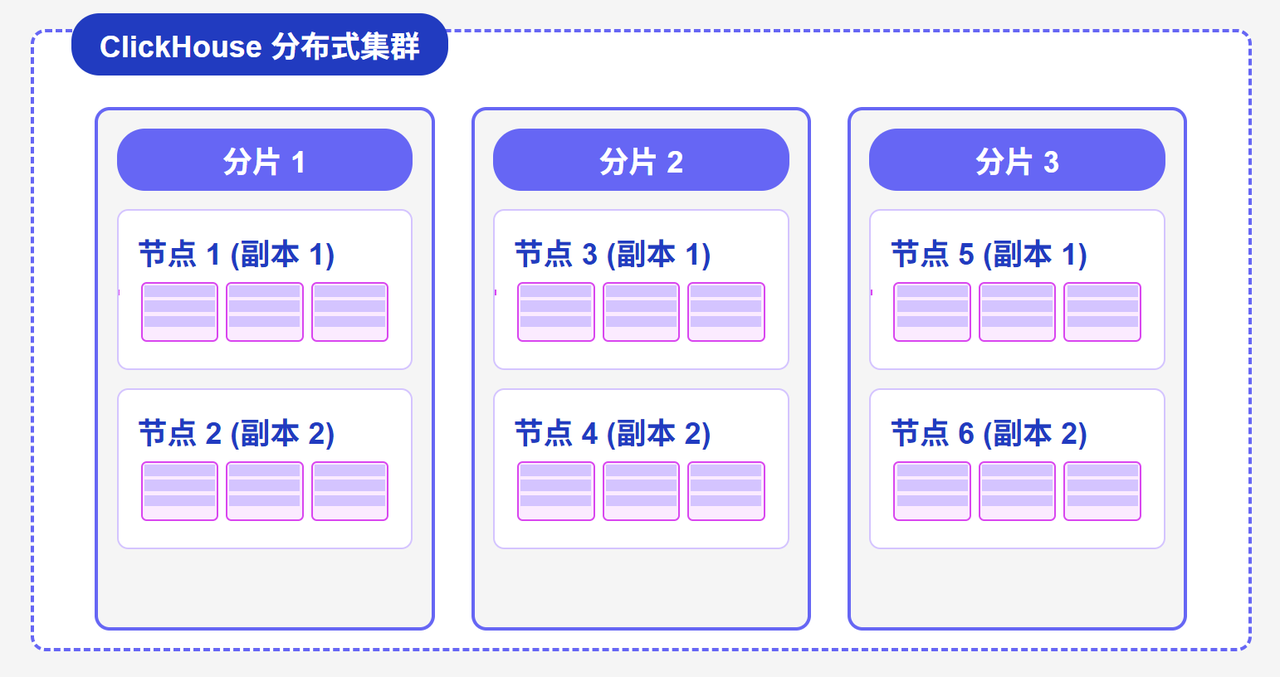
ClickHouse 采用 shared-nothing 架构,每个节点独立工作,通过网络协同完成查询。这种设计使得 ClickHouse 能够线性扩展:随着节点数量的增加,系统的整体性能几乎呈线性增长。
在 ClickHouse 集群中,数据通常按照分片键水平分片到不同节点,每个分片可以有多个副本以保证高可用性。查询时,系统会将查询分发到相关分片,并行执行后合并结果,大大提高了查询效率。
列式存储引擎
ClickHouse 的核心是其高效的列式存储引擎。除了基本的列式存储外,ClickHouse 还实现了多种优化:
- 数据压缩:ClickHouse 对每列数据使用专门的压缩算法,根据数据特性自动选择最优压缩方法,大幅减少存储空间和 I/O 开销。
- 向量化执行:查询执行过程中,ClickHouse 以列块(column blocks)为单位处理数据,充分利用 CPU 缓存和 SIMD 指令,显著提升计算效率。
- 物化视图:ClickHouse 支持物化视图,可以预计算和存储常用查询结果,进一步加速分析查询。
- 多种表引擎:ClickHouse 提供多种专用表引擎,如 MergeTree 系列引擎适合通用分析场景,ReplacingMergeTree 支持数据去重,AggregatingMergeTree 适合预聚合等。
ClickHouse vs StarRocks:如何选择高性能 OLAP 引擎
在选择分析型数据库时,ClickHouse 和 StarRocks 都是备受关注的选项。作为两款领先的 OLAP 引擎,它们各有优势,适合不同的使用场景。
架构与设计理念对比
ClickHouse 和 StarRocks 都采用列式存储架构,但在具体实现上有所不同:
- ClickHouse:采用 shared-nothing 架构,每个节点独立工作,通过网络协同完成查询。这种设计使得 ClickHouse 在单机性能上表现出色,但在复杂查询的分布式执行上可能面临挑战。
- StarRocks:采用 MPP(大规模并行处理)架构,内置分布式查询优化器,能够更智能地处理复杂查询,特别是多表关联查询。StarRocks 还支持存算分离架构,可以更灵活地扩展计算和存储资源。
性能对比
根据多项基准测试,两款产品在不同场景下各有优势:
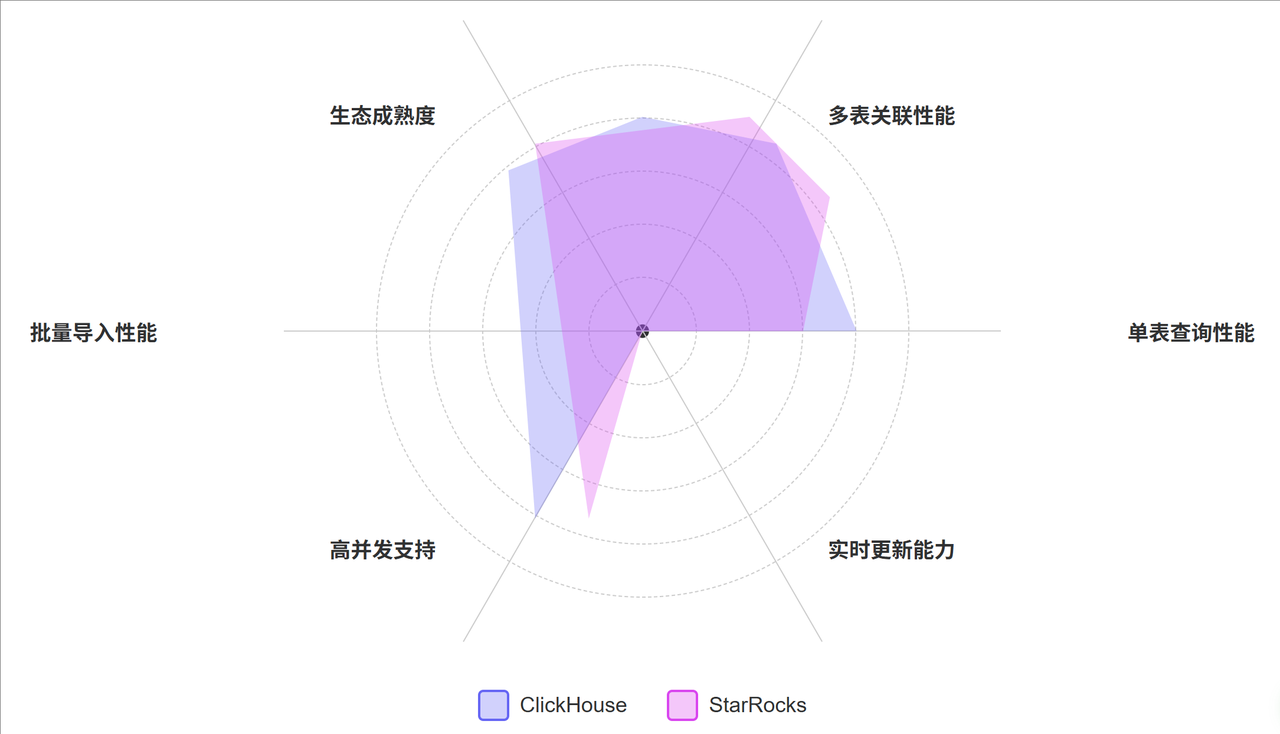
- 单表查询:在简单的单表聚合查询上,ClickHouse 和 StarRocks 都表现出色,通常能达到亚秒级响应。
- 多表关联:在复杂的多表 JOIN 查询上,StarRocks 通常表现更好,其优化器能够生成更高效的执行计划。
- 高并发场景:StarRocks 在高并发查询场景下通常有更好的稳定性和资源隔离能力。
- 实时更新:StarRocks 的主键模型支持更高效的实时更新,而 ClickHouse 主要针对追加写入场景优化。
生态与集成能力
- ClickHouse:作为较早开源的项目,ClickHouse 拥有广泛的社区支持和丰富的工具生态,与各种数据源和 BI 工具有良好的集成。
- StarRocks:近年来发展迅速,特别在湖仓一体方面投入较多,与 Iceberg、Hudi、Paimon 等数据湖格式有深度集成,适合构建现代数据架构。
适用场景建议
- 选择 ClickHouse 的场景:
- 日志分析和事件数据处理
- 需要高吞吐的追加写入场景
- 单表或简单关联的分析查询
- 对开源社区和生态系统成熟度有较高要求
- 选择 StarRocks 的场景:
- 需要频繁更新数据的实时分析
- 复杂的多表关联查询
- 构建湖仓一体架构
- 需要支持高并发查询的场景
结论:选择适合业务的高性能分析引擎
ClickHouse 作为一款高性能列式数据库,在大规模数据分析领域展现出强大实力。它的列式存储架构、向量化执行引擎和丰富的优化技术,使其能够处理数十亿甚至数万亿行数据,并提供毫秒级的查询响应。
然而,技术选型不应仅仅基于性能指标,还需要考虑业务需求、团队技能、生态系统和长期发展等多方面因素。在选择分析引擎时,建议:
- 明确业务需求:分析业务场景数据量、查询模式、实时性要求和预算约束。
- 进行概念验证:使用真实数据和查询进行测试,评估性能和可用性。
- 考虑总体拥有成本:包括硬件、许可、运维和培训成本。
- 评估生态系统:考虑与现有数据基础设施的集成能力。
- 关注社区活跃度:活跃的社区意味着更多的资源、更快的问题解决和更长久的支持。
无论选择 ClickHouse、StarRocks 还是其他分析引擎,重要的是选择最适合特定需求的解决方案。在数据驱动决策日益重要的今天,高性能分析引擎已成为企业数字化转型的关键基础设施。


